概述
Tenstorrent成立于2016年,总部位于加拿大多伦多,致力于满足人工智能快速增长的计算需求,拥有有趣的硬件架构以及软件堆栈。由于其CEO是传奇人物Jim Keller而备受关注。
产品路线图
目前,Tenstorrent 已推出两款 AI 加速器产品,Grayskull 和 Wormhole,并计划推出两款 CPU+ML 解决方案产品,Blackhole 和 Grendel。这些产品将为用户提供多样化的选择,以满足不同的计算需求和应用场景。以下是产品路线图(Blackhole推迟了):
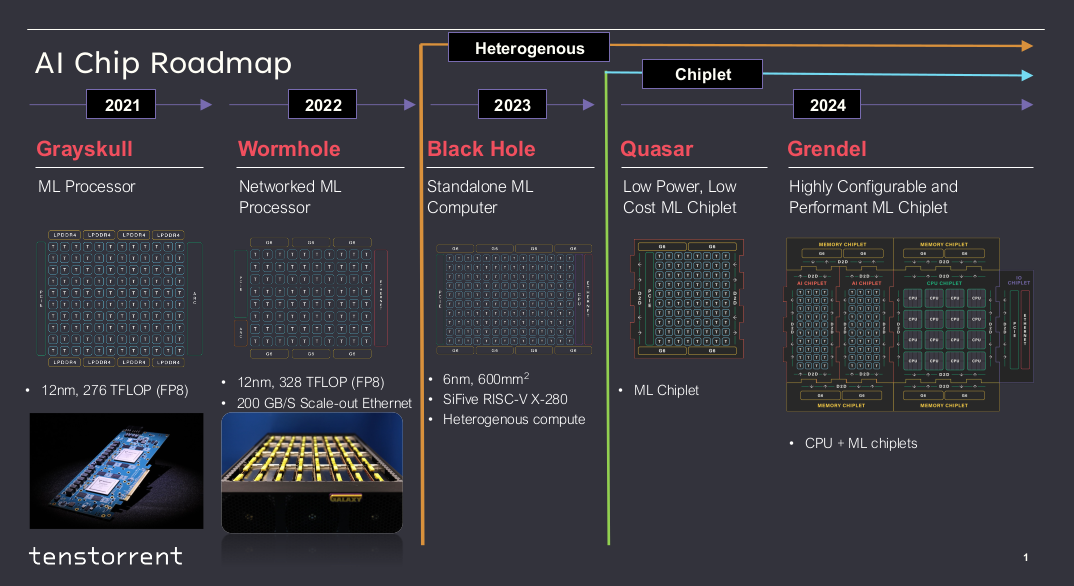
图 1:Tenstorrent产品路线图 (来源:Tenstorrent)
Grayskull
Grayskull芯片采用 GlobalFoundries 12nm 工艺,尺寸为620mm^2。
Wormhole
Wormhole芯片采用 GlobalFoundries 12nm 工艺,尺寸为670mm^2。
Wormhole和Grayskull板卡性能对比如下:
| Feature \ Board | Tenstorrent Grayskull™ e75 | Tenstorrent Grayskull™ e150 | Tenstorrent Wormhole n150 | Tenstorrent Wormhole n300 |
|---|---|---|---|---|
| Tensix Cores | 96 | 120 | 72 | 128 |
| AI Clock | 1 GHz | 1.2 GHz | 1 GHz | 1 GHz |
| TeraFLOPs (FP8) | 221 | 332 | 262 | 466 |
| SRAM | 96MB | 120MB | 108MB | 192MB |
| Memory | 8GB LPDDR4 @ 102.4 GB/sec | 8GB LPDDR4 @ 118.4 GB/sec | 12GB GDDR6 @ 288 GB/sec | 24GB GDDR6 @ 576 GB/sec |
| System Interface | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 | PCIe 4.0 x16 |
| Total Board Power | 75W | 200W | 160W | 300W |
| Dimensions (w/o Cooling Kit) | 18mm x 167.5mm x 69mm | 36mm x 260mm x 111mm | 36mm x 254mm x 111mm | 36mm x 254mm x 111mm |
| Dimensions (w/ Cooling Kit) | 18mm x 257mm x 98mm | 36mm x 399mm x 114mm | 36mm x 393.5mm x 114mm | 36mm x 393.5mm x 114mm |
相对于Grayskull芯片,Wormhole芯片的Tensix核进行了升级。每个核心容纳了更多的SRAM,并且具备执行更复杂的数学运算以及SIMD指令的能力。具体来说,Wormhole芯片的Tensix核配备了1.5MB的SRAM,而Grayskull芯片的Tensix核只有1MB的SRAM。此外,一个显著的不同之处在于Wormhole芯片增加了16个100Gb以太网端口。这些以太网端口的增加使得许多芯片可以连接在一起,从而扩展计算资源。
Blackhole
与Grayskull和Wormhole不同的是,Blackhole不再是单纯的AI加速器,而是集成了CPU和AI加速器的解决方案。它融合了24个SiFive X280 RISC-V内核和多个第三代Tensix内核。该设备将提供1 INT8 POPS(Peta Operations Per Second)的计算吞吐量,性能相比前代产品提升约三倍。此外,它还配备了八通道GDDR6内存、1200 Gb/s以太网连接和PCIe Gen5通道。Blackhole采用6nm级制造工艺。值得注意的是,Blackhole尚未正式推出(已经有测试样片),因此最终产品可能与目前披露的内容有所不同。
Grendel
Grendel作为一项计划产品,将采用Tenstorrent自己的RISC-V核Ascalon,取代SiFive X280 RISC-V内核。
Ascalon
Tenstorrent基于RISC-V架构开发高性能CPU,现在有五种不同的 RISC-V CPU 核心 IP,包括双宽、三宽、四宽、六宽和八宽解码,可用于自己的处理器或授权给感兴趣的各方。
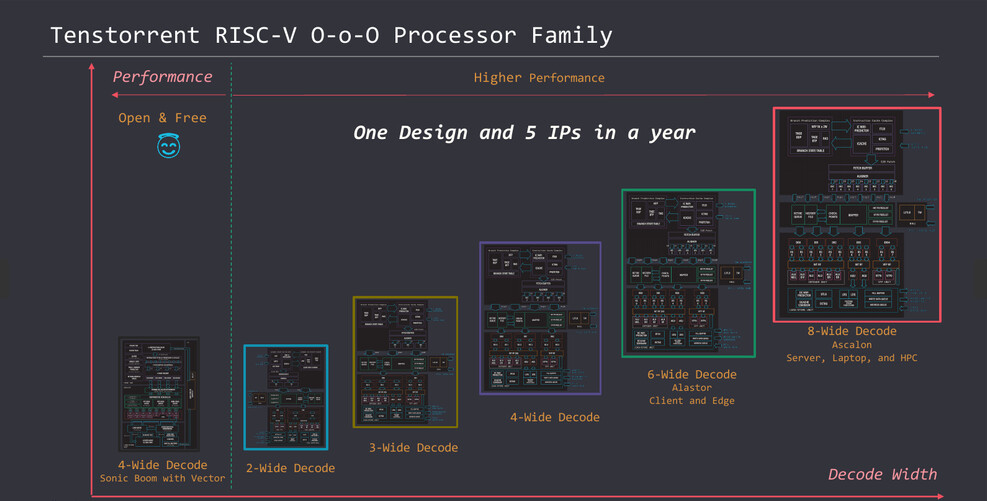
图 2:Tenstorrent RISC-V CPU 产品路线图 (来源:Tenstorrent)
Tenstorrent自己开发了RISC-V CPU,通过Chiplet异构计算的方式,将CPU和AI加速器组合在一起,实现更高性能和功能密度的同时,降低了成本。
硬件架构以及核心组件分析
整体架构
Tenstorrent的AI架构主要可以分为两类:以Wormhole为代表的AI加速器和以Blackhole为代表的CPU+ML异构解决方案。由于Blackhole产品尚未发布,因此本文主要关注Wormhole。
Wormhole

图 3:Wormhole架构示意图 (来源:Tenstorrent)
根据图示,Wormhole主要由网格化的计算单元(128个Tensix,蓝色)、内存单元(GDDR6,黄色)和互联单元(ETHERNET,红色)三个重要部分组成。
计算单元 Tensix
将Wormhole中的Tensix核展开,如下图所示:
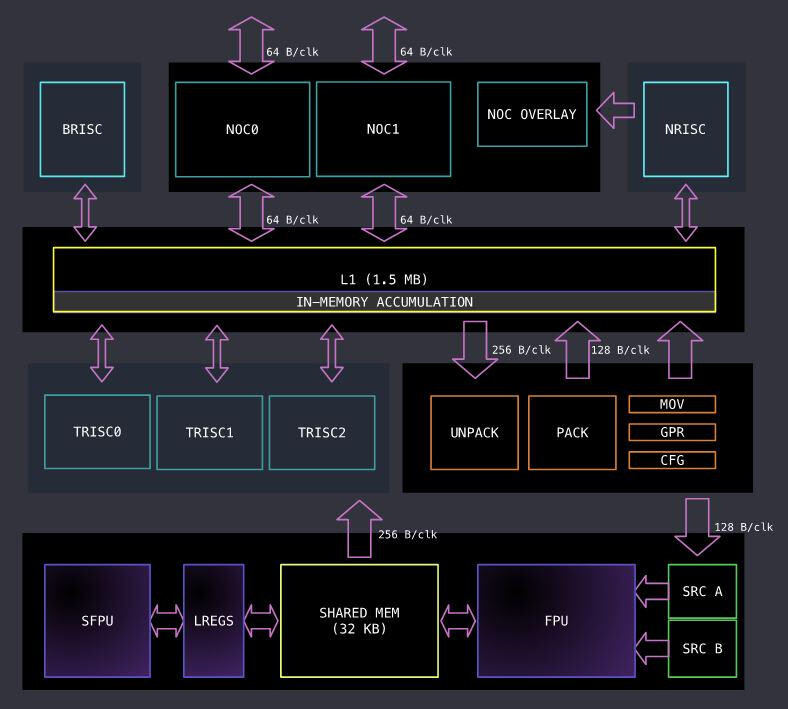
图 4:第二代(Wormhole)Tensix架构图(来源:Tenstorrent)
分析上图,Tensix核组成部分有:
- 5个Baby RISC-V Core(蓝色部分,BRISC、NRISC、TRISC0、TRISC1、TRISC2),用于控制和标量计算。
- 数据传输(浅蓝色部分,NOC0、NOC1、NOC OVERLAY),负责控制设备之间和设备与主机之间的数据传输。
- 打包解包(橙色部分,UNPACK、PACK)。
- 内存(黄色部分,L1、SHARED MEM)。
- 数学引擎(紫色部分,FPU、SFPU),其中FPU是密集张量数学单元,用于执行大量张量数学运算,如矩阵乘法;SFPU是矢量引擎,用于各种杂项激活运算,如指数、平方根、softmax、topK等。
- 寄存器组(绿色部分,SRC A、SRC B)。SRC A,SRC B是源寄存器,DST(未出现在图中)是目标寄存器,它们都是使用一组寄存器,可以存放张量,支持浮点数和低精度数据类型,这里的寄存器和5个Baby RISC-V Core是不同的寄存器。
通过软件对5个RISC-V Core进行分工,BRISC和NRISC主要负责数据移动,而剩余的三个RISC-V Core(TRISCs)负责控制计算过程。
调用FPU的典型计算过程分为三个部分:
- UNPACK(从L1拷贝数据到SRC寄存器)
- MATH(FPU从SRC寄存器读取数据进行计算,结果保存在DST寄存器)
- PACK(将结果从DST寄存器拷贝回L1)。
FPU的计算是 tile-based,L1和寄存器之间的数据传输也是tile-based。UNPACK和PACK的数据搬运是通过底层的TDMA(Time Division Multiple Access)命令实现的。
为了让这三个过程(UNPACK、MATH、PACK)并行执行,三个TRISCs对应不同的功能,其中TRISC0负责UNPACK,TRISC1负责MATH,TRISC2负责PACK。任务的分配由软件控制,对应关系是预先约定好的。
存储单元
Wormhole(n300板卡)的存储架构的层次结构较为简单(相对于GPU而言),分为两个部分:
- DRAM – 大小为24G的GDDR6,所有Tensix核共享。
- SRAM – 每个Tensix核有1.5MB的SRAM(称为L1),是Tensix核独有的,有单独的地址空间,可以寻址访问。
互联单元
Wormhole上的片上网络(NoC-Network_on_Chip)可以在Tensix核之间传输数据,并且可以通过以太网扩展到其他的Wormhole卡。
横向扩展能力(Scale-out)
现代AI模型拥有数十亿甚至上万亿个参数,需要巨大的计算资源来进行训练和推理,单个加速器已经无法满足需求,需要通过scale-out策略扩展多机集群以增加算力。而scale-out的能力正是Wormhole设计的关键所在。
Wormhole的横向扩展能力
Wormhole scale-out 特点
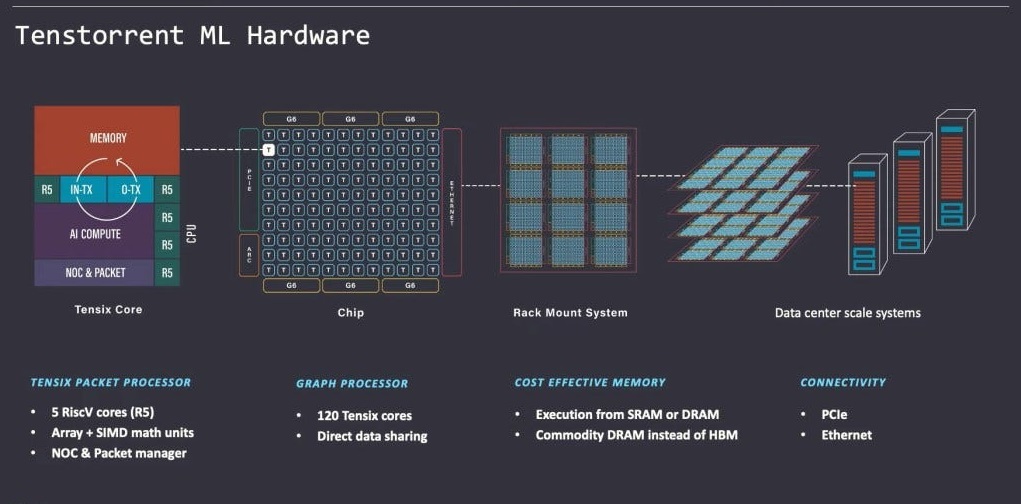
图 5:Wormhole scale-out 示意图(来源:Tenstorrent)
传统的scale-out往往具有核、芯片、服务器、机架这种层次结构,不同层次的互联技术、带宽、延迟方面有差异,带来了软件层面的复杂性。Wormhole的片上网络(NoC)可以透明地扩展到数据中心,对于软件而言,看起来像是一个由Tensix核心组成的2D同质网格,不需要关心芯片、服务器、机架这种层次结构。
如下图所示,Tensix上有数据包管理器,数据包进出Tensix需要解/打包。数据包header中包含地址信息,使用统一的core_id(device_id, x, y)来表示唯一的Tensix core,而无需关心Tensix是否在同一个芯片或服务器。
从软件角度来看,数据包的传输在整个2D网格中是一样的。每个芯片和NOC都可以充当交换机,数据包可以很方便的从Tensix到另一个Tensix。
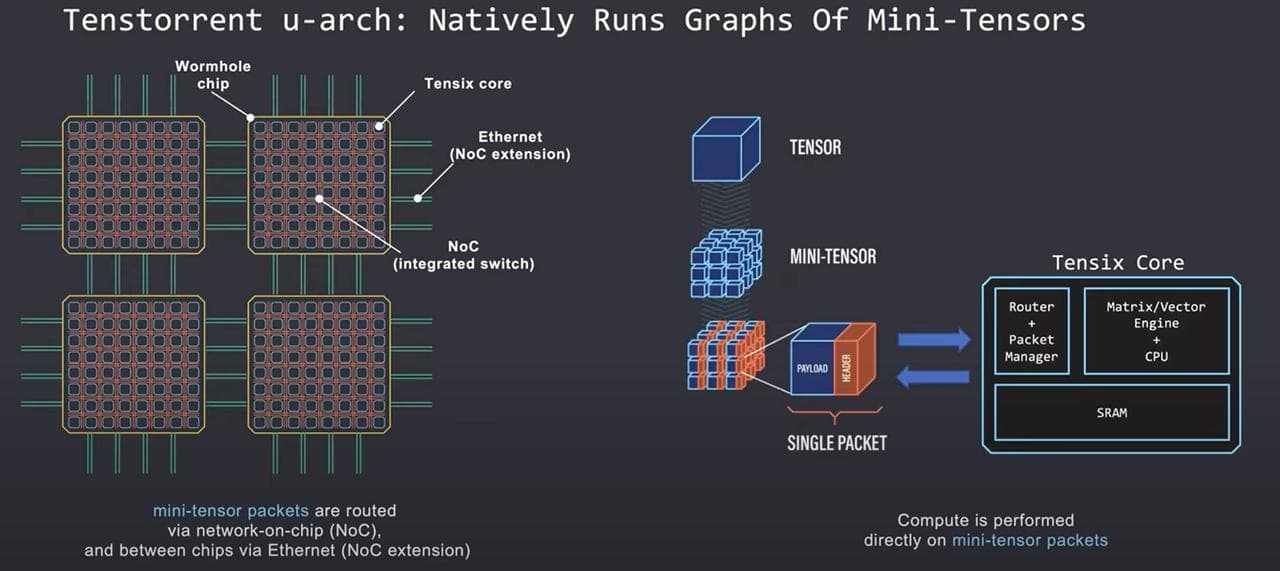
图 6:数据包的传输与计算(来源:Tenstorrent)
Wormhole scale-out 产品
从Wormhole开始扩展,有Nebula、Galaxy、数据中心这几个层次。
Nebula
Tenstorrent 将 Nebula 设计为一个基础构建块。它是一个 4U 服务器机箱。在这个 4U 服务器内部,他们能够塞入 32 个 Wormhole 芯片。
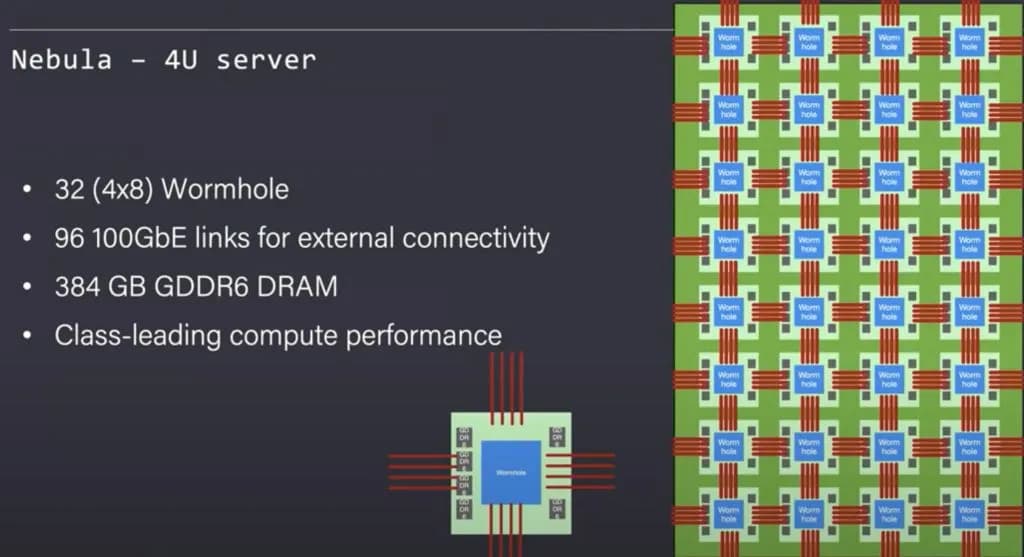
图 7:Nebula结构(来源:Tenstorrent)
Galaxy
8 个 Nebulas 连接在一个扩展网格中,组成Galaxy。该机架还包含 4 个 AMD Epyc 服务器和一个共享内存池。该机架提供 >3TB 的 GDDR6 和 256Gb 的外部以太网链路。通用 AMD Epyc 服务器和内存池连接到以太网网格。
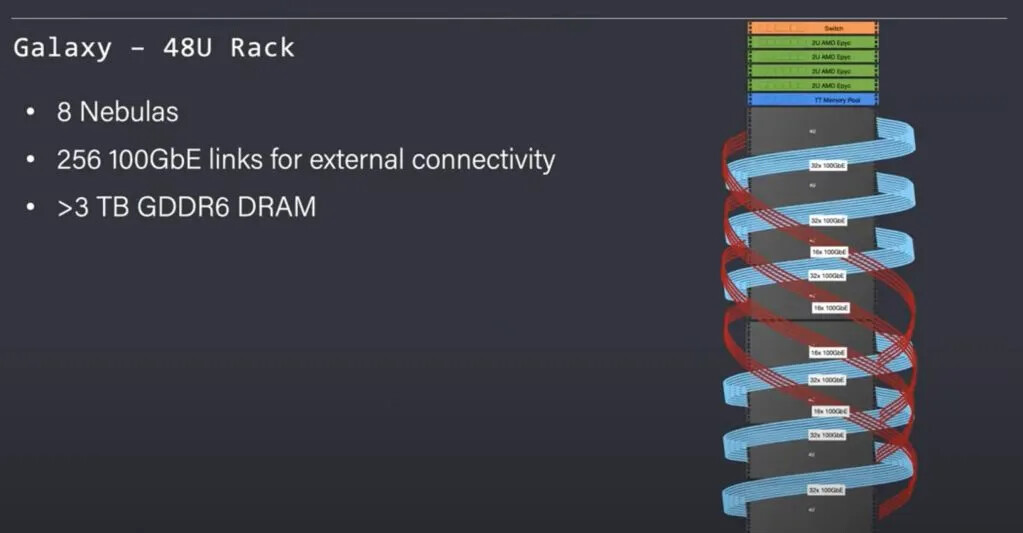
图 8:Galaxy结构(来源:Tenstorrent)
Datacenter
Tenstorrent 支持以 2D mesh连接的机架单元。 支持多种拓扑结构,许多数据中心内流行的经典叶子和脊柱模型完全受支持。
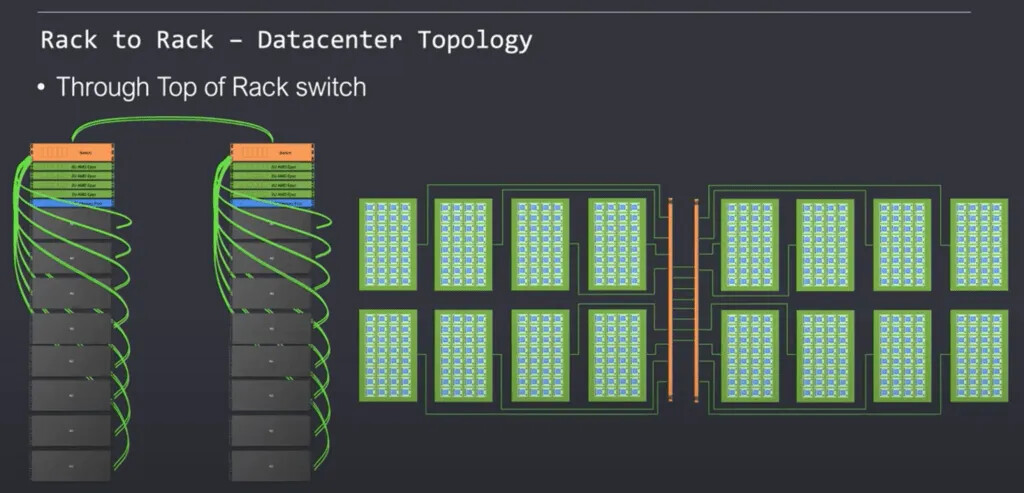
图 9:数据中心拓扑图(来源:Tenstorrent)
与Nvidia的对比
Nvidia扩展超过8个GPU时需要专用的交换机,超过16个GPU则需要使用InfiniBand网络设备,在大规模扩展时会面临一下问题:
- 成本高昂,需要InfiniBand和NVLink设备
- 需要为硬件扩展进行复杂的配置
- 编写和调试在多个GPU节点上运行的高效并行代码需要高度专业化的知识和技能,这增加了开发和维护成本
与之对比,使用Wormhole大规模扩展,可以降低成本并且大大的降低软件复杂度。
未来展望与创新
稀疏性、条件执行与动态路由
未来的趋势是使用特定的神经网络模型解决特定的问题,还是使用一个巨大的模型解决多个问题,不同的问题走不同的路径,参考人类的大脑,处理不同的任务时,大脑中只有一部分神经元处于活跃状态。
Tenstorrent认为是后者,所以希望可以通过条件执行和动态路由的技术,跳过大型模型中不需要执行的块,只执行需要的部分。而Tensix中的控制核可以进行条件判断,在运行时决定路由。
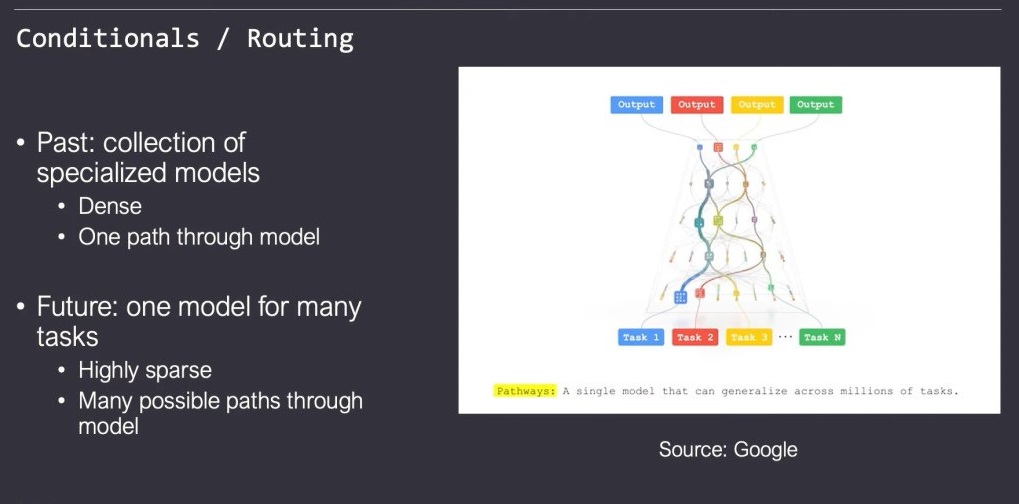
图 10:条件执行和路由(来源:Tenstorrent)
软件生态
硬件设计和软件开发的难易程度是相互依存、相互影响的。高性能的硬件设计需要强大的软件生态支持,而成熟的软件生态可以反过来推动硬件设计的优化。
软件栈既要兼容现有的AI开发框架,又要发挥加速器的硬件性能,是个不小的挑战。建立一个完整的软件生态并不简单,Tenstorrent采用RISC-V作为Tensix中控制核的ISA,并复用了开源的RISC-V的编译器(gcc),从而降低了开发难度。
Tenstorrent开源了其软件栈T-Buda和TT-metal,后续教程开始讲解其软件栈,包括软件架构、如何使用以及源码分析等,通过分析软件,可以更好地理解其硬件设计以及软硬件分工。
参考链接
【1】Tenstorrent Shares Roadmap of Ultra-High-Performance RISC-V CPUs and AI Accelerators | Tom's Hardware
【2】Tenstorrent Wormhole Analysis - A Scale Out Architecture for Machine Learning That Could Put Nvidia On Their Back Foot
【3】Tenstorrent Blackhole, Grendel, And Buda - A Scale Out Architecture For Sparsity, Conditional Execution, And Dynamic Routing
【4】https://www.eetimes.com/tenstorrent-engineers-talk-open-sourced-bare-metal-stack/
【5】Cards - Tenstorrent
【6】https://www.youtube.com/watch?v=5bn54FSe_0