介绍
本文主要探讨 TT-Metal 框架的开发细节,重点包括自定义算子和跨核数据传输同步。为了更好地理解本文内容,读者需要具备一些前置知识,例如 Tenstorrent 硬件的基本原理和 TT-Metal 框架的基本组成结构。建议在阅读本文之前先阅读相关基础资料 Tenstorrent数据流芯片Grayskull 和 Wormhole解析 探索 TT-Metal:Tenstorrent 的 low-level 开发软件栈。
跨核数据传输和同步
数据传输
在 Tenstorrent 卡内部,数据主要通过 NoC(Network-on-Chip)进行传输。调用 NoC 的方式有两种:
-
通过 NoC overlay 硬件控制 NoC
-
通过 RISC-V core 控制 NoC
TT-BUDA 采用第一种方式,通过生成 NoC overlay blob(硬件配置文件)来控制 NoC,具体细节请参考前文深入解析 TT-BUDA 架构及编译执行过程。而 TT-Metal 则采用第二种方式,在核函数代码中手动调用 NoC 接口。以下是 NoC 接口的具体示例:
inline void noc_async_read(std::uint64_t src_noc_addr, std::uint32_t dst_local_l1_addr, std::uint32_t size);
inline void noc_async_write(std::uint32_t src_local_l1_addr, std::uint64_t dst_noc_addr, std::uint32_t size);
上述接口的底层实现是通过写 NoC 寄存器来完成的。
观察接口可以发现,存在两种地址:noc_addr(64位)和l1_addr(32位):
-
l1_addr表示本地地址,用于寻址约 1M 大小的 L1(SRAM),32 位地址已经足够。 -
noc_addr表示全局地址,用于寻址任意 Tensix core 的 L1(SRAM)以及 DRAM 地址。
noc_addr 是由 l1_addr(或者 dram_addr)加上 NoC 坐标信息组成的。获取方式是通过函数 get_noc_addr 来完成的,函数实现如下:
std::uint64_t get_noc_addr(std::uint32_t noc_x, std::uint32_t noc_y, std::uint32_t addr) {
/*
Get an encoding which contains tensix core and address you want to
write to via the noc multicast
*/
return NOC_XY_ADDR(NOC_X(noc_x), NOC_Y(noc_y), addr);
}
在 64 位的 noc_addr 中,后 32 位依然保存 l1_addr(或者 dram_addr),前 32 位保存 NoC 坐标 (noc_x, noc_y)。noc_async_read 和 noc_async_write 接口会将 noc_addr 拆成两部分,分别写入不同的 NoC 寄存器,然后由 NoC 硬件负责在不同的内存之间传输数据。
当 noc_addr 用于表示 DRAM 地址时,虽然 DRAM 不属于某一个 Tensix core,但它有自己的 NoC 坐标,如下图所示:
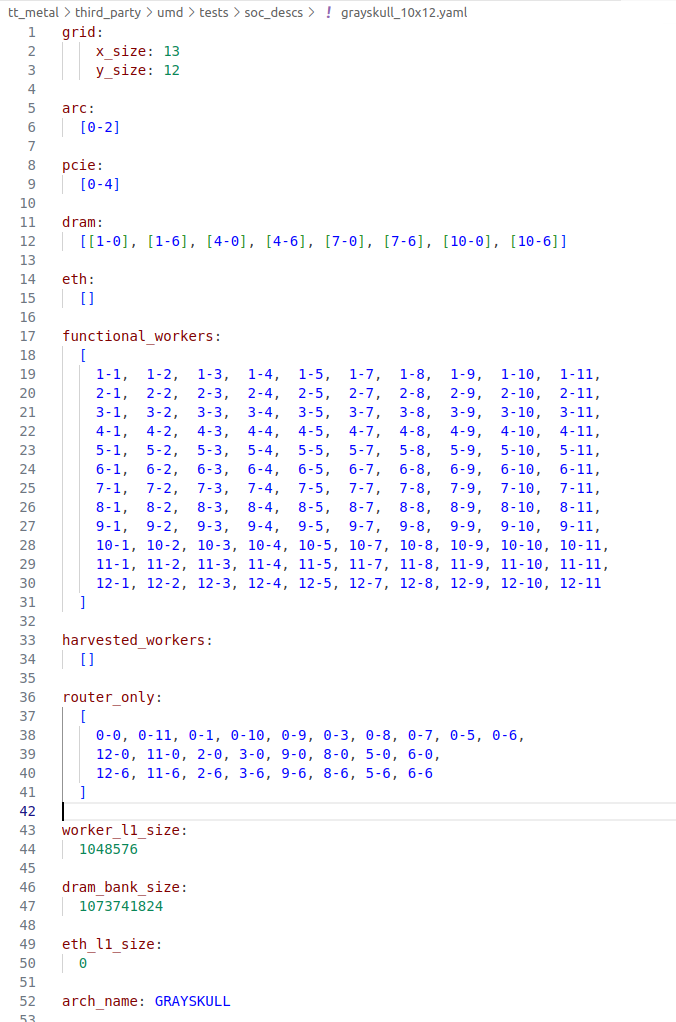
Grayskull 设备配置文件
以上是 Grayskull 的设备配置文件,其中
functional_workers 表示的是计算单元(Tensix core),共有 120 个;dram 表示内存 bank,共有 8 个。Tensix core、DRAM 以及 PCIe 和 ARC(控制 RISC-V CPU)都有各自的 NoC 坐标。
在 探索 TT-Metal:Tenstorrent 的 low-level 开发软件栈 中提到,在 driver 中往往需要指定 kernel 运行在哪个 Tensix core 上。如果需要进行数据传输,则需要从 driver 中将 Tensix core 的坐标传递给 kernel。需要注意的是,driver 中使用的是逻辑坐标,而数据传输使用的是 NoC 坐标。
通过观察 Grayskull 设备配置文件可以发现,Tensix core 的 NoC 坐标是从 (1,1) 开始的,而不是 (0,0)。由此可知,逻辑坐标和 NoC 坐标之间需要进行转换,转换方式如下:
constexpr CoreCoord core0 = {0, 0};
auto core0_physical = device->worker_core_from_logical_core(core0); // 在Grayskull上转换后是 {1,1}
同步
为了确保数据传输过程的正确性,数据传输接口经常搭配同步接口使用。常用的同步接口如下所示:
uint32_t CreateSemaphore(Program &program, const std::variant<CoreRange,CoreRangeSet> &core_spec, uint32_t initial_value, CoreType core_type=CoreType::WORKER);
void noc_semaphore_wait(volatile tt_l1_ptr uint32_t* sem_addr, uint32_t val);
void noc_semaphore_set(volatile tt_l1_ptr uint32_t* sem_addr, uint32_t val);
void noc_semaphore_set_remote(std::uint32_t src_local_l1_addr, std::uint64_t dst_noc_addr);
-
CreateSemaphore – 在 driver 中使用,用于在多个 Tensix core 的 L1(SRAM)的同一个地址上创建 semaphore 变量,并设置初始值(默认为 0)。
-
noc_semaphore_wait – 循环等待本地 L1 semaphore 变为特定值,此处会阻塞
-
noc_semaphore_set – 设置本地 L1 semaphore 为特定值
-
noc_semaphore_set_remote – 将本地 L1 semaphore 的值传递到远程 Tensix core 的 L1,本质上是通过调用
noc_async_write实现跨核数据传输。
数据传输和同步的使用示例如下(由 core0 的 sender 和 core1 的 receiver 组成):
// core0 sender kernel
// 等待 multi receiver ready, 默认是1
noc_semaphore_wait(sender_semaphore_addr_ptr, mcast_num); // 阻塞
noc_semaphore_set(sender_semaphore_addr_ptr, 0);
// wait cb0 ready
cb_wait_front(cb_in0, 1); // 阻塞等待 reader kernel 将数据从 DRAM 拷贝到 circular buffer
// TODO: compute
foo(cb0_addr, size);
// 拷贝 core0 l1 data 到 core1 l1
uint64_t noc_dst_addr = get_noc_addr(dst_noc_x, dst_noc_y, cb0_addr);
noc_async_write(cb0_addr, noc_dst_addr, size);
noc_async_write_barrier();
cb_pop_front(cb_in0, 1);
// 将远程的 receiver semaphore 置1, 告诉 core1 可以进行后续计算
uint64_t receiver_semaphore_noc_addr = get_noc_addr(dst_noc_x, dst_noc_y, receiver_semaphore_addr);
noc_semaphore_set(receiver_semaphore_addr_ptr, 1);
noc_semaphore_set_remote(receiver_semaphore_addr, receiver_semaphore_noc_addr);
// core1 receiver kernel
// 将远程 sender semophore 置1, 告诉 sender 可以开始发送数据
noc_semaphore_set(sender_semaphore_addr_ptr, 1);
uint64_t sender_semaphore_noc_addr = get_noc_addr(src_noc_x, src_noc_y, sender_semaphore_addr);
noc_semaphore_set_remote(sender_semaphore_addr, sender_semaphore_noc_addr);
// 阻塞等待 sender 发送完毕
noc_semaphore_wait(receiver_semaphore_addr_ptr, 1);
noc_semaphore_set(receiver_semaphore_addr_ptr, 0);
// compute
uint32_t cb0_addr = get_write_ptr(tt::CB::c_in0);
foo1(cb0_addr, size);
// 发送数据到 output dram buffer
uint64_t noc_dst_dram_addr = get_noc_addr(dram_dst_noc_x, dram_dst_noc_y, dram_buffer_addr);
noc_async_write(cb0_addr, noc_dst_dram_addr, size);
noc_async_write_barrier();
数据传输一般由发送方(sender)和接收方(receiver)组成,发送方会阻塞等待开始发送信号,接收方会阻塞等待发送完毕信号,信号通过远程修改 semaphore 变量来完成。
自定义算子
回顾前文 算子的从上而下映射:从算子到自定义指令,网表(Netlist)支持的算子可以很容易地使用 TT-Metal 的方法来实现。TT-BUDA 和 TT-Metal 都基于公用的低层次库(low-level kernel)进行了封装,TT-BUDA 封装了 HLK(High-Level Kernel),而 TT-Metal 则封装了 tt_dnn。
SFPU 算子
相对 TT-BUDA 而言,使用 TT-Metal 封装自定义算子更为简便。下面将通过分析一个自定义的 SFPU 算子,介绍自定义算子的实现方法。以下是使用 sfpi API 封装自定义算子的示例,其中通过 SFPU 实现了批量加法:
template <bool APPROXIMATION_MODE, int ITERATIONS = 4>
inline void sfpu_custom_func()
{
for (int d = 0; d < ITERATIONS; d++)
{
vFloat a = dst_reg[0]; // SrcA
vFloat b = dst_reg[16]; // SrcB
dst_reg[0] = a + b;
dst_reg++;
}
}
namespace NAMESPACE {
void MAIN {
uint32_t n_tiles = get_arg_val<uint32_t>(0);
constexpr uint32_t dst_reg0 = 0;
constexpr uint32_t dst_reg1 = 1;
constexpr uint32_t output_dst_index = 0;
binary_op_init_common(tt::CB::c_in0, tt::CB::c_in1, tt::CB::c_out0);
for(uint32_t i = 0; i < n_tiles; i++) {
acquire_dst(tt::DstMode::Full);
cb_wait_front(tt::CB::c_in0, 1); // 等待 cb0
cb_wait_front(tt::CB::c_in1, 1); // 等待 cb1
UNPACK(( llk_unpack_AB_init<BroadcastType::NONE>(tt::CB::c_in0, tt::CB::c_in1) ));
UNPACK(( llk_unpack_AB(tt::CB::c_in0, tt::CB::c_in1, 0, 0) )); // 拷贝 cb0,cb1 到 SrcA, SrcB
MATH(( llk_math_eltwise_unary_datacopy_init<A2D, BroadcastType::NONE, DST_ACCUM_MODE>(false, false, tt::CB::c_in0) ));
MATH(( llk_math_eltwise_unary_datacopy<A2D, BroadcastType::NONE, DST_ACCUM_MODE, UnpackToDestEn>(dst_reg0))); // 拷贝 SrcA 到 dst0
MATH(( llk_math_eltwise_unary_datacopy_init<B2D, BroadcastType::NONE, DST_ACCUM_MODE>(false, false, tt::CB::c_in1) ));
MATH(( llk_math_eltwise_unary_datacopy<B2D, BroadcastType::NONE, DST_ACCUM_MODE, UnpackToDestEn>(dst_reg1))); // 拷贝 SrcB 到 dst1
MATH(llk_math_eltwise_unary_sfpu_0_param<APPROX>
(sfpu_custom_func<APPROX>,
sfpu_custom_func<APPROX>,
output_dst_index, VectorMode::RC);) // 计算,调用自定义 sfpu 函数
cb_reserve_back(tt::CB::c_out0, 1);
// 拷贝 dst 到 output cb
pack_tile(output_dst_index, tt::CB::c_out0);
cb_push_back(tt::CB::c_out0, 1);
cb_pop_front(tt::CB::c_in0, 1);
cb_pop_front(tt::CB::c_in1, 1);
release_dst(tt::DstMode::Half);
}
}
}
上述代码是 Compute kernel 的实现,driver、Reader kernel、Writer kernel 的实现和二元操作(如批量加、矩阵乘)一致,在此不多赘述。值得重点关注的有两个部分,数据移动和 sfpu function 的实现:
-
数据移动
-
cb_wait_front – 等待本地环形缓存(circular buffer,后续简称 cb)数据就绪,Reader kernel 将数据从 DRAM(或者remote L1)拷贝到本地环形缓存(circular buffer,后续简称 cb)
-
llk_unpack_AB – 将数据从 cb 拷贝到 SrcA、SrcB 寄存器(SrcA、SrcB 以及后续的 dst 是寄存器组,用于保存输入输出数据,基于 32*32 的 tile 保存数据,更多硬件相关信息见前文 Tenstorrent数据流芯片Grayskull 和 Wormhole解析)
-
llk_math_eltwise_unary_datacopy – 数据从 SrcA、SrcB 寄存器拷贝到 dst 寄存器
-
pack_tile – 数据从 dst 寄存器拷贝到 output cb,后续 Writer kernel 会将数据从 output cb 拷贝到 DRAM(或者 remote L1)
-
-
sfpu function
-
sfpu 只能从 dst 寄存器读取数据,输出数据也只能写到 dst 寄存器,所以计算之前需要将数据从 SrcA、SrcB 拷贝到 dst
-
FPU 计算是基于 32 * 32 的 tile,所以 llk_unpack_AB、llk_math_eltwise_unary_datacopy 这些数据传输的接口也是基于 32 * 32 的 tile,但是 sfpu dst_reg 访问数据是基于 4 * 16,所以第二份数据的起始地址是 dst_reg[16]。
-
算子融合(fused kernel)
上述示例展示了在单个计算单元(Tensix core)上运行单个算子的情况。然而,在实际应用中,将多个算子在单个计算单元上运行可以减少跨核数据传输的开销。Netlist 提供了一种特殊类型的算子——fused_op,允许将多个算子合并到单个计算单元上。TT-Metal 则可以通过手写 Compute kernel 的方式,将多个算子操作集成到同一个 Compute kernel 中。
以下是 softmax 的 Compute kernel 实现(简化版本,源码位置 tt-metal/ttnn/operations/normalization/softmax/device/kernels/compute/softmax.cpp):
// exp
acquire_dst(tt::DstMode::Half);
cb_wait_front(cb_in0, ndst);
copy_tile(cb_in0, wt8, wt8); // copy from c_in[0] to DST[0]
cb_pop_front(cb_in0, ndst);
cb_reserve_back(cb_exps, ndst);
exp_tile<EXP_APPROX>(wt8); // exp on DST[0]
pack_tile(wt8, cb_exps); // DST[0]->cb_id[wt]
cb_push_back(cb_exps, ndst);
release_dst(tt::DstMode::Half);
// reduce
acquire_dst(tt::DstMode::Half);
cb_reserve_back(cb_recipsumexps, onetile);
cb_wait_front(cb_exps, wt+1); // must be a cumulative wait for correctness
reduce_tile(cb_exps, cb_bcast_scaler, wt, bcast_scaler0, dst0);
// recip
recip_tile(dst0); // DST[0] = 1/sum(exp(x))
pack_tile(dst0, cb_recipsumexps);
cb_push_back(cb_recipsumexps, 1);
release_dst(tt::DstMode::Half);
// multiply
cb_wait_front(cb_recipsumexps, 1); // will reuse Wt times for bcast
acquire_dst(tt::DstMode::Half);
cb_reserve_back(cb_out0, ndst);
mul_tiles_bcast<BroadcastType::COL>(cb_exps, cb_recipsumexps, wt+wt8, 0, wt8); // tile *= 1/(sum(exp(x)))
pack_tile(wt8, cb_out0);
cb_push_back(cb_out0, ndst);
release_dst(tt::DstMode::Half);
cb_pop_front(cb_recipsumexps, 1);
cb_pop_front(cb_exps, Wt);
忽略以 cb_ 开头的 circular buffer 相关操作,以及 copy_tile 和 pack_tile 等数据移动操作,计算操作主要包括 exp_tile、reduce_tile、recip_tile 和 mul_tiles_bcast 四个。可以看出,softmax 操作被拆解为指数计算、规约求和、求倒数和乘法四个算子,这四个算子在一个计算单元上串行执行。
值得注意的是,此处使用了几种不同类型的 circular buffer,如下所示:
-
cb_in0 – 输入数据缓存
-
c_out0 – 输出数据缓存
-
cb_exps、cb_recipsumexps – 中间数据缓存,常用 c_intermed 表示
当一个计算单元上执行多个算子时,中间数据一般放在中间数据缓存中。
对比 Netlist 的 softmax 实现(如前文深入解析 TT-BUDA 架构及编译执行过程所示),上述版本的 softmax 实现是串行执行的,而 Netlist 版本则以数据流(dataflow)的形式执行。结合前面的跨核数据移动和同步内容,上述版本可以改写成数据流格式,需要将四个算子拆分成四个 Compute kernel,然后将数据移动和同步操作放到各自的 Reader kernel 和 Writer kernel 中,手动构建数据流。
由此可以看出 TT-BUDA 和 TT-Metal 的差异。TT-Metal 通过开放低层次接口,将硬件细节完全暴露给开发者,虽然增加了灵活性,但也提高了开发难度。为了减轻开发者的负担,可以考虑将部分工作交给编译器。为此,Tenstorrent 新推出了 TT-MLIR 项目。类似于兆松科技的 MAGIC 项目,TT-MLIR 项目也是基于 MLIR 的编译器项目。后续将推出一期文章介绍 TT-MLIR 项目,敬请期待。
总结
本文主要介绍了 TT-Metal 框架的使用细节,旨在帮助读者加深对 TT-Metal 框架的理解,并为希望使用 TT-Metal 进行开发的人提供一个入门指南。如果想要了解更多关于 TT-Metal 的细节,请查阅官方文档和 TT-Metal 源代码。
参考资料
-
TT-Metal 官方文档 Welcome to TT-Metalium documentation! — TT-Metalium documentation
-
TT-NN 官方文档 Welcome to TT-NN documentation! — TT-NN documentation
-
TT-Metal API 接口 APIs — TT-Metalium documentation
-
TT-Metal github 仓库 GitHub - tenstorrent/tt-metal: 🤘 TT-NN operator library, and TT-Metalium low level kernel programming model.