介绍
TT-MLIR 是一个为 Tenstorrent AI 加速卡设计的编译器项目。它基于 MLIR 项目,采用多层次中间表示(IR)方言,实现从高层抽象到底层硬件指令的平滑转换,MLIR 的模块化设计也使得其更易于维护和扩展。
TT-MLIR 将考虑兼容主流 AI 框架,如 OpenXLA 和 PyTorch(进行中),目前能够生成 flatbuffer 格式文件和 c 语言文件,其中 flatbuffer 文件将在 TT-Buda runtime 上运行,c 语言文件可以对接 TT-Metal 框架的编译器,编译成可执行文件。由于 TT-MLIR 项目存在复用和借鉴 TT-Buda 和 TT-Metal 的情况,建议在阅读本文前现行阅读前文 3. 探索 Tenstorrent 的 AI 开发软件栈:TT-BUDA 8. 探索 TT-Metal:Tenstorrent 的 low-level 开发软件栈。更多关于 MLIR 和图编译器的内容请参考 6. 探索图编译器:实现高效的图计算。
动机
前文提到的框架 TT-Buda/TT-Metal 存在一些问题:
-
TT-Buda 是自上而下的开发框架,可以方便用户部署AI模型。但是因为缺少底层接口,很难对底层算子进行优化,也难以新增算子。这既缺乏灵活性,也阻碍了性能优化。
-
TT-Metal 是自下而上的开发框架,用户可以使用底层接口来添加或者优化算子。但由于它过于底层,需要熟悉硬件架构细节,才能构建高性能的算子库,这无疑会增加AI模型的部署难度。例如,在TT-Buda中可以利用网表(Netlist)方便的将算子以数据流的形式进行部署,但在 TT-Metal 中则需手动控制数据传输和同步。
为了解决上述问题,Tenstorrent 提出了一个分层抽象的 TT-MLIR 项目,提高易用性的同时,降低开发和维护的成本。
架构
TT-MLIR 项目架构如下图所示:
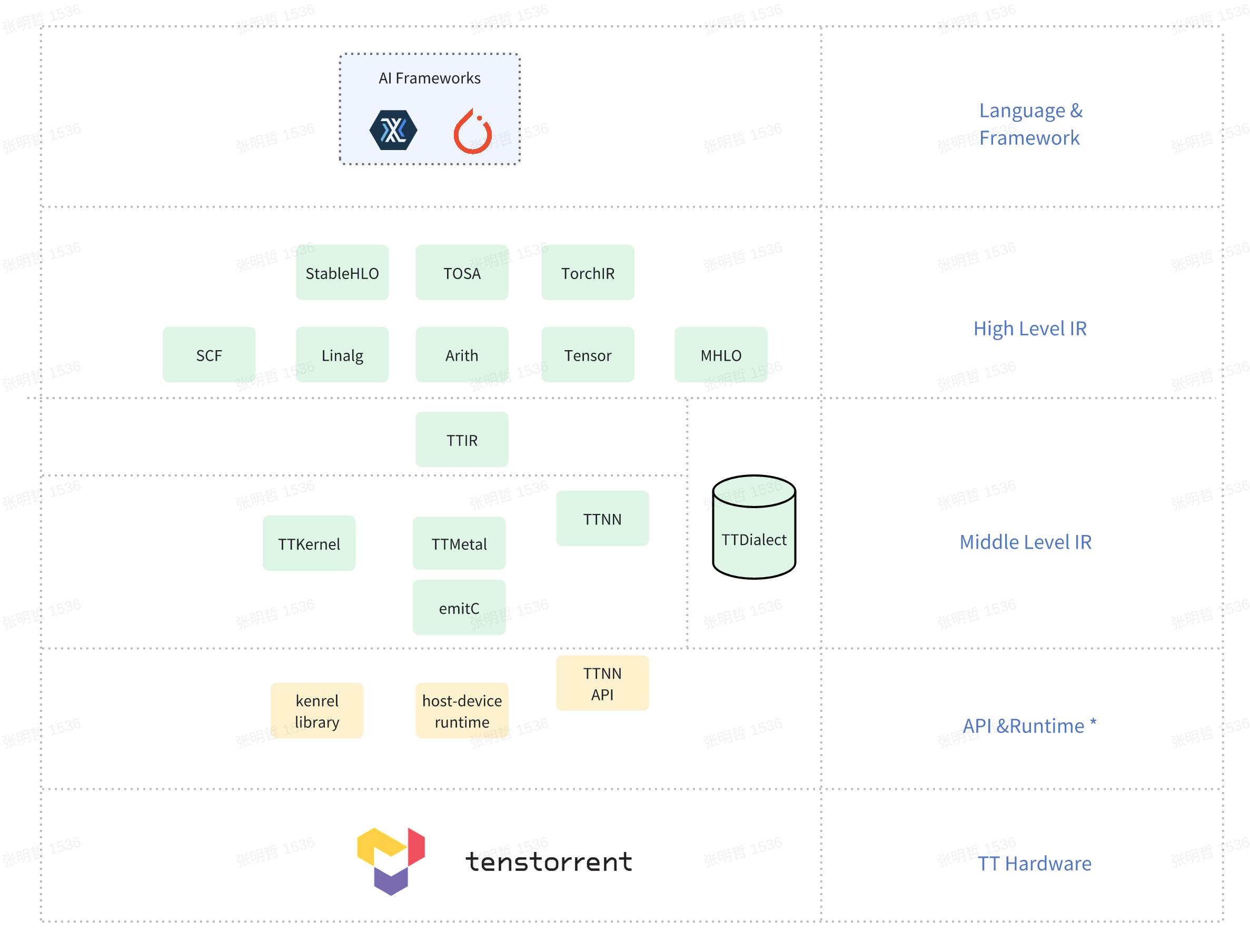
注:未来API&Runtime层将会是自动生成的底层IR
主要包含以下几个层次:
-
前端(AI框架):AI模型可以通过 OpenXLA 或 Torch MLIR 的项目导入生成 tosa 或者 linalg 方言,该层级负责AI框架导入到图IR,并进行优化、常量折叠、算子融合等高层优化,生成硬件无关的编译图。
-
中间层前端(TTIR):将前端方言转换为 TTIR 方言,作为前端与后端的中间表示。TTIR 主要负责处理多种 TT 硬件上的通用操作,如调度、布局和内核操作。对于特定算子,编译器保持其原始颗粒度,不会拆分为多个更细节的操作。
-
中间层后端(TTNN, TTKernel, TTMetal):生成针对特定 TT 硬件的抽象代码。这一层负责自动生成 runtime 中的数据存储、内存配置和网格配置代码,并将上层算子翻译为底层 API 调用。TTNN 方言的抽象层次比 TTMetal/TTKernel 方言要高,对应到 TT-Metal 框架中,TTNN api 是由更低层次的 TT-Metal api 实现的。
-
底层 (Kernel library、host-device runtime、TTNN API):这一层目前以 C 语言文件形式展示,与手动使用 TT-Metal 框架开发保持一致,便于与 TT-Metal 框架对接。当前,从方言 TTNN/TTKernel/TTMetal 翻译到 C 语言文件。
TT-MLIR 目前支持两条编译路线:
-
线路1:流程为 TTIR → TTNN → EmitC → C 文件 → binary。生成的 C 文件调用 TTNN api,与手动调用 TTNN api 开发模型是一样的。
-
线路2:流程为 TTIR → TTMetal/TTKernel → EmitC → C 文件 → binary。生成的 C 文件调用 TT-Metal api,与使用 TT-Metal API 开发并组合算子的方法一样的。
这两条路线的下降过程基本相同,主要区别在于生成的 C 文件使用的是 TTNN API 还是 TT-Metal API。
TT-MLIR方言设计
TT
TT 方言包含通用的数据类型和属性,构成了编译器多层架构的基础。主要组成部分包括:
-
tt.arch:枚举 TT 硬件架构,如 Grayskull、Wormhole_B0 和 Blackhole。
-
tt.layout:描述张量数据如何在多个设备和核心的网格上进行分片(tiling)及其内存中的排列方式,展示不同尺寸张量在统一尺寸上的分配。
-
tt.grid:定义张量数据在二维网格结构上的形状,即张量需要部署到的统一尺寸。
这些组件共同支持 TT 方言在编译器多层架构中的通用数据类型和属性的定义。
TTIR
TTIR 方言是 TT-MLIR 的通用方言,旨在描述在不同 TT 硬件上执行的统一操作和优化,而不绑定于任何特定的硬件架构。TTIR 包括以下两类主要操作:
-
通用操作:控制指令如何调度到 TT 硬件上执行,涉及计算核心的输入输出、张量读取、内存访问类型等参数。这些操作支持内存位置、数据转置和计算网格的优化。特定指令会在调度过程中被编译器解析,并翻译为底层方言的运行时操作。
-
布局操作:定义内存存储方式,包括 tiling 规范、内存位置、数据类型和 tiling 大小,这些因素影响数据在芯片上的布局。
TTIR 是一种高级方言,用于建模 Tenstorrent 设备上的张量计算图,并支持接收 tosa 和 linalg 等输入。具体操作示例包括:
-
ttir.generic:描述任务执行的操作,包括调度区域,定义每个核心需要执行的工作。
-
ttir.to_layout:在不同张量内存布局和内存空间之间进行转换。
-
ttir.yield:标记调度区域的结束。
-
ttir.kernel:抽象的算子操作,表示算子接收张量并输出其他张量的操作。
TTIR 方言为构建底层设备相关方言提供了基础构建信息。
TTNN
TTNN 是对 TTNN API 的抽象方言,旨在简化从 TTIR 到中间编译器后端的转换过程。TTNN API 包括设备接口、内存配置接口、操作接口、模型转换接口、打印报告接口和梯度操作接口六大类。在 TTIR 转换为 TTNN 的过程中,某些操作无需进一步细化,直接转换为 TTNN 表示,并生成相应的 C 文件。
TTNN 的设计旨在避免传统编译器将用户层级(大颗粒度)算子逐步降到底层(小颗粒度)算子的复杂过程。TTNN 允许在 TTIR 中保留某些大颗粒度的算子。以下是一些 TTNN 的操作示例:
-
ttnn.open_device:使用指定的 device_id 打开设备【设备类】。
-
ttnn.softmax:执行归一化指数函数【操作类】。
-
ttnn.to_memory_config:将张量转换为所需的内存配置【内存配置类】。
-
ttnn.model_preprocessing:执行模型预处理操作【模型转换类】。
-
ttnn.register_pre_operation_hook:注册预操作的钩子【梯度操作类】。
TTNN 方言提供了对 TTNN api 的抽象,使得 TT-MLIR 项目可以对 TTNN 库的进行复用。
TTKernel
TTKernel 方言是对 Tenstorrent 底层 kernel API 的抽象,包含六大类操作:数据移动接口、循环缓冲区操作接口、计算接口、内核声明接口、底层算子接口和打包封装接口。以下是 TTKernel 方言的一些具体操作示例:
-
ttkernel.cb_reserve_back:在循环缓冲区中申请一个空闲的矩阵【循环缓冲区类】。
-
ttkernel.add:执行两个矩阵相加【计算类】。
-
ttkernel.matmul:执行两个矩阵相乘【计算类】。
-
ttkernel.return:指示函数返回【低层级 kernel 类】。
-
ttkernel.pack:执行打包操作【打包类】。
-
ttkernel.noc_async_read:执行异步读取操作【数据移动类】。
-
ttkernel.get_arg_addr:获取参数地址【内核声明类】。
TTKernel 方言提供了对 TT-Metal kernel api 的抽象。
TTMetal
TTMetal方言用于抽象主机到设备的工作调度,它结合了TT-Buda项目中的队列和图设计思路,以及TTMetal框架中的Host API概念,但与这两者并不完全对应。预计TTMetal方言将涵盖内存管理、数据准备、内核配置、执行计算、数据同步和结果处理六大类操作(目前社区建议实现与Host API的直接对应)。以下是一些操作示例:
-
ttmetal.dispatch:将计算程序派发到设备并运行的操作。【数据准备类】
-
ttmetal.host_write:将数据从主机写入加速器的操作。【数据同步类】
-
ttmetal.alloc:申请内存空间的操作。【内存管理】
TTMetal 方言提供了对 TT-Metal host api 的抽象,常和 TTKernel 方言一起使用,使得 TT-MLIR 项目可以对 TT-Metal 框架进行复用。
自定义算子
自定义算子一向是AI编译器的重要关注点。一个优秀的AI编译器框架能够为用户提供快速便捷的平台无关算子编写接口。该编译器就提供了在中层的便捷自定义算子方式。
首先,介绍一下TTMetal框架中算子如何生成,具体参考9. 深入 TT-Metal:自定义 Kernel 与跨核数据传输同步。其中 TTNN API 是与PyTorch 中的算子是一一对应的,而 TTNN API 是由更底层的Kernel API和 Host API 中的一系列操作实现的。TT厂家已经提供了默认的实现,不过用户可以调用自己提供的算子库以达到自定义算子的效果。
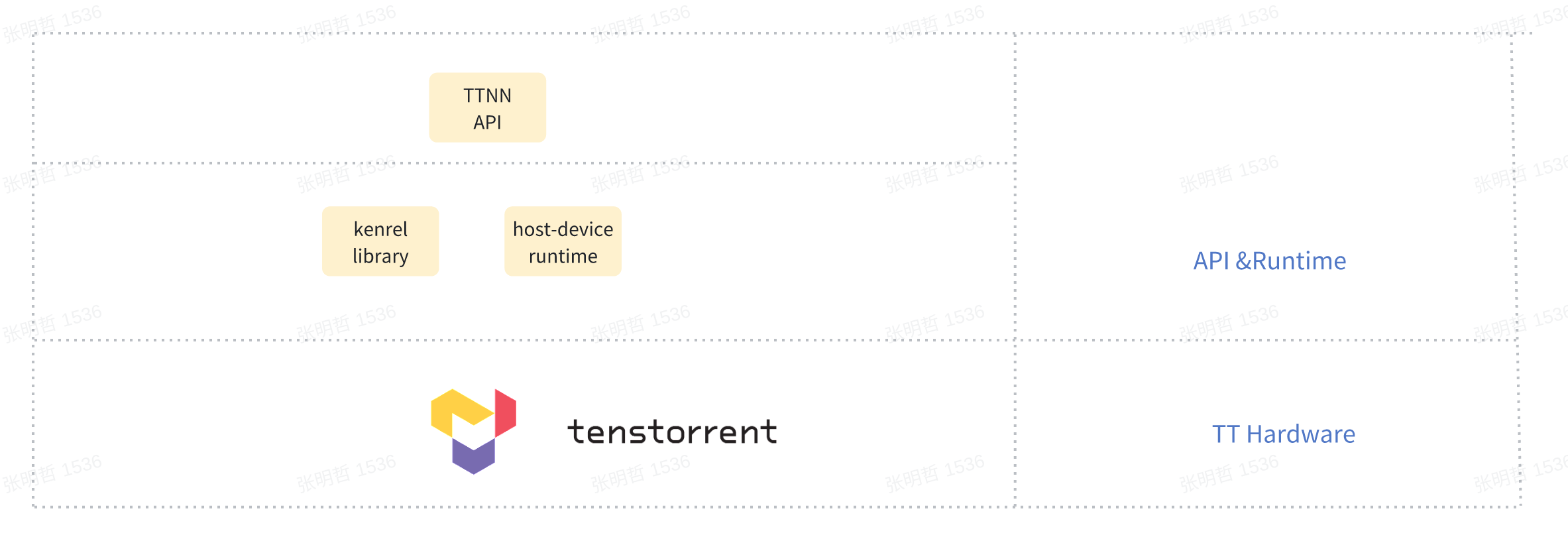
在 TT-MLIR 框架中,底层的 TTNN 实现过程是在 C 文件层面,用户无法直接优化这个过程。这表明,从前端到 TTNN API 的路径存在明显缺陷。未来可能会将 TTNN 的调用逻辑上移,将 TTNN 方言下降为 TTMetal 和 TTKernel 方言。整个下降过程如下所示:前端接入 TTIR,分析已实现的算子,生成 TTNN,然后统一生成 TTMetal 和 TTKernel 操作,最终调用底层相关库。
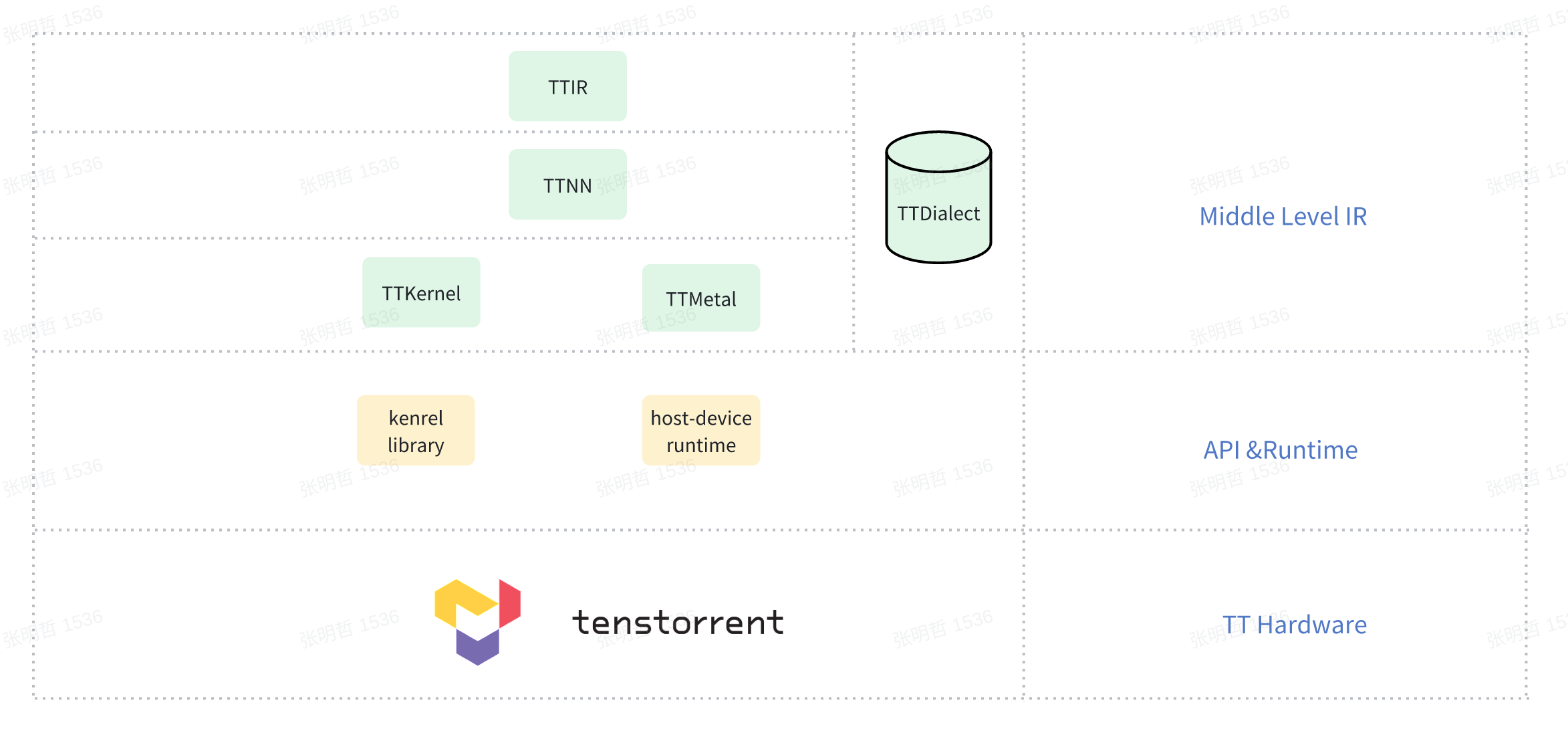
依照这个路线设计,用户可以修改 TTNN 生成后端方言的规则来优化已有算子,也可以新增 TTNN 操作和生成规则来自定义某些算子与上层新声明的算子对应。相比原先框架需要手动更改每个API的麻烦,新框架提供了pattern-rewrite 的方法可以批量修改生成规则,方便很多。
张量布局
Tenstorrent 的硬件对数据格式有特定要求,使用 32x32 的 tile,而这与原始数据的尺寸和维度不同。因此,在部署过程中需要进行数据转换。转换的原则是保持算法上的数据形状不变,并明确记录转换过程,以便保留更多信息用于后续优化。下面将通过示例进行说明。
张量布局优化实例
输入张量会经过一系列操作,最终转换为硬件所需的格式。这些操作包括动态维度变化、切片(Tiling)和数据填充等。
例如有如下张量类型:
tensor<2x3x64x128xf32>
张量进行了以上所说的优化后,如下所示:
tensor<2x3x64x128xf32,
#tt.layout<
(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), //维度变化
undef,
<1x1>,
memref<384x128xf32, #tt.memory_space<l1>> //内存操作
>
>
注:
TT 方言使用tt.layout属性对张量布局进行编码
memref<384x128xf32, #tt.memory_space<l1>> 部分是 TTIR 加工过的memref方言,相比原方言,明确指定了内存空间为tt.memory_space<l1>。
该张量有 4 个属性,来显示表示这个张量的转换过程,如下所示:
-
linear:表示仿射映射,定义了逻辑张量维度如何映射到网格形状,可以理解为数据的原始尺寸。 -
oob_val:填充的值,默认是 undef(即为0) -
grid:表示张量目标分配的计算核心数(Tensix core)和排布。 -
memref: 用于描述张量在内存上的布局,它通过以下自定义类型和属性进行修饰:-
tt.tile:表示一个 32x32 的 tile。由于硬件数据传输和计算都是基于 tile 的,因此这个类型用来定义张量在内存中的块大小。 -
tt.memory_space:指定张量使用的内存空间,具体包括:-
system:主机 DRAM,通常用于主机端。 -
mmio:通过 MMIO 映射的主机 DRAM,Tensor Core 可见,但不常用。 -
dram:设备 DRAM,所有 Tensor Core 共享的内存。 -
l1:设备 SRAM,仅供 Tensor Core 专享,用于高效存取数据。
-
-
经过变化后,不同规格尺寸数据都成了统一的规格尺寸。用户只需在这个统一的尺寸上进行优化即可。这为优化策略的编写提供了极大的方便,同时让优化算法兼容了各种尺寸。
接下来具体看看张量的维度折叠策略。
维度折叠
维度折叠是将张量从高维空间映射到低维空间的过程。例如:
(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3)
回顾前面的张量示例,我们有一个 4 维张量,其形状为 (2, 3, 64, 128)。在上述仿射映射中,张量的维度对应到 (d0, d1, d2, d3)。张量布局属性中的第三个属性 grid 表示目标网格的形状是 (1, 1),即 1x1 个 Tensix Core,这反映了硬件上二维平面 Tensix Core 的布局。因此,仿射映射的右侧 (d0 * 192 + d1 * 64 + d2, d3) 也是二维的。
当我们需要访问给定高维张量 (1, 1, 6, 100) 的索引,即获取该张量在目标硬件上的二维坐标时,可以利用上述公式计算出重新映射的偏移量,从而确定其对应的坐标:
(1 * 192 + 1 * 64 + 6, 100) = (262, 100)
重新映射的偏移量 (262, 100) 对应了折叠后的物理内存中的行和列索引,可以看出,d0 和 d1 被折叠在一起。控制维度折叠的参数是折叠区间。默认的折叠区间值为 (0, -1),即折叠第0维到倒数第一维(从右往左数的第一维)。
折叠区间中的负数(如“-1”)表示从右往左的维度,tt.to_layout 构造函数允许通过 collapseIntervals 变量来控制折叠区间。此变量的值是包含一系列二元组的列表,每个二元组定义了一个左闭右开的维度区间。以下是几个例子以帮助理解:
-
三维 张量 折叠到二维网格,默认
collapseIntervals=[(0, -1)]:折叠第0维到右数第1维(不包括右数第1维)。- (d0, d1, d2) → (d0 <> d1, d2)
-
四维 张量 折叠到三维网格,
collapseIntervals=[(1, -1)]:折叠第1维到右数第1维(不包括右数第1维)。- (d0, d1, d2, d3) → (d0, d1 <> d2, d3)
-
四维 张量 折叠到三维网格,
collapseIntervals=[(0, 2)]:折叠第0维到第2维(不包括第2维)。- (d0, d1, d2, d3) → (d0 <> d1, d2, d3)
-
七维 张量 折叠到四维网格,
collapseIntervals=[(0, 3), (-3, -1)]:折叠第0维到第3维(不包括第3维),同时折叠倒数第3维到倒数第1维(不包括倒数第1维)。- (d0, d1, d2, d3, d4, d5, d6) → (d0 <> d1 <> d2, d3, d4 <> d5, d6)
这种优化显式地将多维张量映射到抽象的物理空间,简化了数据的处理和存储。
分片(Tiling)
在保留原有张量形状的情况下,对张量进行切片,具体表现为将 memref 切成 tt.tile(即 32x32)大小,以满足硬件需求,转换如下所示:
tensor<3x64x128xf32,
#tt.layout<
(d0, d1, d2) -> (d0 * 64 + d1, d2),
undef,
<3x2>,
memref<64x64xf32, #tt.memory_space<l1>>
>
>
memref 的属性从 64x64xf32 转换为 2x2x!tt.tile<32x32, bfp_bf8>,即表示由 4 个 32x32 大小的 tile 组成,数据类型为 bf8。
tensor<3x64x128xf32,
#tt.layout<
(d0, d1, d2) -> (d0 * 64 + d1, d2),
undef,
<3x2>,
memref<2x2x!tt.tile<32 x 32, bfp_bf8>, #tt.memory_space<l1>>
>
>
在特殊情况下,为了适配 SFPU 的格式需求,数据也可以转换为 16x16xtype。
填充(Padding)
在物理内存分配中,张量数据通常需要进行填充(padding)操作,以适应目标尺寸。填充区域的大小由 tile 大小和张量大小决定,填充数值由oob_val 决定。例如我们有以下张量:
tensor<53x63xf32,
#tt.layout<
(d0, d1) -> (d0, d1),
undef,
<3x2>,
memref<18x32xf32, #tt.memory_space<l1>>
>
>
由于原始尺寸为 18x32,而目标尺寸为 tile 32x32,编译器在此过程中对原始数据进行了填充。
tensor<53x63xf32,
#tt.layout<
(d0, d1) -> (d0, d1),
undef,
<3x2>,
memref<1x1x!tt.tile<32 x 32, bfp_bf8>, #tt.memory_space<l1>>
>
>
如果我们利用上述张量,最终会获得形状为 1x1x!tt.tile<32x32> 的 m em ref。
通过以上优化,输入数据最终被转换为硬件支持的格式。
使用和开发实践
方言间转换
下面将分析不同方言之间的转换,旨在帮助读者加深对编译过程和方言的理解。
从 linalg 下降到 TTIR
由于代码层级尚未实现,以下为合理推测的源代码结构,分为几个部分:
-
张量声明部分:
linalg.generic:声明张量计算操作,包括输入输出数据规格、张量迭代器类型表、张量尺寸及计算区域的主题。
-
具体计算区域部分:
-
arith.mulf:执行乘积操作。 -
linalg.yield:标志linalg.generic计算区域结束。
-
#map = affine_map<(d0, d1) -> (d0, d1)>
module attributes {torch.debug_module_name = "_lambda"} {
ml_program.global private mutable @global_seed(dense<0> : tensor<i64>) : tensor<i64>
func.func @forward(%arg0: tensor<64x128xf32>, %arg1: tensor<64x128xf32>) -> tensor<64x128xf32> {
%0 = tensor.empty() : tensor<64x128xf32>
%1 = linalg.generic {indexing_maps = [#map, #map, #map], iterator_types = ["parallel", "parallel"]} ins(%arg0, %arg1 : tensor<64x128xf32>, tensor<64x128xf32>) outs(%0 : tensor<64x128xf32>) {
^bb0(%in: f32, %in_0: f32, %out: f32):
%2 = arith.mulf %in, %in_0 : f32
linalg.yield %2 : f32
} -> tensor<64x128xf32>
return %1 : tensor<64x128xf32>
}
}
通过上述命令转换后,代码结构如下:
-
张量声明部分:
ttir.generic:张量计算声明操作,包含芯片排布规格、张量仿射索引表、张量迭代器类型表、输入输出数量及每个核心计算区域作为操作主体。
-
具体计算区域部分:
-
arith.mulf:执行乘积操作【布局类】。 -
ttir.yield:标志ttir.generic计算区域结束【通用类】。
-
#map = affine_map<(d0, d1) -> (d0, d1)>
module attributes {torch.debug_module_name = "_lambda"} {
ml_program.global private mutable @global_seed(dense<0> : tensor<i64>) : tensor<i64>
func.func @forward(%arg0: tensor<64x128xf32>, %arg1: tensor<64x128xf32>) -> tensor<64x128xf32> {
%0 = tensor.empty() : tensor<64x128xf32>
%1 = "ttir.generic"(%in, %in_0, %out) <{
grid = #tt.grid<1x1>, // 芯片排布规格
indexing_maps = [#map, #map, #map], // 一组索引用的仿射表
iterator_types = [#parallel, #parallel], // 输入/输出张量的迭代器类型表
operandSegmentSizes = array<i32: 2, 1>, // 输入和输出的个数,比如这个对应2个输入,一个输出
({
^bb0(%arg2: memref<64x128xf32, #l1_>, %arg3: memref<64x128xf32, #l1_>, %arg4: memref<64x128xf32, #l1_>): // 包含一些代表每个核心所做工作的计算的区域
%2 = arith.mulf %in, %in_0 : f32
ttir.yield %2 : f32
}) : (tensor<64x128xf32, #layout1>, tensor<64x128xf32, #layout1>>) -> tensor<64x128xf32, #layout1>
}
}
linalg 方言下降后,操作会被分配具体的TT设备内存等更多关于TT硬件通用属性。
从 tosa 下降到 TTIR
使用 ttmlir-opt 将 tosa 下降到 TTIR,命令如下:
ttmlir-opt --convert-tosa-to-ttir tosa.mlir \
-o ttir.mlir
测试文件如下所示:
// RUN: ttmlir-opt --convert-tosa-to-ttir %s | FileCheck %s
#any_device = #tt.operand_constraint<dram|l1|scalar|tile|any_device|any_device_tile>
module attributes {} {
func.func @test_mul(%arg0: tensor<13x21x3xf32>, %arg1: tensor<13x21x3xf32>) -> tensor<13x21x3xf32> {
%0 = tosa.mul %arg0, %arg1 {shift = 0 : i8} : (tensor<13x21x3xf32>, tensor<13x21x3xf32>) -> tensor<13x21x3xf32>
// CHECK: %[[C:.*]] = tensor.empty[[C:.*]]
// CHECK: %[[C:.*]] = "ttir.multiply"[[C:.*]]
return %0 : tensor<13x21x3xf32>
}
}
观察可知,tosa.mul 被转换成了 ttir.multiply,与 linalg 方言下降不同,tosa 方言的下降更接近于一一映射。
从 TTIR 下降到 TTMetal/TTKernel
使用 ttmlir-opt 将矩阵乘的 TTIR 下降到 TTMetal/TTKernel,命令如下:
ttmlir-opt --ttir-to-ttmetal-backend-pipeline \
test/ttmlir/Dialect/TTNN/simple_multiply.mlir
以下是矩阵乘函数的 ttir ir 文件,其中 %0 创建了一个新的 tensor,%1 调用了 ttir.multiply op 执行矩阵乘操作。
#any_device = #tt.operand_constraint<dram|l1|scalar|tile|any_device|any_device_tile>
module attributes {tt.system_desc = #tt.system_desc<[{arch = <wormhole_b0>, grid = <8x8>, l1_size = 1048576, num_dram_channels = 12, dram_channel_size = 1048576, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32}], [0], [<pcie|host_mmio>], [<0, 0, 0, 0>]>} {
func.func @forward(%arg0: tensor<64x128xf32>, %arg1: tensor<64x128xf32>) -> tensor<64x128xf32> {
%0 = tensor.empty() : tensor<64x128xf32>
%1 = "ttir.multiply"(%arg0, %arg1, %0) <{operandSegmentSizes = array<i32: 2, 1>, operand_constraints = [#any_device, #any_device, #any_device]}> : (tensor<64x128xf32>, tensor<64x128xf32>, tensor<64x128xf32>) -> tensor<64x128xf32>
return %1 : tensor<64x128xf32>
}
}
生成的 IR 文件如下所示:
#l1_ = #tt.memory_space<l1>
#system = #tt.memory_space<system>
#layout = #tt.layout<(d0, d1) -> (d0, d1), undef, <1x1>, memref<64x128xf32, #system>>
#layout1 = #tt.layout<(d0, d1) -> (d0, d1), undef, <1x1>, memref<64x128xf32, #l1_>>
module attributes {tt.device = #tt.device<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>, tt.system_desc = #tt.system_desc<[{arch = <wormhole_b0>, grid = 8x8, l1_size = 1048576, num_dram_channels = 12, dram_channel_size = 1048576, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32}], [0], [<pcie|host_mmio>], [<0, 0, 0, 0>]>} {
func.func @forward(%arg0: tensor<64x128xf32, #layout>, %arg1: tensor<64x128xf32, #layout>) -> tensor<64x128xf32, #layout> attributes {tt.arg_alloc = [#tt.arg_alloc<0, 32768, system>, #tt.arg_alloc<0, 32768, system>]} {
%0 = "ttmetal.alloc"() <{address = 262144 : i64, memory_space = #l1_, size = 32768 : i64}> : () -> tensor<64x128xf32, #layout1>
%1 = "ttmetal.host_write"(%arg0, %0) : (tensor<64x128xf32, #layout>, tensor<64x128xf32, #layout1>) -> tensor<64x128xf32, #layout1>
%2 = "ttmetal.alloc"() <{address = 294912 : i64, memory_space = #l1_, size = 32768 : i64}> : () -> tensor<64x128xf32, #layout1>
%3 = "ttmetal.host_write"(%arg1, %2) : (tensor<64x128xf32, #layout>, tensor<64x128xf32, #layout1>) -> tensor<64x128xf32, #layout1>
%4 = "ttmetal.alloc"() <{address = 327680 : i64, memory_space = #l1_, size = 32768 : i64}> : () -> tensor<64x128xf32, #layout1>
%5 = "ttmetal.dispatch"(%1, %3, %4) <{core_ranges = [#ttmetal.core_range<0x0, 1x1>, #ttmetal.core_range<0x0, 1x1>, #ttmetal.core_range<0x0, 1x1>], operandSegmentSizes = array<i32: 2, 1>, operand_cb_port_mapping = [0, 1, 2], threadTypes = [#ttkernel.thread<noc0>, #ttkernel.thread<noc1>, #ttkernel.thread<tensix>]}> ({
^bb0(%arg2: !ttkernel.cb<0, 0, memref<64x128xf32, #l1_>>, %arg3: !ttkernel.cb<0, 1, memref<64x128xf32, #l1_>>, %arg4: !ttkernel.cb<0, 2, memref<64x128xf32, #l1_>>):
"ttkernel.cb_push_back"(%arg2) : (!ttkernel.cb<0, 0, memref<64x128xf32, #l1_>>) -> ()
"ttkernel.return"() : () -> ()
}, {
^bb0(%arg2: !ttkernel.cb<0, 0, memref<64x128xf32, #l1_>>, %arg3: !ttkernel.cb<0, 1, memref<64x128xf32, #l1_>>, %arg4: !ttkernel.cb<0, 2, memref<64x128xf32, #l1_>>):
"ttkernel.cb_push_back"(%arg3) : (!ttkernel.cb<0, 1, memref<64x128xf32, #l1_>>) -> ()
"ttkernel.return"() : () -> ()
}, {
^bb0(%arg2: !ttkernel.cb<0, 0, memref<64x128xf32, #l1_>>, %arg3: !ttkernel.cb<0, 1, memref<64x128xf32, #l1_>>, %arg4: !ttkernel.cb<0, 2, memref<64x128xf32, #l1_>>):
"ttkernel.builtin"(%arg2, %arg3, %arg4) <{kind = @eltwise, op = @mulitply}> : (!ttkernel.cb<0, 0, memref<64x128xf32, #l1_>>, !ttkernel.cb<0, 1, memref<64x128xf32, #l1_>>, !ttkernel.cb<0, 2, memref<64x128xf32, #l1_>>) -> ()
"ttkernel.return"() : () -> ()
}) : (tensor<64x128xf32, #layout1>, tensor<64x128xf32, #layout1>, tensor<64x128xf32, #layout1>) -> tensor<64x128xf32, #layout1>
"ttmetal.dealloc"(%2) : (tensor<64x128xf32, #layout1>) -> ()
"ttmetal.dealloc"(%0) : (tensor<64x128xf32, #layout1>) -> ()
%6 = "ttmetal.alloc"() <{address = 0 : i64, memory_space = #system, size = 32768 : i64}> : () -> tensor<64x128xf32, #layout>
%7 = "ttmetal.host_read"(%5, %6) : (tensor<64x128xf32, #layout1>, tensor<64x128xf32, #layout>) -> tensor<64x128xf32, #layout>
"ttmetal.dealloc"(%4) : (tensor<64x128xf32, #layout1>) -> ()
return %7 : tensor<64x128xf32, #layout>
}
}
观察可知,生成的方言分成两个部分:
-
ttmetal.* :TTMetal 方言,负责申请内存,写入输入数据,并发射内核代码。
-
ttkernel.*:负责操作 circler buffer,并调用内建函数 ttkernel.builtin,展开如下所示:
"ttkernel.builtin"(%arg2, %arg3, %arg4) \
<{kind = @eltwise, op = @mulitply}> : \
(!ttkernel.cb<0, 0, memref<64x128xf32, #l1_>>, \
!ttkernel.cb<0, 1, memref<64x128xf32, #l1_>>, \
!ttkernel.cb<0, 2, memref<64x128xf32, #l1_>>) -> ()
具体的 op 是 multiply,参数是 l1 上的 circler buffer。其中并没有寄存器(SrcA、SrcB、dst)的相关操作,而且和 TT-Metal api 的 mul_tiles 并不一致,由此可知,TT-Kernel 无法和 TTNN 一样简单的翻到 EmitC,mul_tiles 函数原型 如下所示:
void ckernel::mul_tiles(uint32_t icb0, uint32_t icb1,\
uint32_t itile0, uint32_t itile1, uint32_t idst);
从 TTIR 下降到 TTNN
使用 ttmlir-opt 将矩阵乘的 TTIR 下降到 TTNN,命令如下:
ttmlir-opt --ttir-to-ttnn-backend-pipeline \
test/ttmlir/Dialect/TTNN/simple_multiply.mlir
下降后的 TTNN 方言文件如下所示:
#l1_ = #tt.memory_space<l1>
#system = #tt.memory_space<system>
#layout = #tt.layout<(d0, d1) -> (d0, d1), undef, <1x1>, memref<64x128xf32, #system>>
#layout1 = #tt.layout<(d0, d1) -> (d0, d1), undef, <8x8>, memref<8x16xf32, #system>>
#layout2 = #tt.layout<(d0, d1) -> (d0, d1), undef, <8x8>, memref<8x16xf32, #l1_>>
module attributes {tt.device = #tt.device<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>, tt.system_desc = #tt.system_desc<[{arch = <wormhole_b0>, grid = 8x8, l1_size = 1048576, num_dram_channels = 12, dram_channel_size = 1048576, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32}], [0], [<pcie|host_mmio>], [<0, 0, 0, 0>]>} {
func.func @forward(%arg0: tensor<64x128xf32, #layout>, %arg1: tensor<64x128xf32, #layout>) -> tensor<64x128xf32, #layout1> {
%0 = "ttnn.open_device"() : () -> !tt.device<<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>>
%1 = "ttnn.full"(%0) <{fillValue = 0.000000e+00 : f32}> : (!tt.device<<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>>) -> tensor<64x128xf32, #layout2>
%2 = "ttnn.to_memory_config"(%arg0, %1) : (tensor<64x128xf32, #layout>, tensor<64x128xf32, #layout2>) -> tensor<64x128xf32, #layout2>
%3 = "ttnn.full"(%0) <{fillValue = 0.000000e+00 : f32}> : (!tt.device<<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>>) -> tensor<64x128xf32, #layout2>
%4 = "ttnn.to_memory_config"(%arg1, %3) : (tensor<64x128xf32, #layout>, tensor<64x128xf32, #layout2>) -> tensor<64x128xf32, #layout2>
%5 = "ttnn.full"(%0) <{fillValue = 0.000000e+00 : f32}> : (!tt.device<<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>>) -> tensor<64x128xf32, #layout2>
%6 = "ttnn.multiply"(%2, %4, %5) <{operandSegmentSizes = array<i32: 2, 1>}> : (tensor<64x128xf32, #layout2>, tensor<64x128xf32, #layout2>, tensor<64x128xf32, #layout2>) -> tensor<64x128xf32, #layout2>
%7 = "ttnn.full"(%0) <{fillValue = 0.000000e+00 : f32}> : (!tt.device<<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>>) -> tensor<64x128xf32, #layout1>
%8 = "ttnn.to_memory_config"(%6, %7) : (tensor<64x128xf32, #layout2>, tensor<64x128xf32, #layout1>) -> tensor<64x128xf32, #layout1>
"ttnn.close_device"(%0) : (!tt.device<<#tt.grid<8x8, (d0, d1) -> (0, d0, d1)>, [0]>>) -> ()
return %8 : tensor<64x128xf32, #layout1>
}
}
可以看出,ttir.multiply 被转换为 ttnn.multiply。此外,还通过默认添加的 pass,在函数的前后自动插入了打开设备 (ttnn.open_device) 和关闭设备 (ttnn.close_device) 的操作。
从 TTNN 下降到 EmitC
使用 ttmlir-opt 将矩阵乘的 TTNN 下降到 EmitC,命令如下:
ttmlir-opt --convert-ttnn-to-emitc ttnn.mlir\
-o emitc.mlir
下降后的 EmitC 方言文件如下所示:
module attributes {tt.system_desc = #tt.system_desc<[{arch = <wormhole_b0>, grid = <8x8>, l1_size = 1048576, num_dram_channels = 12, dram_channel_size = 1048576, noc_l1_address_align_bytes = 16, pcie_address_align_bytes = 32, noc_dram_address_align_bytes = 32}], [0], [<pcie|host_mmio>], [<0, 0, 0, 0>]>} {
emitc.include "ttnn/device.h"
emitc.include "ttnn/operations/eltwise/binary/binary.hpp"
emitc.include "ttnn/operations/core.hpp"
emitc.include "ttnn/operations/creation.hpp"
emitc.include "ttnn/operations/reduction/generic/generic_reductions.hpp"
emitc.include "ttnn/operations/normalization.hpp"
func.func @forward(%arg0: !emitc.opaque<"ttnn::Tensor">, %arg1: !emitc.opaque<"ttnn::Tensor">) -> !emitc.opaque<"ttnn::Tensor"> {
%0 = emitc.call_opaque "ttnn::open_device"() : () -> !emitc.opaque<"ttnn::Device">
%1 = emitc.call_opaque "ttnn::full"(%0) : (!emitc.opaque<"ttnn::Device">) -> !emitc.opaque<"ttnn::Tensor">
%2 = emitc.call_opaque "ttnn::to_memory_config"(%arg0, %1) : (!emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">) -> !emitc.opaque<"ttnn::Tensor">
%3 = emitc.call_opaque "ttnn::full"(%0) : (!emitc.opaque<"ttnn::Device">) -> !emitc.opaque<"ttnn::Tensor">
%4 = emitc.call_opaque "ttnn::to_memory_config"(%arg1, %3) : (!emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">) -> !emitc.opaque<"ttnn::Tensor">
%5 = emitc.call_opaque "ttnn::full"(%0) : (!emitc.opaque<"ttnn::Device">) -> !emitc.opaque<"ttnn::Tensor">
%6 = emitc.call_opaque "ttnn::multiply"(%2, %4, %5) : (!emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">) -> !emitc.opaque<"ttnn::Tensor">
%7 = emitc.call_opaque "ttnn::full"(%0) : (!emitc.opaque<"ttnn::Device">) -> !emitc.opaque<"ttnn::Tensor">
%8 = emitc.call_opaque "ttnn::to_memory_config"(%6, %7) : (!emitc.opaque<"ttnn::Tensor">, !emitc.opaque<"ttnn::Tensor">) -> !emitc.opaque<"ttnn::Tensor">
emitc.call_opaque "ttnn::close_device"(%0) : (!emitc.opaque<"ttnn::Device">) -> ()
return %8 : !emitc.opaque<"ttnn::Tensor">
}
}
其中,主要使用的 emitc op 有:
-
emitc.include:用于包含头文件
-
emitc.call_opaque:用于调用函数
从 TTMetal/TTKernel 下降到 EmitC
前文提到,TTMetal/TTKernel 方言和 TT-Metal api 无法完全对应起来,所以并不能很简单下降到 EmitC,相关的下降 pass 尚在开发中。可以预见的是,TTMetal/TTKernel 的下降过程和 TTNN 的下降过程是类似的。
可执行文件生成
将 EmitC 翻译成 c 文件
对于 EmitC 方言文件,通过 ttmlir-translate 工具可以将其翻译成 C 文件,命令如下:
ttmlir-translate -mlir-to-cpp \
-allow-unregistered-dialect emitc.mlir
翻译后的 C 文件如下所示:
#include "ttnn/device.h"
#include "ttnn/operations/eltwise/binary/binary.hpp"
#include "ttnn/operations/core.hpp"
#include "ttnn/operations/creation.hpp"
#include "ttnn/operations/reduction/generic/generic_reductions.hpp"
#include "ttnn/operations/normalization.hpp"
ttnn::Tensor forward(ttnn::Tensor v1, ttnn::Tensor v2) {
ttnn::Device v3 = ttnn::open_device(); // 打开设备
ttnn::Tensor v4 = ttnn::full(v3); // 填充
ttnn::Tensor v5 = ttnn::to_memory_config(v1, v4);// 内存配置
ttnn::Tensor v6 = ttnn::full(v3);// 填充
ttnn::Tensor v7 = ttnn::to_memory_config(v2, v6);// 内存配置
ttnn::Tensor v8 = ttnn::full(v3); // 填充
ttnn::Tensor v9 = ttnn::multiply(v5, v7, v8); // 乘积
ttnn::Tensor v10 = ttnn::full(v3); // 填充
ttnn::Tensor v11 = ttnn::to_memory_config(v9, v10); // 内存配置
ttnn::close_device(v3); // 关闭设备
return v11;
}
观察可知,生成了调用 TTNN api 的文件,此类文件可以无缝对接 TT-Metal 框架,复用 TT-Metal 的动态库和编译器将其翻译成可执行文件。详细的 TTNN 实现方法和翻译过程请参见前文。
以上流程从图 IR 导入 TTIR,再通过 TTIR 方言降级到 TTNN/TT-Metal 方言,随后降级到 EmitC 方言,最终转换为 C 文件。此过程有效对接了 TT-Metal 框架,通过最大限度地复用 TT-Metal 现有框架的内容,减少了编译器的工作量。
从AI框架到芯片端到端的编译
以下是使用 tt-mlir python 库开发的一个示例:
from ttmlir.ir import *
from ttmlir.dialects import tt
ctx = Context()
tt.register_dialect(ctx)
def createTensorLayout( #张量声明
shape,
grid,
memorySpace=tt.ir.MemorySpace.DeviceL1,
collapseIntervals=[(0, -1)],
oobVal=tt.ir.OOBVal.Undef,
):
if isinstance(grid, list) or isinstance(grid, tuple):
grid = tt.ir.GridAttr.get(ctx, list(grid))
tensorTy = RankedTensorType.get(
shape, F32Type.get(ctx), None, Location.unknown(ctx)
)
layout = tt.ir.LayoutAttr.get(
ctx, tensorTy, memorySpace, grid, collapseIntervals, oobVal
)
return RankedTensorType.get(shape, F32Type.get(ctx), layout, Location.unknown(ctx))
def tilize(tensor, dataType, tileShape=[32, 32]): #tiling分片操作
assert len(tileShape) == 2
return tt.ir.LayoutAttr.with_element_type_(
ctx,
tensor.encoding,
tt.ir.TileType.get(ctx, tileShape[0], tileShape[1], dataType),
)
def parallelize(tensor, grid, collapseIntervals=[(0, -1)]): #并行操作
if isinstance(grid, list) or isinstance(grid, tuple):
grid = tt.ir.GridAttr.get(ctx, list(grid))
return tt.ir.LayoutAttr.with_grid_(
ctx, tensor.encoding, tensor.shape, grid, collapseIntervals
)
t0 = createTensorLayout([2, 3, 64, 128], [2, 4]) #声明张量
print(t0)#打印张量
print(tilize(t0, tt.ir.DataType.BFP_BFloat8).wrapped())#tiling操作
print(parallelize(t0, [3, 2]).wrapped())#并行操作
t1 = createTensorLayout([2, 3, 64, 128], [2, 2, 4], collapseIntervals=[(1, -1)])#声明张量
print(tilize(t1, tt.ir.DataType.BFP_BFloat8).wrapped())#tiling操作
print(parallelize(t1, [3, 2]).wrapped())#并行操作
观察可知,包含以下部分:
-
createTensorLayout(): 张量声明函数 -
tilize(): 进行张量分片(tiling) -
parallelize(): 实现张量的并行处理 -
print(): 打印张量分片和并行过程的结果
经过 buda compiler 编译后,如下所示:
tensor<2x3x64x128xf32, #tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <2x4>, memref<192x32xf32, #tt.memory_space<l1>>>>//张量声明
#tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <2x4>, memref<6x1x!tt.tile<32 x 32, bfp_bf8>, #tt.memory_space<l1>>> //tiling操作
#tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <3x2>, memref<128x64xf32, #tt.memory_space<l1>>>//并行操作
#tt.layout<(d0, d1, d2, d3) -> (d0, d1 * 64 + d2, d3), undef, <2x2x4>, memref<1x3x1x!tt.tile<32 x 32, bfp_bf8>, #tt.memory_space<l1>>>//tiling操作
#tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <3x2>, memref<128x64xf32, #tt.memory_space<l1>>>//并行操作
分析生成的代码:
-
张量声明操作
tensor<2x3x64x128xf32, #tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <2x4>, memref<192x32xf32, #tt.memory_space<l1>>>> -
分片操作:
#tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <2x4>, memref<6x1x!tt.tile<32 x 32, bfp_bf8>, #tt.memory_space<l1>>> -
并行操作操作:
#tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <3x2>, memref<128x64xf32, #tt.memory_space<l1>>> -
分片操作:
#tt.layout<(d0, d1, d2, d3) -> (d0, d1 * 64 + d2, d3), undef, <2x2x4>, memref<1x3x1x!tt.tile<32 x 32, bfp_bf8>, #tt.memory_space<l1>>> -
并行操作:
#tt.layout<(d0, d1, d2, d3) -> (d0 * 192 + d1 * 64 + d2, d3), undef, <3x2>, memref<128x64xf32, #tt.memory_space<l1>>>
总结
本文介绍了 TT-MLIR,一个为 Tenstorrent AI 加速卡设计的 AI 编译器框架。文章首先讨论了传统 TT-Buda 和 TT-Metal 框架中的问题,随后阐述了 TT-MLIR 的整体架构、组件抽象及编译流程。接着,展示了如何在算子或数据维度上优化计算能力,并通过案例说明了模型如何在编译器中转换为 Dataflow 芯片可部署的代码,以及如何实现端到端编译。
TT-MLIR 将不同层次解耦为不同的中间表示(IR),根据底层 API 分类为不同的方言,体现了模块化设计的优势。这种设计吸收了 TT-Metal 的优化优势,同时解决了 TT-Buda 中算子添加困难的问题,提升了性能优化能力。此外,TT-MLIR 利用 MLIR 的自动生成特性,简化了部署过程,解决了 TT-Metal 中复杂的部署问题。
TT-MLIR 为用户提供了高效的编译工具,改进了 AI 模型的部署和优化流程。它展示了强大的兼容性,支持不同输入和异构硬件输出。作为一个新兴项目,TT-MLIR 具有巨大潜力,未来将为用户提供更快速、便利的 AI 性能优化工具。希望读者深入探索 TT-MLIR 的架构和功能,以应对 AI 开发中的挑战。
本文章的信息有效期至2024年7月,请读者注意架构变化可能导致的信息更新。
参考资料:
-
TT-MLIR 官方文档 Introduction - tt-mlir documentation
-
TT-MLIR github 仓库 GitHub - tenstorrent/tt-mlir: Tenstorrent MLIR compiler
-
TT-Metal上层API APIs — TT-Metalium documentation
-
TTNN API APIs — TT-NN documentation
-
TT-Buda API API Reference — TT Buda documentation
-
TT-MLIR 官方文档 Introduction - tt-mlir documentation
-
TT-MLIR github 仓库 GitHub - tenstorrent/tt-mlir: Tenstorrent MLIR compiler