引言
前文(探索 Tenstorrent 的 AI 开发软件栈:TT-BUDA)介绍了tt-buda的整体架构和frontend部分,本文主要介绍Netlist和backend部分。如下图所示,右半部分内容,重点解析Netlist格式,以及backend如何根据Netlist生成可执行程序和路由文件。
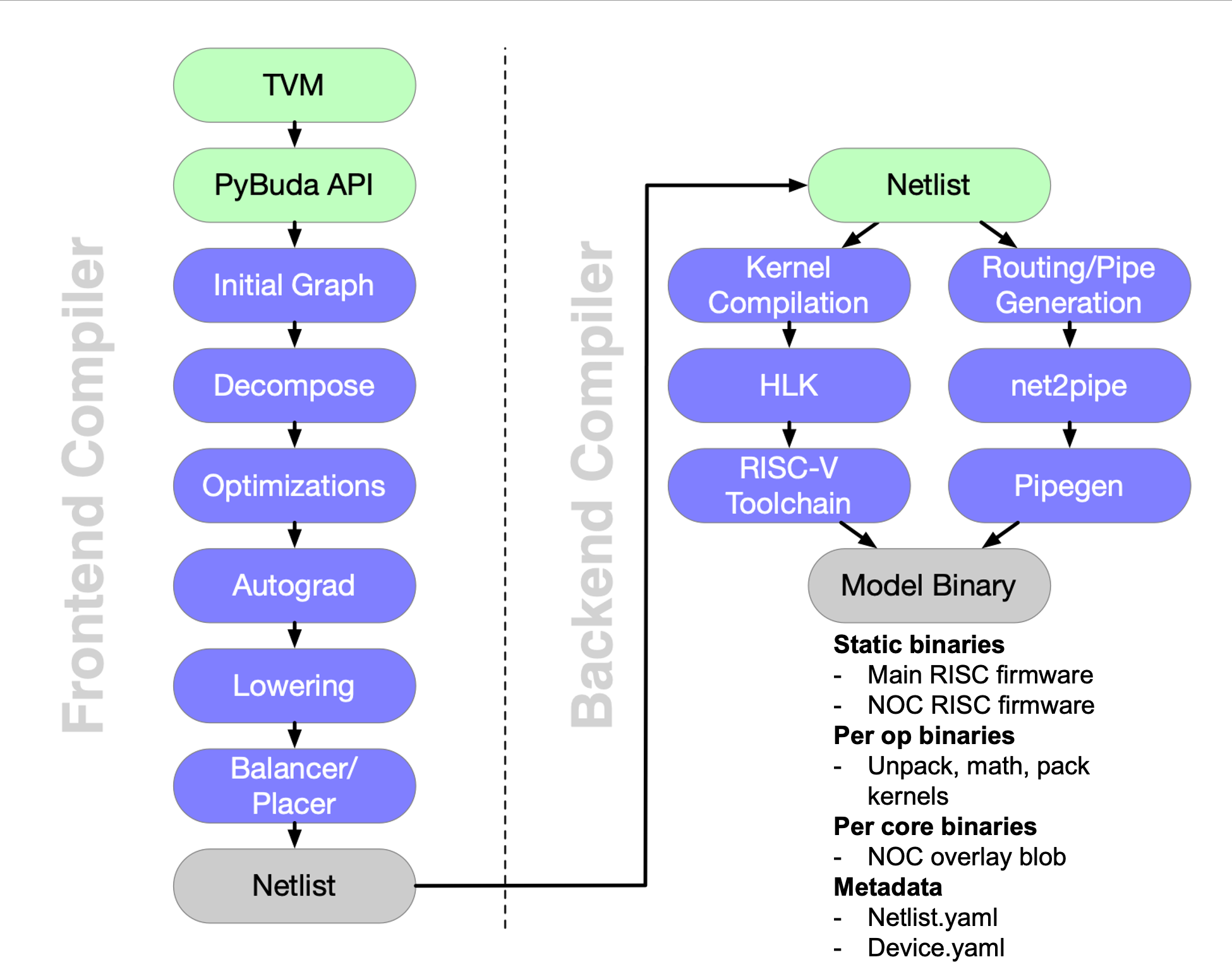
图 1:tt-buda software stack overview(来源:Tenstorrent)
Netlist分析
Netlist作为tt-buda软件栈的中间格式,连接了frontend和backend。frontend会对计算图进行优化,Netlist会包含优化后的图的信息,节点表示为 queue 和 ops,边表示为节点之间的连接。Netlist分成devices、queues、graphs、programs、test-config、fused_ops六个部分,其中,需要重点关心的是queues、graphs和programs。为了对Netlist有个基本的印象,可以先观察一个简单的示例(netlist_softmax_single_tile.yaml):

图 2:Netlist 示例前半部分
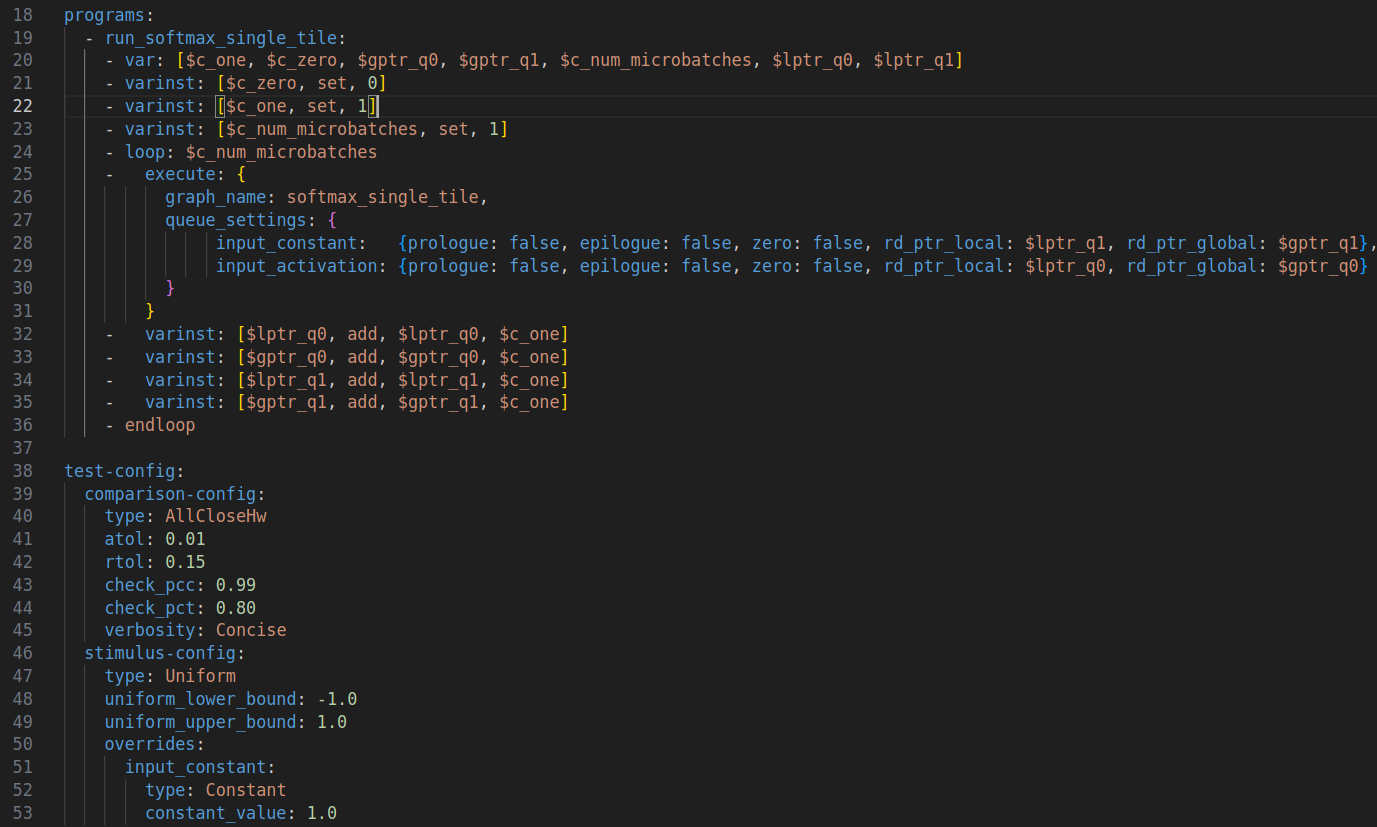
图 3:Netlist 示例后半部分
devices描述了支持的设备,test-config描述测试数据(有了测试数据,就不需要frontend的runtime生成和传输数据到queue,单独的netlist就可以进行测试)。
queues 解析
| 字段 | 描述 |
|---|---|
| input | 队列的生产者,必须是 op 节点或HOST(表示主机CPU)。 |
| type | 队列类型,目前支持 ram(主存)和 queue(带写指针和读指针控制的 FIFO 队列)。 |
| entries | 条目数,通常是graph中input_count的倍数,参数 ram 或常量 queue 的条目数为 1。 |
| grid_size | 数据缓冲区的网格尺寸[rows, cols],每个缓冲区包含 entries 条目。网格中缓冲区总数为 grid_size[0] * grid_size[1],匹配 dram 或 host 中分配的缓冲区数量。 |
| t | 数据的“时间”维度,用于数据的时间流传输。对应tensor的depth维度。每个 t 切片是一个macroblock。 |
| mblock | 每个macroblock包含[rows, cols]个microblocks。 |
| ublock | 每个microblocks包含[rows, cols]个tiles。 |
| ublock_order | microblocks中tile的内存布局顺序,当前支持 r(行优先)或 c(列优先),默认值为 r。 |
| layout | 描述底层内存中的数据布局。默认使用 tilized 布局,用户可以选择 flat 或其他自定义布局。 |
| alias | 仅用于 dual-view IO,将当前 IO 作为指定 IO 的别名。两个视图可以有不同的块方案,但必须有相同的条目大小和相同的底层内存(loc 和 dram/host 地址)。 |
| df | 队列中张量的数据格式,当前支持格式有 Float32、Float16/Float16_b(bfloat16)、RawUInt32/RawUInt16/RawUInt8、Bfp8/Bfp8_b、Bfp4/Bfp4_b、Bfp2/Bfp2_b。 |
| target_device | 队列分配的目标设备 ID,设备内存类型由 loc 指定。 |
| loc | 队列的位置,目前支持 dram 和 host。 |
| dram | 仅当 loc 为 dram 时有效,指定分配 queue/ram 的 dram bank和bank的本地地址。分配的数量和顺序与 grid_size 中的缓冲区数量和顺序匹配(行优先顺序)。 |
| host | 仅当 loc 为 host 时有效,指定分配 queue/ram 的主机地址。分配的数量和顺序与 grid_size 中的缓冲区数量和顺序匹配(行优先顺序)。 |
queue 是FIFO队列,用于保存输入、输出、常量和权重等信息。t(times)、mblock、ublock 是数据传输的三个维度。
graphs 解析
graphs可以包含多个epoch,每个epoch包含多个op。同一个epoch中的ops不可复用tensix,不同的epoch的tensix可能对应不同的op,所以不同的epoch可能需要更换tensix上的可执行文件和路由文件。
op的字段解析如下:
| 字段 | 描述 |
|---|---|
| type | 当前操作的计算类型,用于确定操作所使用的计算内核。每种计算类型支持不同的属性集,不同数量的输入和输出。 |
| grid_loc | 标记网格左上角的坐标位置。网格大小由 grid_size 决定。 |
| grid_size | 分配给当前操作的 Tensix 核心网格[rows, cols]。网格中的核心总数为 grid_size[0] * grid_size[1]。同一图中的两个操作不能共享相同的核心,即不能有重叠的网格。 |
| inputs | 当前操作的输入操作数,必须是 queue/ram 或其他 op。如果输入是另一个 op,则当前操作是输入操作输出的消费者。如果输入是 queue/ram,则当前操作是主动读取器。 |
| input_x_tms | 输入操作数 x 的张量操作(tensor manipulation TM)规范。TM 操作在节点之间通过管道的数据传输路径上实现。管道和实现细节不在网络列表范围内,由 BUDA 后端处理。 |
| input_buf_min_size_tiles | 输入操作数缓冲区的最小大小,以 tile 为单位,如果未指定,由 BUDA 后端确定大小。 |
| t | 数据的“时间”维度,用于数据的时间流传输。对应tensor的depth维度。每个 t 切片是一个macroblock。 |
| mblock | 每个macroblock包含[rows, cols]个microblocks。 |
| ublock | 每个microblocks包含[rows, cols]个tiles。 |
| buf_size_mb | 输出缓冲区的大小,以macroblock为单位,如果未指定,默认值为 1。 |
| ublock_order | microblocks中tile的内存布局顺序,当前支持 r(行优先)或 c(列优先),默认值为 r。 |
| in_df | 输入操作数的数据格式。元素数量与 input 中指定的输入操作数数量匹配。每个元素的数据格式应与其对应的 input 操作数的数据格式匹配。 |
| out_df | 输出操作数的数据格式。每个元素的数据格式应与输出 queue/ram 的或消费者操作数的数据格式匹配。 |
| intermed_df | 中间操作数的数据格式。 |
| acc_df | Tensix 核心数学单元的目标寄存器累加器使用的数据格式。 |
| math_fidelity | 操作的数学精度,精度越高结果越准确,但所需的计算周期也越多。目前支持的精度级别从低到高依次为 LoFi、HiFi2、HiFi3、HiFi4。 |
| attributes | 特定于操作计算 type 的属性映射。 |
| untilize_output | 一个布尔标志,指定是否应取消操作输出的 tiling。如果设置为 true,则所有设备特定的 tiling 和阻塞都将被移除,最终输出与 torch tensor 中的布局相同。这通常用于最终输出回到主机 python/pybuda 运行时。如果未指定,默认值为 false。 |
| grid_transpose | 一个布尔标志,指定操作网格是否应转置。如果设置为 true,操作网格将转置,即行和列互换。如果未指定,默认值为 false。 |
| gradient_op | 一个布尔标志,指定操作是否为梯度累积操作。如果未指定,默认值为 false。 |
其中,grid_loc和grid_size用于描述一个op分配到哪几个Tensix进行运算。
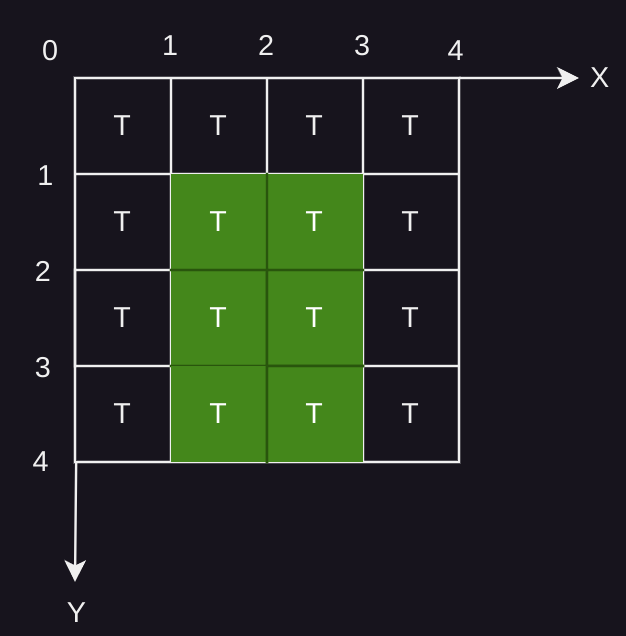
图4: grid_loc: [1,1] 和 grid_size: [2,3] 表示的 Tensix 网格
如图4是一个4x4的Tensix网格,每个网格代表一个Texsix,Tensix 的 grid_loc 为网格左上角的坐标。grid_loc: [1,1] 和 grid_size: [2,3] 表示从坐标[1,1]开始,由[1,1]、[1,2]、[2,1]、[2,2]、[1,3]、[2,3]组成的大小为6的 Tensix 网格, 即绿色的6个网格。
数据的流动
queues 和 ops 都是图的节点,它们之间的数据传输是图的边。如下图所示,数据的流动顺序如下:
- 从 input_activation(dram) 流向 exp(tensix [0,0])
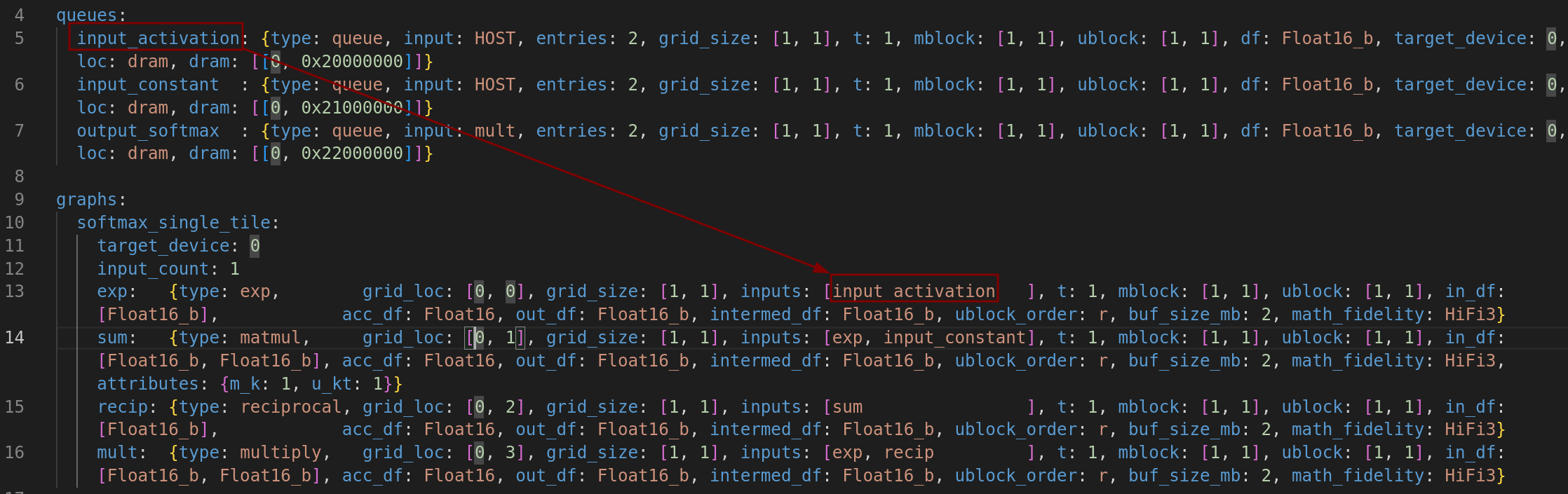
图 5:softmax_single_tile 的数据流动1
- 从 exp(tensix [0,0]) 和 input_constant(dram) 流向 sum(tensix [0,1])
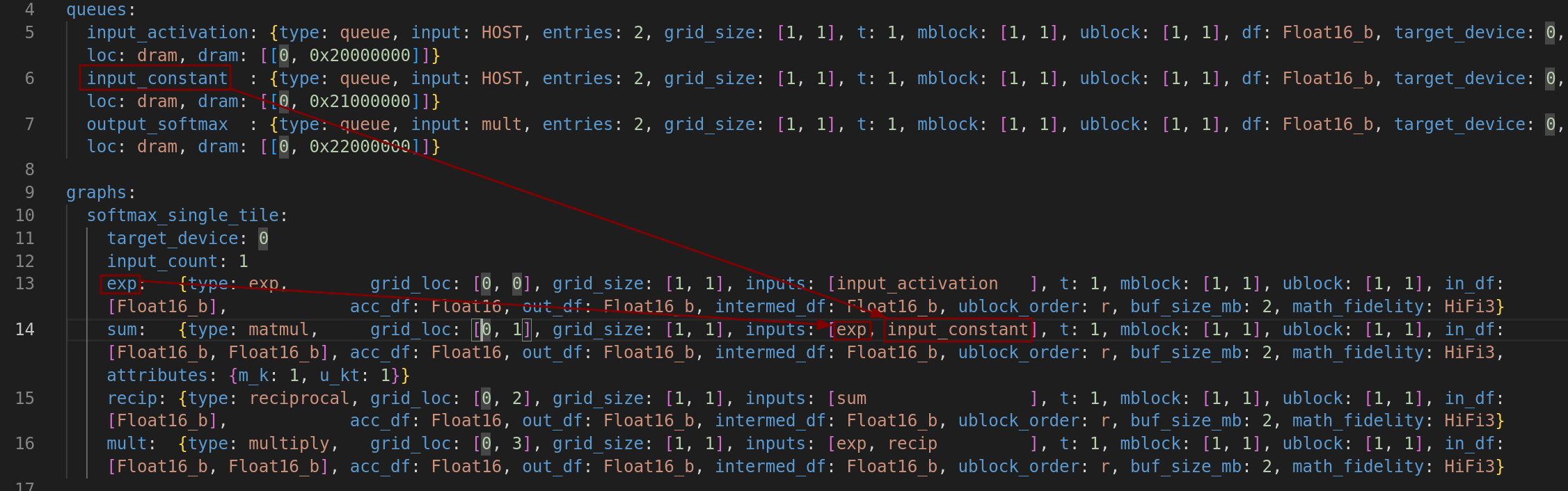
图 6:softmax_single_tile 的数据流动2
- 从 sum(tensix [0,1]) 流向 recip(tensix [0,2])
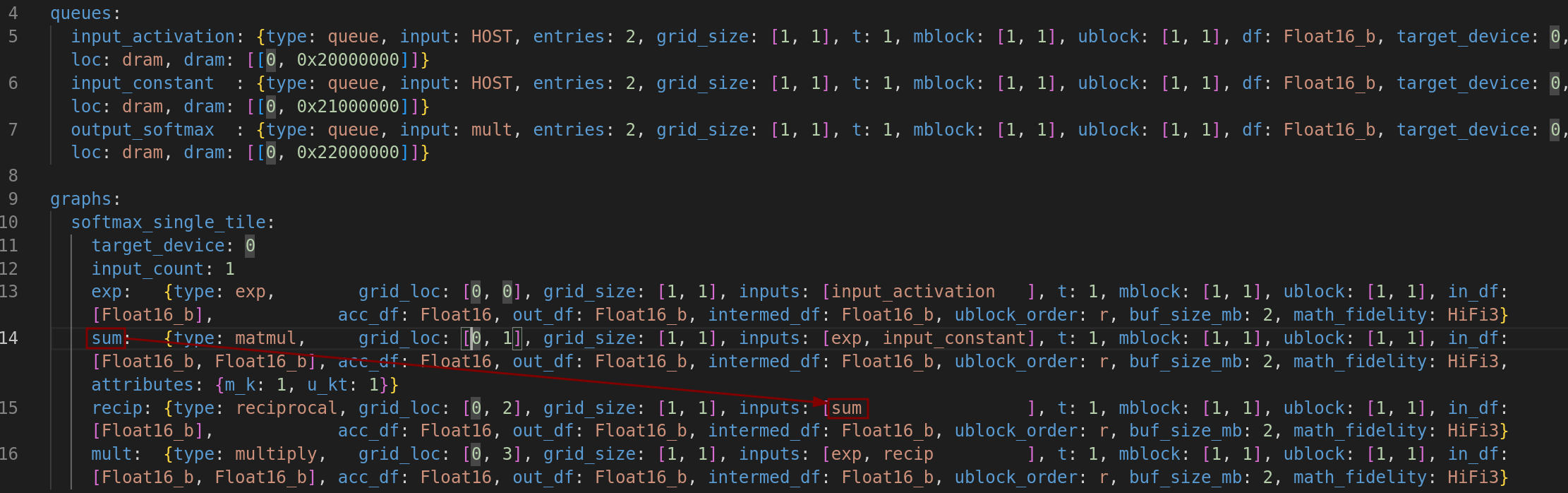
图 7:softmax_single_tile 的数据流动3
- 从 exp(tensix [0,0]) 和 recip(tensix [0,2]) 流向 mult(tensix [0,3])
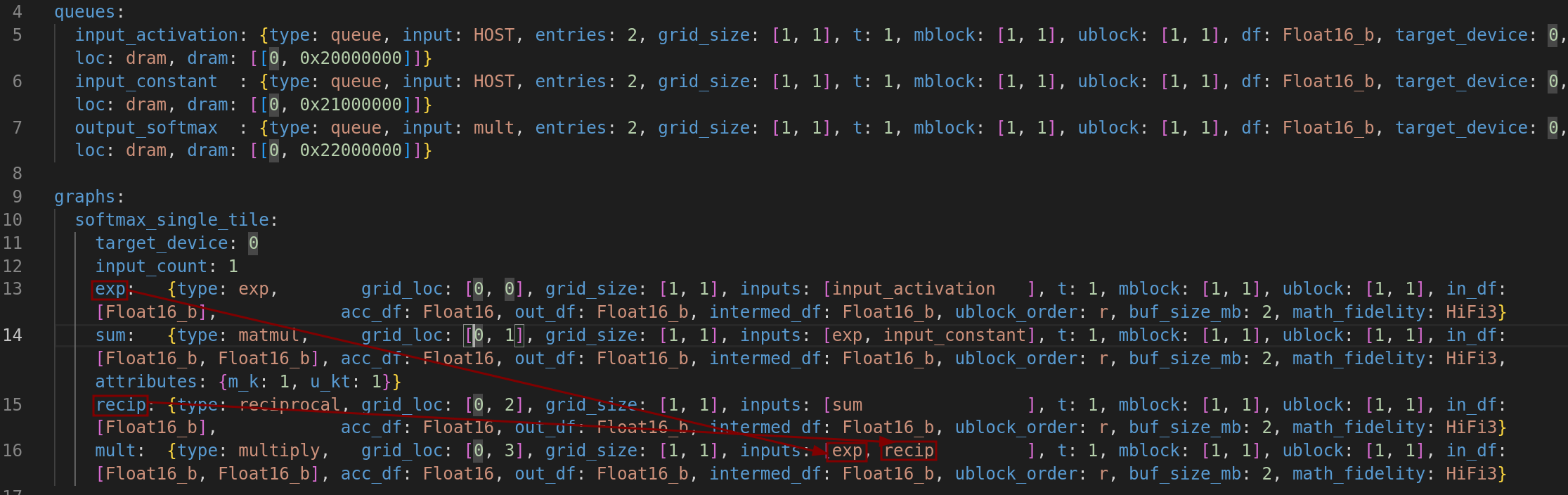
图 8:softmax_single_tile 的数据流动4
- 从 mult(tensix [0,3])流向 output_softmax(dram)(output_softmax的input字段显示)
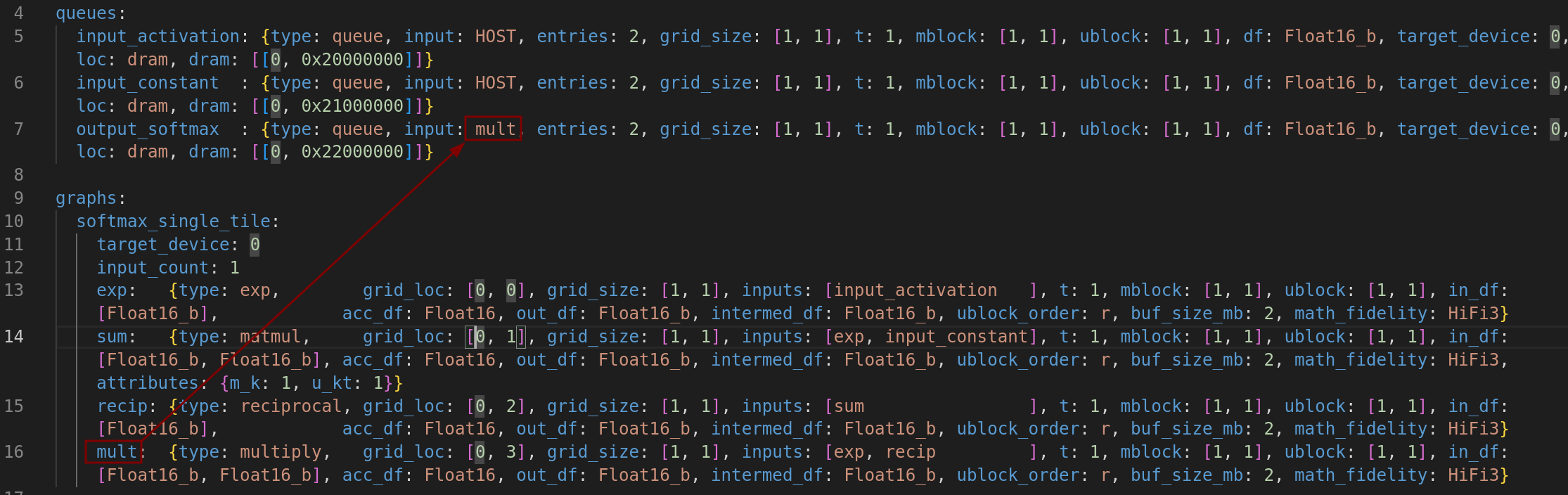
图 9:softmax_single_tile 的数据流动5
programs 解析
programs 由一系列的代码序列组成, 提供了一套语法可以定义常量、变量、循环、图的执行、队列的设置。如图3所示,定义了一个循环,循环执行所有的图。
fused_ops
fused_ops 是一种特殊的op,用于将多个op融合成单个op,减少图的op数量,减少tensix之间的数据传输。每个fused_op有唯一的id,要想使用fused_op,需要将op的type标记为fused_op,并将id放到attributes中。使用示例如下:
fused_ops:
0:
inputs: 2
intermediates: 2
schedules:
-
- add: { type: add, inputs: [input0, input1], mblock: [2, 2], ublock: [2, 2], output: intermed0}
- reciprocal: { type: reciprocal, inputs: [intermed0], mblock: [2, 2], ublock: [2, 2], output: intermed1}
- sqrt: { type: sqrt, inputs: [intermed0], pop: [intermed0], mblock: [2, 2], ublock: [2, 2], output: dest}
- exp: { type: exp, inputs: [dest], mblock: [2, 2], ublock: [2, 2], output: dest}
- datacopy: { type: datacopy, inputs: [dest], mblock: [2, 2], ublock: [2, 2], output: intermed0}
- mul: { type: multiply, inputs: [intermed1, intermed0], pop: [intermed0, intermed1], mblock: [2, 2], ublock: [2, 2], output: output}
声明了一个fused_op,id为0,融合了6个op,使用方式如下:
_fused_op_0: {type: fused_op, grid_loc: [0, 1], grid_size: [1, 1], inputs: [q1, matmul],
t: 1, mblock: [2, 2], ublock: [2, 2], buf_size_mb: 2, ublock_order: r, in_df: [Float16_b, Float16_b], out_df: Float16_b, intermed_df: Float16_b, acc_df: Float16_b, math_fidelity: HiFi3,
attributes: {fused_op_id: 0}}
使用 attributes: {fused_op_id: 0} 标识 fused_op 的id。
Budabackend
目录结构
如图1所示,budabackend 是后端多个工具和库的集合。budabackend 项目源码目录如下图所示:
图 10:budabackend项目 源码 目录结构
源码目录有点凌乱,包含了很多辅助文件(如性能分析和测试、文档、配置文件等等),除此之外,较为重要的有:
-
netlist/netlist_analyzer – 解析和分析Netlist
-
ops – op的源码实现,每个type的op都有自己的一份实现
-
hlks – high level kernels 每个op都可以映射到hlk
-
third_party/tt_llk_grayskull,third_party/tt_llk_wormhole_b0 – low level kernels 实现
-
src/net2pipe,src/pipegen2 – 路由文件生成工具,解析netlist生成noc overlay blob文件
-
third_party/sfpi – 自定义riscv工具链,将c++源码编译成riscv可执行文件
-
runtime/loader – 调用其他工具,编译和加载
编译与执行
如图1所示,编译可以分成两条路径执行,分别生成二进制文件和路由文件(编译生成的文件详见上篇教程)。
二进制文件的生成
netlist解析器会遍历分析graphs中的每个op,op的type是一个字符串,解析器会将op.type映射到一个class tt_op 的子类(tt_op子类实现在ops目录下),每个子类会有自己的规则对应到hlk(hlks目录下的一个具体的文件),hlk可以下降到llk(low level kernel),然后调用自定义工具链将源文件编译成可执行文件。
使用 softmax_single_tile.sum 作为示例说明:
sum: {type: matmul, grid_loc: [0, 1], grid_size: [1, 1],
inputs: [exp, input_constant], t: 1, mblock: [1, 1],
ublock: [1, 1], in_df: [Float16_b, Float16_b],
acc_df: Float16, out_df: Float16_b, intermed_df: Float16_b,
ublock_order: r, buf_size_mb: 2, math_fidelity: HiFi3,
attributes: {m_k: 1, u_kt: 1}}
可以看出 type 是 matmul(矩阵乘),netlist 解析器将 “matmul” 映射到 class tt_mm_bare_op
bool is_valid_matmul_op(string matmul_op) { return (matmul_op == "matmul"); }
std::shared_ptr<tt_op> netlist_utils::create_op(
tt_op_info* op_info_ptr, const unordered_map<string,
tt_fused_op_info>& fused_ops_map) {
...
if (is_valid_matmul_op(op_info_ptr->type)) {
new_tt_op = std::static_pointer_cast<tt_op>(
std::make_shared<tt_mm_bare_op>(...));
}
...
return new_tt_op;
}
查看 tt_mm_bare_op 的实现,可以看出,matmul op 对应了 hlks/matmul/matmul_*.cpp(不同的数据格式有不同实现)
tt_mm_bare_op::tt_mm_bare_op(...) {
...
set_hlk_cpp_file_name_all_cores("hlks/" +
get_hlks_file_name_no_extension(identity, int_fpu_en) + ".cpp");
...
}
op对应的源文件目录如下图所示:

图 11:op 源文件目录
其中,hlks/matmul/matmul_u.cpp 被重命名为 hlks.cpp (这个文件名是固定的),是op的具体实现(hlk和llk的具体实现请见下期教程)。链接命令如下:
./third_party/sfpi/compiler/bin/riscv32-unknown-elf-g++ -mgrayskull
-march=rv32iy -mtune=rvtt-b1 -mabi=ilp32 -flto -ffast-math -O3
-fno-exceptions -Wl,--gc-sections -Wl,-z,max-page-size=16
-Wl,-z,common-page-size=16 -Wl,--defsym=__firmware_start=0
-Wl,--defsym=__trisc_base=53248 -Wl,--defsym=__trisc0_size=20480
-Wl,--defsym=__trisc1_size=16384 -Wl,--defsym=__trisc2_size=20480
-Wl,--defsym=__trisc_local_mem_size=4096
-Tsrc/firmware/riscv/toolchain/trisc1.ld
-Lsrc/firmware/riscv/toolchain -nostartfiles
-o
./tt_build/test/graph_softmax_single_tile/op_0/tensix_thread1/tensix_thread1.elf
./tt_build/test/graph_softmax_single_tile/op_0/tensix_thread1/substitutes.o
./tt_build/test/graph_softmax_single_tile/op_0/tensix_thread1/tmu-crt0.o
./tt_build/test/graph_softmax_single_tile/op_0/tensix_thread1/ckernel_unity.o
值得注意的是,arch是rv32iy,不含浮点指令(Grayskull 与 Wormhole 中的 Tensix RISC-V 核不支持浮点,但Blackhole 支持浮点)。使用了指定的链接脚本 trisc1.ld,部分内容如下:
MEMORY
{
LOCAL_DATA_MEM : ORIGIN = 0xFFB00000, LENGTH = 4K
LOCAL_DATA_MEM_TRISC : ORIGIN = 0xFFB00000, LENGTH = 2K
LOCAL_DATA_MEM_NOCRISC : ORIGIN = 0xFFB00000, LENGTH = 4K
L1 : ORIGIN = 0x00000000, LENGTH = 512K
BRISC_CODE : ORIGIN = 0x00000000, LENGTH = 8448
ZEROS : ORIGIN = 0x00002100, LENGTH = 512
ETH_L1 : ORIGIN = 0x00000000, LENGTH = 256K
/* CKernel code region
= CA::KERNEL_DEFAULT_SIZE_PER_CORE */
TRISC0_CODE : ORIGIN = __trisc_base, LENGTH = DEFINED(__trisc0_size) ? DEFINED(__trisc_local_mem_size) ? __trisc0_size - __trisc_local_mem_size : __trisc0_size : 16K
TRISC1_CODE : ORIGIN = DEFINED(__trisc0_size) ? __trisc_base + __trisc0_size : 0x0000AC00, LENGTH = DEFINED(__trisc1_size) ? DEFINED(__trisc_local_mem_size) ? __trisc1_size - __trisc_local_mem_size : __trisc1_size : 16K
TRISC2_CODE : ORIGIN = DEFINED(__trisc1_size) ? __trisc_base + __trisc0_size + __trisc1_size : 0x0000EC00, LENGTH = DEFINED(__trisc2_size) ? DEFINED(__trisc_local_mem_size) ? __trisc2_size - __trisc_local_mem_size : __trisc2_size : 16K
/* Ckernel migrated code region
= CA::KERNEL_DEFAULT_SIZE_PER_CORE */
TRISC0_OVRD_CODE : ORIGIN = 0x000F4000, LENGTH = 16K
TRISC1_OVRD_CODE : ORIGIN = 0x000F8000, LENGTH = 16K
TRISC2_OVRD_CODE : ORIGIN = 0x000FC000, LENGTH = 16K
NOCRISC_DATA : ORIGIN = 0x33000, LENGTH = 4K
NOCRISC_CODE : ORIGIN = 0x5000, LENGTH = 16K
NOCRISC_L1_CODE : ORIGIN = 0x9000, LENGTH = 16K
NOCRISC_L1_SCRATCH : ORIGIN = 0x33200, LENGTH = 3584
ERISC_CODE : ORIGIN = 0x00000000, LENGTH = 16K
ERISC_DATA : ORIGIN = 0x00004000, LENGTH = 4K
ERISC_APP_DATA : ORIGIN = 0x0003F000, LENGTH = 4K
}
可以看出,因为 Grayskull Tensix 中的5个 RISC-V 核共用 1M L1 SRAM,不同的核是分开编译的,但是共用了一部分链接脚本,Code与Data会按顺序排布在L1上(更详细的内存分布信息见源文件src/firmware/riscv/grayskull/l1_address_map.h)。
路由文件的生成
路由文件是指图1所示的 NOC overlay blob,是硬件 NOC overlay 的一种配置文件。NOC overlay 层可以隔离计算层和NOC层,计算核不再需要关心数据移动,专注于计算即可(与tt-buda不同,tt-metal需要手动调用NOC api进行数据移动,后期tt-metal教程中会详细说明)。
runtime 会调用工具 net2pipe、pipegen,为了复现路由文件的生成过程,手动调用工具生成 blob 文件。
# net2pipe 生成 pipegen.yaml
./build/bin/net2pipe verif/graph_tests/netlists/netlist_softmax_single_tile.yaml
./tt_build/test 0 ./tt_build/test/device_desc.yaml
# pipegen2 生成 blob.yaml
build/bin/pipegen2 tt_build/test/temporal_epoch_0/overlay/pipegen.yaml
tt_build/test/device_desc.yaml
tt_build/test/temporal_epoch_0/overlay/blob.yaml 0 0
# blobgen 生成 pipegen_epoch*.hex
ruby ./src/overlay/blob_gen.rb --blob_out_dir
./tt_build/test/temporal_epoch_0/overlay/
--graph_yaml 1 --graph_input_file
tt_build/test/temporal_epoch_0/overlay/blob.yaml
--graph_name pipegen_epoch0 --root ./ --noc_x_size 13 --noc_y_size
可以看出,blob文件生成分成三步,有两个重要的中间文件:pipegen.yaml 和 blob.yaml。
-
pipegen.yaml – 描述了buffer和pipe的信息,pipe是多个buffer(两个或以上)之间的连接
-
blob.yaml – 将buffer和pipe的信息重新组装成 stream,包含源地址、目标地址和坐标等等信息
针对每个 tensix core 生成一个 overlay blob 文件,命名为 #{graph_name}#{chip_id}#{y}_#{x}.hex,在加载过程中,blob文件会被放在地址OVERLAY_BLOB_BASE处(在l1_address_map中描述)。
总结
本文详细介绍了Netlist的格式,以及使用tt-buda后端进行编译和执行的过程。Netlist作为承上启下的中间格式,描述了算子和Tensix的映射关系、数据流动的方向等关键信息。tt-buda后端解析Netlist,编译生成运行所需的二进制文件和路由文件。通过分析整个解析和编译的过程,可以了解计算图(由算子组成)是如何在Tenstorrent硬件上运行起来的。
在后续的教程中,我们将更详细地介绍算子的不同层次实现,从高层次算子库(HLK)到低层次算子库(LLK),以及自定义指令等。通过解析算子的实现,有助于理解计算单元的原理,并学习如何定义和实现自己的算子。
参考资料:
【1】budabackend github 项目地址 GitHub - tenstorrent/tt-budabackend: Buda Compiler Backend for Tenstorrent devices
【2】tenstorrent NOC overlay 专利说明 CN112306946A - 用于处理器核心的网络的覆盖层 - Google Patents