介绍
TT-Metal 全称 TT Metalium,是一个面向异构 CPU 和 Tenstorrent 设备集合的底层软件平台,它使用户能够直接访问 RISC-V 处理器、片上网络(NoC),以及 Tensix Core 中的矩阵和向量计算引擎。对于那些希望定制模型、开发新模型,甚至执行非机器学习代码的开发人员来说,TT-Metal 提供了极大的灵活性。平台中没有任何黑盒操作、加密的 API 或隐藏的功能,确保了开发过程的透明性和可控性。
TT-Metal 整体架构
下图展示了Tenstorrent 基于 TT-Metal 构建的软件栈。通过 TT-Metal,开发者可以编写主机驱动程序和核函数,用以实现特定的数学运算(例如,矩阵乘法、图像缩放等),然后将它们打包成库。使用这些库作为构建模块,框架为用户提供了一个灵活的高级环境,用户可以在其中开发各种高性能计算(HPC)和机器学习(ML)应用程序。

TT-Metal 编程模式
异构 AI 加速器编程模式
在异构 AI 加速器的编程中,我们通常会区分两种核心接口:Host 接口和 Device 接口。这种区分对于编程流程至关重要,每种接口承担着不同的职责,并在各自的执行环境中发挥作用。
-
Host 接口:
-
定义:Host 接口主要负责主机端(CPU)的内存管理、资源分配、任务调度和数据传输等操作。
-
功能:处理与设备(如 GPU 或其他 AI 加速器)的通信,包括数据的发送和接收,以及确保数据在 Host 和 Device 之间安全、高效地移动。
-
-
Device 接口:
-
定义:Device 接口则专注于在设备端执行实际的计算任务,即执行核函数(Kernel)。
-
功能:它直接与硬件交互,利用设备的计算能力来加速 AI 算法和处理数据。
-
-
编程模式:
-
内存管理:通过 Host 接口管理 Host 和 Device 的内存。
-
数据准备:在 Host 端准备输入数据,并使用 Host 接口将其传输到 Device 内存。
-
内核配置:在 Device 端配置计算内核的参数和执行环境。
-
执行计算:通过 Device 接口启动计算内核,执行并行计算任务。
-
数据同步:确保计算结果从 Device 同步回 Host,可能涉及等待设备完成计算。
-
结果处理:在 Host 端接收结果数据,并进行后续处理或分析。
-
TT-Metal 编程模式
TT-Metal 基本上遵循了异构 AI 加速器的编程模式,尽管在硬件细节上存在少许差异 (主要表现在核函数的调用上).
在深入探讨 TT-Metal 的编程模式之前,我们首先需要回顾一下相关的硬件基础知识。
Tenstorrent 硬件架构
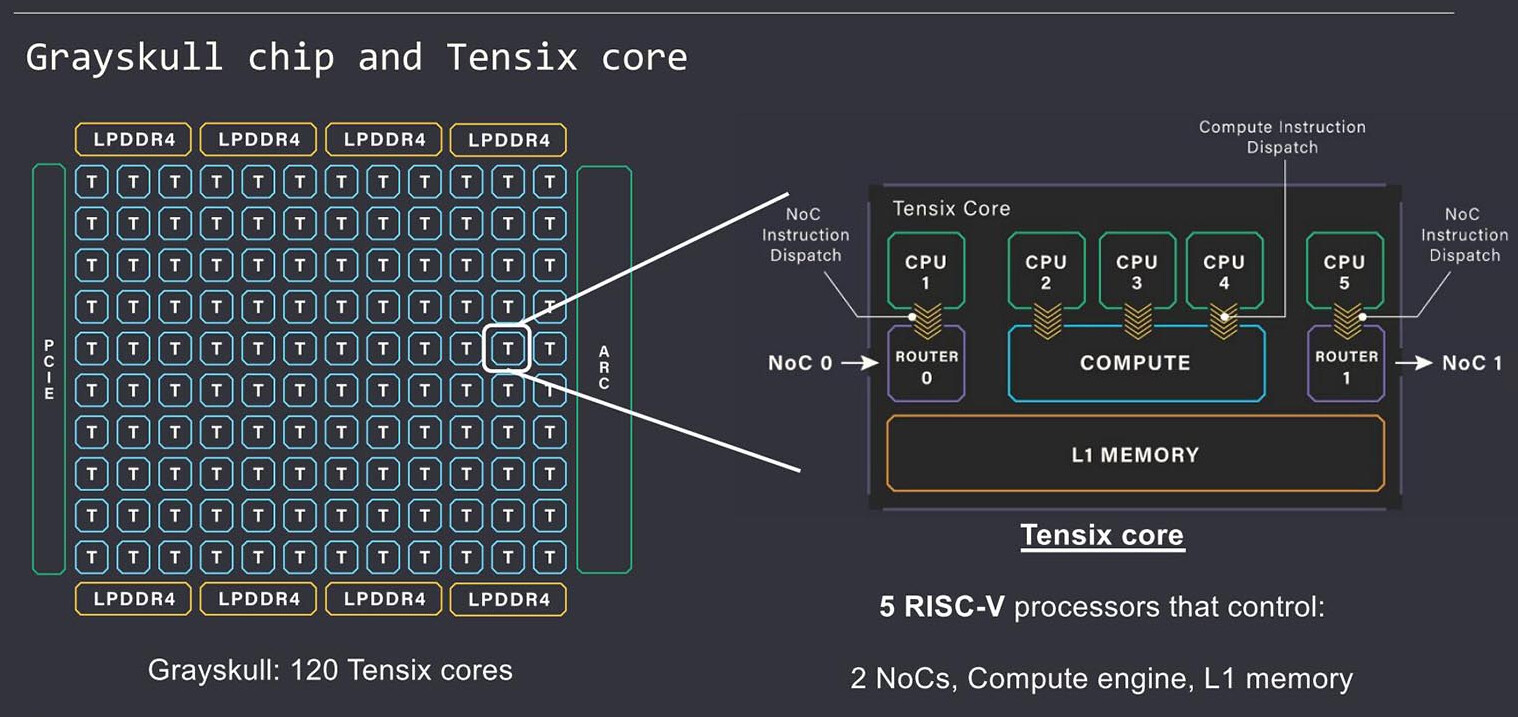
如上图所示,Grayskull(Wormhole)是一个由 Tensix 核心构成的网状结构,每个 Tensix 核心配备了五个独立的 RISC-V 小型核心。其中,CPU1 和 CPU5 负责管理 NOC(网络芯片)硬件以实现数据传输,而 CPU2、CPU3 和 CPU4 则承担计算任务。
内存架构
Tenstorrent 内存架构分为两层,所有 Tensix core 共享的 DRAM,以及每个 Tensix core 独享的 SRAM。后文提及的 DRAM buffer 和 SRAM buffer 指的是从共享的 DRAM 和独享的 SRAM 分配的 buffer。
TT-Metal 核函数
在 TT-Metal 架构中,每个 RISC-V CPU 都需要通过手动编写核函数来实现控制。核函数根据其功能被划分为以下几类:
-
Data movement kernel:负责数据的传输,具体分为两种类型:
-
Reader kernel:从 Buffer(Buffer 是 DRAM buffer 或者其他 Tensix core 的 SRAM buffer) 读取数据到本地 SRAM。
-
Writer kernel:将数据从本地 SRAM 写入回 Buffer。
-
-
Compute kernel:负责执行实际的计算任务。
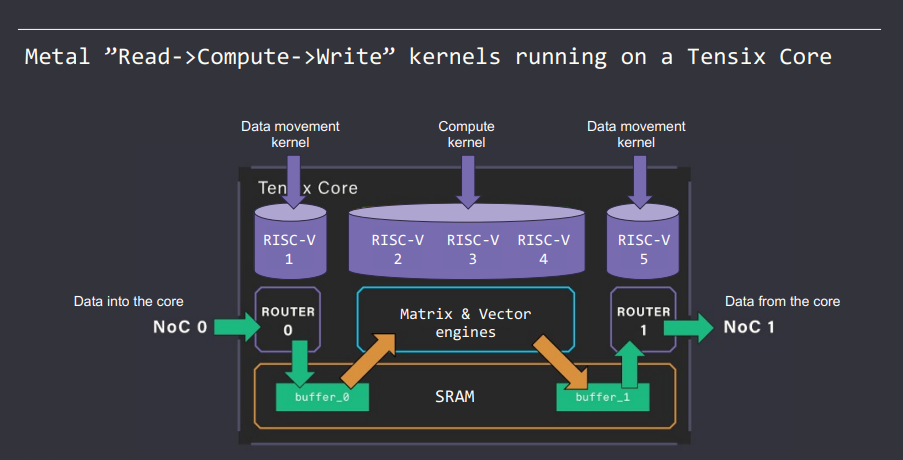
如下图所示,TT-Metal 的核函数调用构建了一个 pipeline,由 Reader kernel、Compute kernel 和 Writer kernel 组成。这个 pipeline 的工作流程是:Reader kernel 首先从 Buffer 提取数据到本地 SRAM,然后 Compute kernel 对数据进行处理,最后 Writer kernel 将结果数据写回 Buffer。
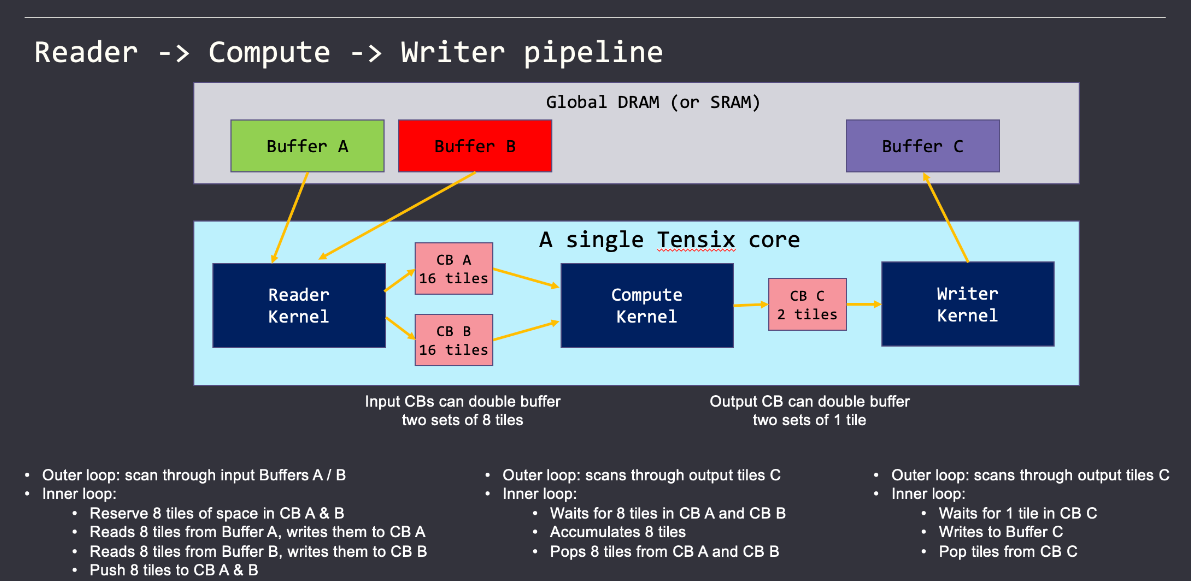
Compute 占用的三个 riscv cpu 分工如下:
-
CPU2:UNPACK 将数据从 SRAM Buffer 拷贝到寄存器 SrcA、SrcB(源寄存器,如下图绿色部分所示)
-
CPU3:调用 Matrix & Vector engines 进行计算
-
CPU4:PACK 将数据从寄存器 dst(目标寄存器) 拷贝到 SRAM Buffer
关于更多关于 Tensix core 的细节见前文 Tenstorrent数据流芯片Grayskull 和 Wormhole解析。
TT-Metal 示例分析
一个典型 tt-metal 简单程序的目录结构如下所示:
example
├── CMakeLists.txt
├── kernels
│ ├── reader.cpp # Reader kernel
│ ├── compute.cpp # Compute kernel
│ └── writer.cpp # Writer kernel
└── example.cpp # host driver
Kernels 和 host 均使用 C++ 进行开发,并且支持到 C++20 标准。开发过程中,通过 TT-Metal host & device api 来实现数据传输和计算。接下来,我们将通过一个简单的示例程序——矩阵乘法(matmul)——来分析这些 API 的使用。
host driver
以下是 TT-Metal 单核矩阵乘示例 host driver 代码的简化版本。
Device *device = CreateDevice(device_id);
CommandQueue& cq = device->command_queue();
Program program{};
CoreRange core({0, 0}, {0, 0});
// create dram & sram buffer
auto src0_dram_buffer = CreateBuffer(dram_config_A);
auto src1_dram_buffer = CreateBuffer(dram_config_B);
auto dst_dram_buffer = CreateBuffer(dram_config_C);
auto cb_src0 = CreateCircularBuffer(program, core, cb_src0_config);
auto cb_src1 = CreateCircularBuffer(program, core, cb_src1_config);
auto cb_output = CreateCircularBuffer(program, core, cb_output_config);
// create kernels
auto reader_id = CreateKernel(
program,
"kernels/dataflow/reader_bmm_8bank.cpp",
core,
tt_metal::DataMovementConfig{.processor = DataMovementProcessor::RISCV_1, .noc = NOC::RISCV_1_default, .compile_args = reader_compile_time_args});
auto writer_id = CreateKernel(
program,
"kernels/dataflow/writer_bmm_8bank.cpp",
core,
tt_metal::DataMovementConfig{.processor = DataMovementProcessor::RISCV_0, .noc = NOC::RISCV_0_default, .compile_args = writer_compile_time_args});
auto matmul_single_core_kernel_id = CreateKernel(
program,
"kernels/compute/bmm.cpp",
core,
tt_metal::ComputeConfig{.math_fidelity = math_fidelity, .compile_args = compute_args}
);
// pass arguments
tt_metal::SetRuntimeArgs(
program, reader_id, core,
{src0_addr, src1_addr, Mt, Kt, Nt, Mt*Kt, Kt*Nt, B, uint32_t(bcast_batch ? 1 : 0)}
);
tt_metal::SetRuntimeArgs(
program, writer_id, core,
{dst_addr, 0, Mt, Kt, Nt, Mt*Kt, Kt*Nt, B}
// enqueue data and program
EnqueueWriteBuffer(cq, src0_dram_buffer, a.data(), false);
EnqueueWriteBuffer(cq, src1_dram_buffer, b.data(), false);
EnqueueProgram(cq, program, false);
EnqueueReadBuffer(cq, dst_dram_buffer, output.data(), true);
CloseDevice(device);
代码可以分为几个部分:
-
初始化设备和关闭:CreateDevice、CloseDevice
-
分配内存
-
CreateBuffer – 创建 DRAM buffer
-
CreateCircularBuffer – 创建 SRAM 环形队列(circular buffer,简称 cb,后文接口中以 cb_ 开头的字符都与 circular buffer 有关)
-
-
创建 kernel:CreateKernel,具体 kernel 的实现在外部文件中
-
reader_bmm_8bank.cpp – Reader kernel
-
writer_bmm_8bank.cpp – Writer kernel
-
bmm.cpp – Compute kernel
-
-
参数传递:SetRuntimeArgs
-
编译和加载:EnqueueProgram
其中,CoreRange core({0, 0}, {0, 0}) 代表了使用的核,由第一个核的坐标和最后一个核的坐标组成,在此表示使用一个核,坐标是 {0, 0}。
Data movement kernel
以下是单核矩阵乘示例 Reader kernel 代码的简化版本。
// src0
const InterleavedAddrGenFast<src0_is_dram> s0 = {
.bank_base_address = src0_addr,
.page_size = src0_tile_bytes,
.data_format = src0_data_format
};
cb_reserve_back(cb_id_in0, onetile);
uint32_t l1_write_addr_in0 = get_write_ptr(cb_id_in0);
noc_async_read_tile(itileA, s0, l1_write_addr_in0);
noc_async_read_barrier();
cb_push_back(cb_id_in0, onetile);
主要使用了 circular buffer 和 data movement 相关的 api。circular buffer 是基于 tile 的 FIFO 队列,它通过两个指针来追踪 buffer 的当前位置。在 Tenstorrent 的设计中,数据传输和计算都是以 tile 为单位进行的,因此 kernel API 大多是针对 tile 来设计的。
src0_addr 是作为参数传入的,它代表 DRAM buffer 的地址。cb_id_in0 是 circular buffer 的索引,利用它可以获取 circular buffer 的地址。
-
cb_reserve_back – 在 circular buffer 中申请一个空闲的 tile
-
get_write_ptr – 通过 circular buffer index 获取 SRAM address
-
noc_async_read_tile – 从 DRAM buffer 传输一个 tile 到 SRAM buffer 中
-
noc_async_read_barrier – 等待 tile 传输完毕
-
cb_push_back – 将传输完毕的 tile push 到队列中(实际上会移动 circular buffer 的指针)
由此可知,Reader/Writer kernel 的主要功能是将数据在外部 buffer(如 DRAM 或其他 Tensix 的 SRAM)与本地 SRAM buffer 之间进行基于 tile 的传输。
Compute kernel
以下是单核矩阵乘示例 Compute kernel 代码的简化版本。
mm_init();
acquire_dst(tt::DstMode::Full);
cb_wait_front(tt::CB::c_in0, onetile);
cb_wait_front(tt::CB::c_in1, onetile);
matmul_tiles(tt::CB::c_in0, tt::CB::c_in1, 0, 0, 0, false);
cb_pop_front(tt::CB::c_in0, onetile);
cb_pop_front(tt::CB::c_in1, onetile);
cb_reserve_back(tt::CB::c_out0, onetile);
pack_tile(0, tt::CB::c_out0);
cb_push_back(tt::CB::c_out0, onetile);
release_dst(tt::DstMode::Full);
void matmul_tiles(uint32_t in0_cb_id, uint32_t in1_cb_id, uint32_t in0_tile_index, uint32_t in1_tile_index, uint32_t idst, const uint32_t transpose) {
UNPACK(( llk_unpack_AB_matmul(in0_cb_id, in1_cb_id, in0_tile_index, in1_tile_index) ));
MATH(( llk_math_matmul<MATH_FIDELITY>(idst, transpose) ));
}
-
mm_init – matmul kernel 封装的函数,主要实现一些初始化
-
acquire_dst、release_dst – 申请和释放 dst 寄存器,dst 寄存器会用于保存 matmul 的结果
-
matmul_tiles – 将数据从 circular buffer 拷贝到 SrcA 和 SrcB 寄存器,然后调用 FPU 指令执行 matmul 计算,结果保存在 dst 寄存器
-
pack_tile – 将数据从 dst 寄存器拷贝到 circular buffer
-
cb_wait_front、cb_pop_front、cb_reserve_back、cb_push_back – cb 操作
可以看到,最终通过调用 Low level kernel 接口来执行计算任务,LLK 相关细节见前文算子的从上而下映射:从算子到自定义指令。
TT-NN
TT-NN 库是专为 Tenstorrent 硬件设计的高级库,用于运行 AI 模型。它基于 TT-Metal API 进行封装,提供了一系列高效的算子,类似于 NVIDIA 硬件上的 cublas(高级线性代数库)。利用 TT-NN 库,用户可以轻松地在 Tenstorrent 硬件上开发和部署 AI 模型,无需直接与底层硬件接口打交道。
TT-NN Operation 列表
TT-NN operation 是用 C++ 实现的一种函数,它封装了 Python 接口供用户使用。这种操作的输入和输出通常是一个或多个 tensor。
| Category | Operations |
|---|---|
| Core | as_tensor, from_torch, to_torch, to_device, from_device, to_layout, dump_tensor, load_tensor, deallocate, reallocate, to_memory_config |
| Tensor Creation | arange, empty, zeros, zeros_like, ones, ones_like, full, full_like |
| Matrix Multiplication | matmul, linear |
| Pointwise Unary | abs, acos, acosh, asin, asinh, atan, atan2, atanh, bitwise_and, bitwise_or, bitwise_xor, bitwise_not, bitwise_left_shift, bitwise_right_shift, cbrt, celu, clip, clone, cos, cosh, deg2rad, digamma, elu, erf, erfc, erfinv, exp, exp2, expm1, floor, ceil, geglu, gelu, glu, hardshrink, hardsigmoid, hardswish, hardtanh, heaviside, hypot, i0, identity, isfinite, isinf, isnan, isneginf, isposinf, leaky_relu, lerp, lgamma, log, log10, log1p, log2, log_sigmoid, logical_not, logit, mish, multigammaln, neg, prelu, reglu, relu, relu_max, relu_min, relu6, remainder, rsqrt, rdiv, rsub, sigmoid, sigmoid_accurate, sign, silu, sin, sinh, softmax, softplus, softshrink, softsign, swish, tan, tanh, signbit, polygamma, rad2deg, reciprocal, sqrt, square, swiglu, tril, triu, tanhshrink, threshold |
| Pointwise Binary | add, multiply, subtract, pow, ldexp, logical_and, logical_or, logical_xor, logaddexp, logaddexp2, xlogy, squared_difference, gtz, ltz, gez, lez, nez, eqz, gt, ge, lt, le, eq, ne, isclose, polyval, nextafter, maximum, minimum, atan2_bw, embedding_bw, addalpha_bw, subalpha_bw, xlogy_bw, hypot_bw, ldexp_bw, logaddexp_bw, logaddexp2_bw, squared_difference_bw, concat_bw, rsub_bw, min_bw, max_bw, lerp_bw |
| Pointwise Ternary | addcdiv, addcmul, mac, where, addcmul_bw, addcdiv_bw, where_bw |
| Losses | l1_loss, mse_loss |
| Reduction | max, mean, min, std, sum, var, argmax, topk |
| Data Movement | concat, pad, permute, reshape, repeat, repeat_interleave |
| Normalization | group_norm, layer_norm, rms_norm |
| Transformer | split_query_key_value_and_split_heads, concatenate_heads, attention_softmax, attention_softmax_, rotary_embedding |
| Embedding | embedding |
| Pooling | global_avg_pool2d, MaxPool2d |
| Vision | upsample |
| KV Cache | fill_cache_for_user_, update_cache_for_token_ |
TT-NN Operation 的实现
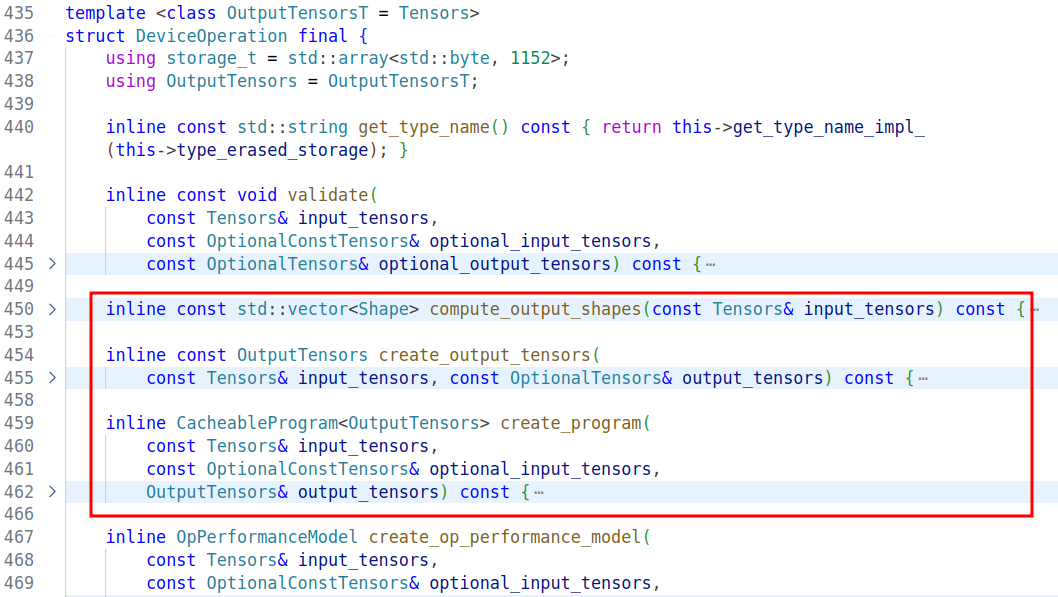
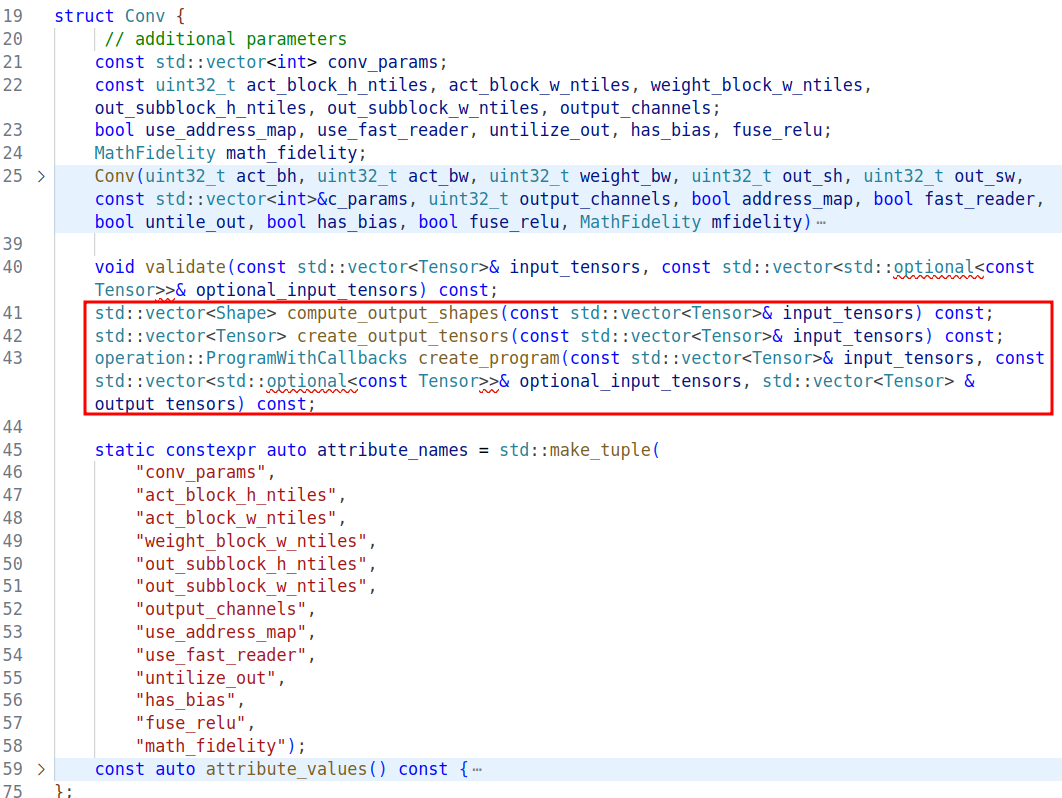
TT-NN Operation 分为 HostOperation、DeviceOperation、ExternalOperation 三种,可以将这三个视为基类(虽然在实现上并没有继承关系),当需要新增一个 Operation 时,需要实现一个类,这个类需要包含一些固定的函数,如下图所示的 compute_output_shapes、create_output_tensors、create_program 等,其中最重要的逻辑在 create_program 中实现。
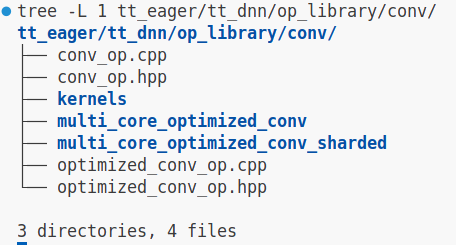
观察 struct Conv 的 create_program 源码,其实现机制与上文中提到的 matmul 算子的 driver 类似。Conv 算子的目录结构如下图所示,其中 *conv_op.cpp 是 driver 部分,而 kernels 文件夹包含了 Reader kernel、Compute kernel 和 Writer kernel。与上文提到的 matmul 实现对比,Conv Operation 的输入和输出是 Tensor,所以输入输出数据需要在 Tensor 和 tile 之间进行转换处理。
使用 C++ 实现 Operation 后,需要调用 ttnn::register_operation 函数来注册 Operation。注册完成后,通过 pybinding 提供 Python 接口,这样用户层就可以方便地使用这些 Operation 了。
Softmax 在 TTNN 上实现
TTNN softmax operation 源码目录结构如下:
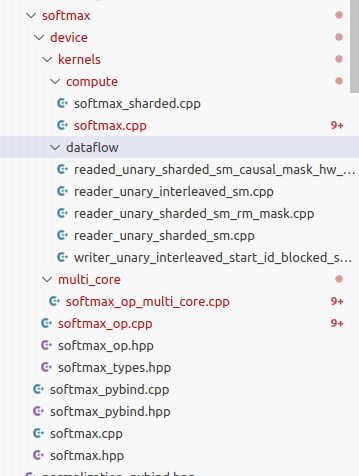
其中,softmax_op.cpp 文件是其入口文件,实现了 create_program 函数,对接 TTNN 库的架构。softmax_op_multi_core.cpp 文件是其 driver 文件,负责创建 buffer 和 kernel 并传递参数。compute & dataflow 目录则是其 compute kernel & data movement kernel 位置所在。
可以看出,TTNN operation 的实现方式和手动调用 TT-Metal 实现算子是一样的。
void scale_mask_softmax_multi_core {
Program program = CreateProgram();
auto [num_cores, all_cores, core_group_1, core_group_2, num_tile_rows_per_core_group_1, num_tile_rows_per_core_group_2]
= tt::tt_metal::split_work_to_cores(grid_size, num_tile_rows, true);
...
CreateCircularBuffer(..);
...
softmax_kernels_id = createKernel(...);
reader_kernels_id = createKernel(...);
writer_kernels_id = createKernel(...);
...
for (auto i = 0; i < num_cores, ++i) {
// set kernel core id
// split input data
}
auto override_runtime_arguments_callback = [](){...}
return program, override_runtime_arguments_callback
}
Driver 的简化逻辑如上所示:会根据物理核心的数量和数据的大小决定使用核心的数量,并且根据 num_cores 划分数据。
Softmax 的 compute kernel 实现和单核 matmul 类似,区别在于,softmax 有多个 circle buffer 存放中间数据,多个算子顺序执行,数据多次在 src0, src1, dst 和 circle buffer 之间移动。(参考文件:tt-metal/ttnn/cpp/ttnn/operations/normalization/softmax/device/kernels/compute/softmax.cpp)
对比于 TT-Buda 的 softmax,Netlist 部分如下所示:
softmax_single_tile:
target_device: 0
input_count: 1
exp: {type: exp, grid_loc: [0, 0], grid_size: [1, 1], inputs: [input_activation ], t: 1, mblock: [1, 1], ublock: [1, 1], in_df: [Float16_b], acc_df: Float16, out_df: Float16_b, intermed_df: Float16_b, ublock_order: r, buf_size_mb: 2, math_fidelity: HiFi3}
sum: {type: matmul, grid_loc: [0, 1], grid_size: [1, 1], inputs: [exp, input_constant], t: 1, mblock: [1, 1], ublock: [1, 1], in_df: [Float16_b, Float16_b], acc_df: Float16, out_df: Float16_b, intermed_df: Float16_b, ublock_order: r, buf_size_mb: 2, math_fidelity: HiFi3, attributes: {m_k: 1, u_kt: 1}}
recip: {type: reciprocal, grid_loc: [0, 2], grid_size: [1, 1], inputs: [sum ], t: 1, mblock: [1, 1], ublock: [1, 1], in_df: [Float16_b], acc_df: Float16, out_df: Float16_b, intermed_df: Float16_b, ublock_order: r, buf_size_mb: 2, math_fidelity: HiFi3}
mult: {type: multiply, grid_loc: [0, 3], grid_size: [1, 1], inputs: [exp, recip ], t: 1, mblock: [1, 1], ublock: [1, 1], in_df: [Float16_b, Float16_b], acc_df: Float16, out_df: Float16_b, intermed_df: Float16_b, ublock_order: r, buf_size_mb: 2, math_fidelity: HiFi3}
可以看出 softmax 由四个算子组成,使用了四个 core,数据在四个 core 之间流动。而 TTNN 的 softmax 则是将数据进行切分,在多个 core 上并行处理数据,并不是 dataflow 的形式。
每个 TTNN 的 op 都会重新分配 tensix core,单个 op 内部可以通过 data movement kernel 进行数据传输(手动管理),执行的时候,需要再执行完一个 TTNN op 之后,才可以执行下一个。
理论上,可以将模型封装成一个 TTNN op 的形式,手动分配 tensix core,并进行数据移动的管理,但是复杂度过大。如果只是使用现有的 TTNN op 去实现模型,模型并不是以 dataflow 的形式运行的,而且 op by op 的执行方式很难发挥出芯片的性能。
TT-NN 示例
以下是使用 TT-NN 库,在设备上运行 exp 操作的示例:
import torch
import ttnn
device_id = 0
device = ttnn.open_device(device_id=device_id) # 打开设备
torch_input_tensor = torch.rand(2, 4, dtype=torch.float32) # 生成数据
input_tensor = ttnn.from_torch(torch_input_tensor, dtype=ttnn.bfloat16, layout=ttnn.TILE_LAYOUT, device=device) # 转换 tensor 格式
output_tensor = ttnn.exp(input_tensor) # 计算
torch_output_tensor = ttnn.to_torch(output_tensor) # 转换 tensor 格式
ttnn.close_device(device) # 关闭设备
如上所示,用户只需调用 TT-NN 库提供的接口,便能完成算子的执行。这种方法确实比直接使用 TT-Metal API 手写 driver 和三个 kernel 要简化许多。在 Tenstorrent 的架构中,计算和数据传输都是基于 tile 的方式进行。AI 模型通常使用 tensor 作为数据结构,为了便于对 tensor 进行切割和填充以适应 tiled-base 的处理,ttnn 定义了自己的 tensor 类型。Operations 默认使用 ttnn.tensor,因此在实际使用过程中,需要在 ttnn.tensor 和 PyTorch 的 torch.tensor 之间进行转换,以确保数据能够正确地在 Tenstorrent 硬件上执行计算。
AI 模型的支持
前文提到,tt-buda 支持模型的方式是通过将现有模型进行转换来实现的。而在使用 TT-Metal 的情况下,开发者则需要手动完成一些额外的工作。
模型支持的方式
TT-NN 的设计借鉴了 PyTorch 的接口风格,这为模型支持提供了一种思路,即从 PyTorch 模型出发,逐步替换为 TT-NN operation。以下是实现这一思路的具体步骤:
-
重写 PyTorch 模型:首先使用 PyTorch 的 functional API 将模型重写,确保模型的表达式是函数式的,这有助于后续的替换工作。
-
替换为 TT-NN operations:接着,将重写后的 PyTorch 模型中的 function API 逐步替换为 TT-NN 提供的对应 operations。这一步骤需要确保 TT-NN operations 能够与 PyTorch 的功能相匹配,并且能够在 Tenstorrent 硬件上高效运行。
-
优化:在替换操作完成之后,要进行模型的优化。包括调整 tensor 的布局以适应 tiled-base 的计算模式,优化数据传输路径等优化,以确保模型在 Tenstorrent 硬件上达到最佳性能。
支持的模型
如上图所示,TT-Metal 支持的模型分为两类:一类是已经相对成熟且稳定支持的模型,这些模型被放置在 models/demos 目录下;另一类是仍处于实验阶段,尚未完全支持的模型,它们位于 models/experimental 目录中。正如上文所述,模型移植需要开发者手动进行重写和优化,这是一个相当耗时的过程。TT-Metal 作为一个开源项目,鼓励有兴趣的开发者参与到模型移植的工作中来,并且官方为此提供了现金奖励,以激励社区的参与和贡献。
性能数据
使用 TT-Metal 在 Wormhole 上跑大模型的性能如下图所示:
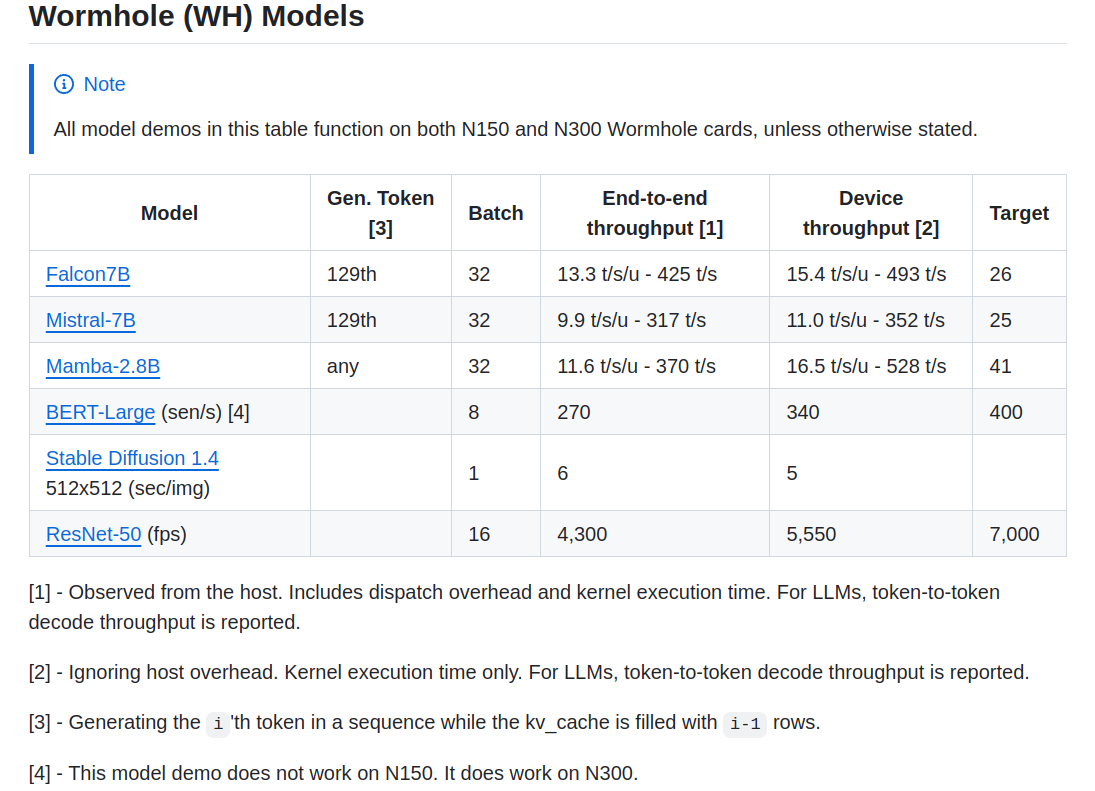
下表是在 Wormhole 单卡上使用 TT-Metal 跑 Falcon7b 模型的数据,throughput 为 456 tokens/s,和官方给出的 493 tokens/s 差距不大。
| step_name | measurement_name | value | step_warm_up_num_iterations | step_start_ts | step_end_ts |
|---|---|---|---|---|---|
| compile_prefill | time(s) | 11.206939 | 2024-07-18T05:57:37+0000 | 2024-07-18T05:57:48+0000 | |
| compile_decode | time(s) | 10.812242 | 2024-07-18T05:57:48+0000 | 2024-07-18T05:57:59+0000 | |
| inference_prefill | tokens/s | 1625.522516175113 | 5 | 2024-07-18T05:58:13+0000 | 2024-07-18T05:58:15+0000 |
| inference_decode | tokens/s | 456.8390978108997 | 10 | 2024-07-18T05:58:15+0000 | 2024-07-18T05:58:17+0000 |
| inference_decode | tokens/s/user | 14.276221806590616 | 10 | 2024-07-18T05:58:15+0000 | 2024-07-18T05:58:17+0000 |
下图显示了 Mistral7b 在 A100 上不同 batch 跑出来的数据。
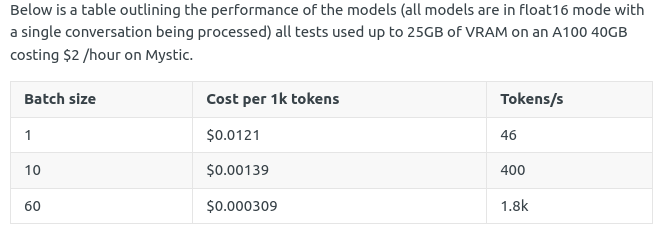
使用 TT-Metal 在单张 Wormhole 卡上跑 Mistral-7B 模型实现了 32 batch 352 t/s 的性能,逊色于 Mistral-7B 模型在 A100 上的性能数据(大概在32 batch 1000 tokens/s左右)。Tenstorrent 芯片可以很方便的多卡互联做横向扩展,性能有进一步提升的空间,关于 Tenstorrent 横向扩展的能力,更详细的信息见前文Tenstorrent数据流芯片Grayskull 和 Wormhole解析
总结
本文介绍了 TT-Metal 软件框架,这是一种专为 Tenstorrent 处理器优化的编程环境,旨在高效开发和部署 AI 模型。文章探讨了 TT-Metal 的架构特点,以及如何使用 API 构建和优化算子。文中还介绍了 TT-NN 库,以及如何使用 TT-NN 进行模型移植。有关接口的详细信息,请参阅官方文档,更多细节和深入分析将在后续文章中阐述。
参考资料
-
TT-Metal 官方文档 Welcome to TT-Metalium documentation! — TT-Metalium documentation
-
TT-NN 官方文档 Welcome to TT-NN documentation! — TT-NN documentation
-
TT-Metal API 接口 APIs — TT-Metalium documentation
-
TT-Metal github 仓库 GitHub - tenstorrent/tt-metal: 🤘 TT-NN operator library, and TT-Metalium low level kernel programming model.