引言
Dataflow架构
Dataflow架构是一种计算架构,它通过数据流动来驱动计算过程,而非常规指令流动。与传统的冯·诺依曼架构不同,Dataflow架构强调并行(流水)处理和数据驱动的执行模型。
-
定义与基本概念:在Dataflow架构中,程序被表示为一个数据流图(Dataflow Graph), 其中节点代表计算操作,边代表数据依赖关系。每个节点在其所有输入数据准备好后立即执行,并将结果传递给下游节点。
-
Dataflow架构的历史背景:Dataflow架构的概念最早可以追溯到20世纪60年代和70年代,当时研究人员开始探索如何通过并行处理提高计算性能。MIT的Tagged Token Dataflow和曼彻斯特大学的Dataflow Machine是早期的经典实现。
冯·诺依曼架构
冯·诺依曼架构是现代计算机系统的基础架构,由约翰·冯·诺依曼在20世纪40年代提出。它采用存储程序的概念,即程序指令和数据存储在同一个存储器中,并通过中央处理单元(CPU)逐条执行指令。
-
基本概念:冯·诺依曼架构包括五个主要部分:输入设备、输出设备、存储器、算术逻辑单元(ALU)和控制单元。程序指令和数据存储在存储器中,CPU从存储器中读取指令并执行。
-
指令周期:冯·诺依曼架构的执行过程大致可以分为取指、译码、执行,访存和写回5个阶段。每个指令按顺序执行,形成一个指令周期。
Dataflow架构与冯·诺依曼架构的对比
Dataflow架构与冯·诺依曼架构在执行模型、并行处理能力和能效等方面存在显著差异。
-
执行模型:
-
冯·诺依曼架构:采用顺序执行模型,指令按顺序从存储器中读取并执行。每条指令的执行依赖于前一条指令的完成。
-
Dataflow架构:采用数据驱动的执行模型,节点在其所有输入数据准备好后立即执行。多个节点可以并行执行,只要数据依赖关系允许。
-
-
并行处理能力:
-
冯·诺依曼架构:并行处理能力有限,主要依赖于多核处理器和超标量技术来提高并行性 (GPU除外)。
-
Dataflow架构:天然支持并行处理,多个独立的计算操作可以同时执行,从而显著提高计算性能。
-
-
能效比:
-
冯·诺依曼架构:由于指令调度和控制开销较大,而且访存过于频繁(访存的能耗约为ALU运算的20倍左右),所以能效比相对较低。
-
Dataflow架构:避免了传统架构中的指令调度和控制开销,每个节点只在需要时执行,减少了不必要的计算和数据传输,能效比更高。
-
以下是卷积在冯·诺依曼架构和Dataflow架构下的执行过程:
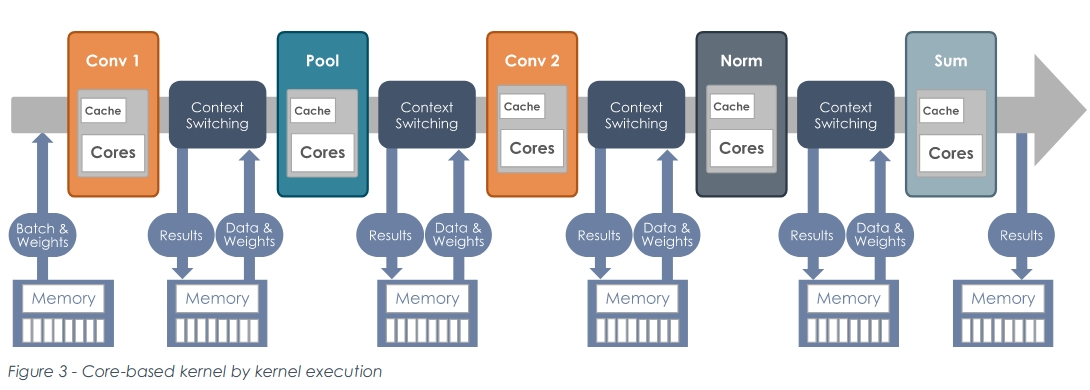
图 1:卷积在传统的架构下程序执行过程 (来源:【6】)
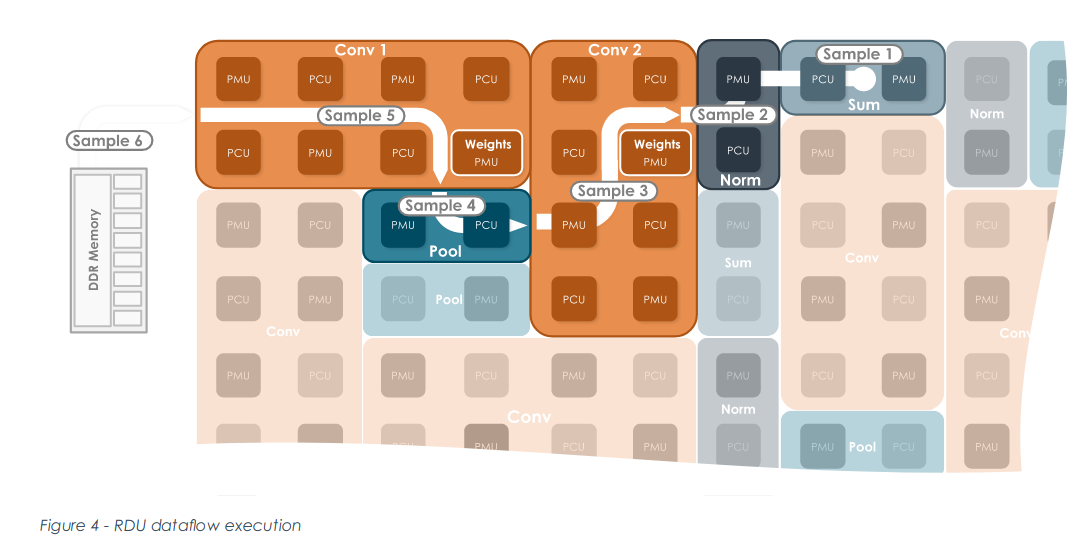
图 2:卷积在数据流架构下程序执行过程 (来源:【6】)
比较分析上述过程,可以发现,除了指令驱动和数据驱动的区别之外,还有一个重要的区别,计算的中间数据不需要写回内存。
时代背景
摩尔定律(Moore’s Law)和登纳德缩放定律(Dennard Scaling)的终结
随着著名的摩尔定律和登纳德缩放比例定律走到尽头,“暗硅”现象阻挡了晶体管密度的进一步增加,同时人工智能的高速发展对算力提出了更高要求,硬件如何满足算力的需求是一大挑战。
通用性 vs 专一性
通用芯片设计用于满足多种不同应用的需求,具有较广泛的适用性,但是往往效率不高。通过设计DSA(Domain-Specific Architecture 领域专用架构),为特定应用领域定制化,以牺牲应用范围为代价,可以获取效率的提升。
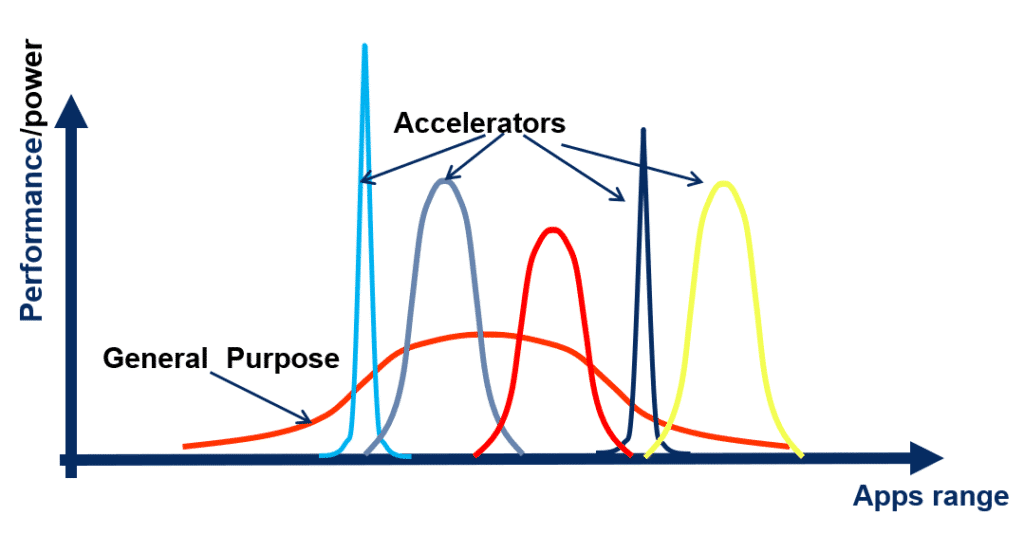
图 3. 处理器效率和应用范围灵活性的权衡
内存墙问题
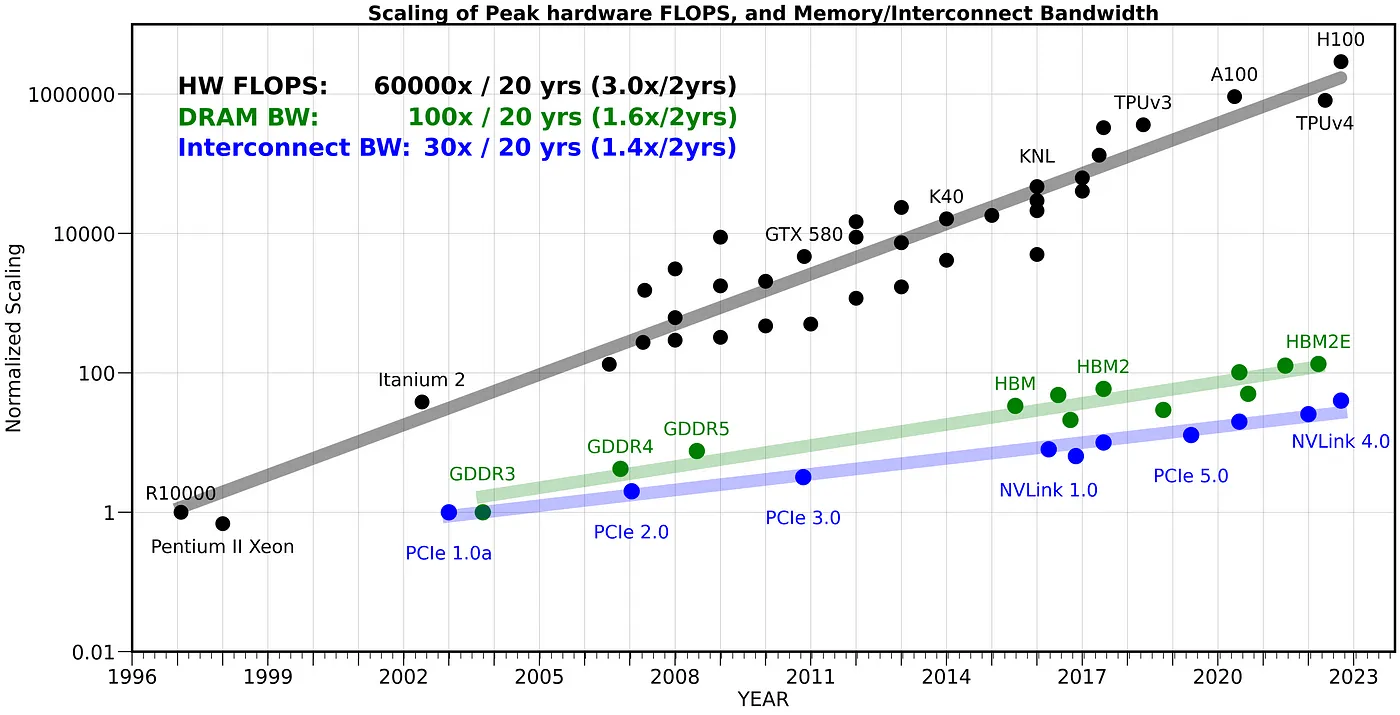
图 4:算力和内存的发展不平衡
多年以来,随着处理器速度的不断提高,从内存访问数据的速度却未能跟上,二者之间的差距越来越大,从而导致处理器花费大量时间等待从内存中获取数据的瓶颈,造成内存墙问题。
人工智能算法,特别是深度学习模型,需要大量的数据处理,频繁的访问存储在内存中的数据。 随着这些模型变得越来越复杂,并且它们所操作的数据集越来越大,内存墙问题变得越来越明显,导致了严重的性能瓶颈。
为了满足AI算力的需求,解决内存墙问题,使用专业化的芯片(AI加速器)来加速AI应用是必然的趋势。
Dataflow架构的理论基础
数据流图(Dataflow Graph)
数据流图(Dataflow Graph)是Dataflow架构的核心表示方法,它用图的形式表示计算任务和数据依赖关系。
-
节点与边:节点(Node)代表计算操作(如加法、乘法等),边(Edge)表示数据在节点之间的流动。
-
构建数据流图:通过分析程序代码,消除控制流,生成节点和边,形成一个完整的计算图。
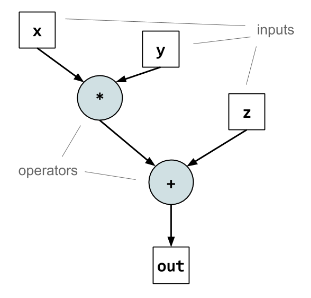
图 5:Dataflow graph example
数据流模型
数据流模型决定了数据在架构中的流动方式,主要分为静态数据流模型和动态数据流模型。
-
静态数据流模型:数据流图在编译时就完全确定,节点和边的连接关系固定。这种模型简单易实现,但灵活性较差。
-
动态数据流模型:数据流图在运行时可以动态变化,允许根据实际情况调整节点和边的连接关系,提供更高的灵活性和适应性。
硬件实现
硬件实现是Dataflow架构的关键部分,涉及处理单元、互连网络和存储器架构的设计。
-
处理单元(Processing Elements, PEs):每个PE负责执行特定的计算任务,通常包含算术逻辑单元(ALU)、寄存器文件和本地存储器。
-
互连网络(Interconnection Network):连接PEs的网络,决定了数据传输的效率和延迟。常见拓扑结构包括总线、环形和网格。
-
存储器架构:Dataflow架构通常采用分层存储结构,包括:
-
本地存储器:每个处理单元(PE)都有自己的本地存储器(一般是SRAM),用于存储中间结果和权重数据。本地存储器访问速度快,能耗低。
-
片上共享存储器:多个PE共享一个片上共享存储器,用于存储全局数据。共享存储器可以在PE之间传递数据。
-
片外存储器:如DRAM等外部存储器,用于存储大规模的输入数据和模型参数。
-
编译器与工具链
编译器在Dataflow架构中扮演着重要角色,它负责将高层次的源代码转换为数据流图,并进行优化和代码生成。
-
源代码到数据流图的转换:编译器首先解析源代码,生成中间表示,然后将中间表示转换为数据流图。
-
优化与代码生成:编译器通过各种优化技术提高数据流图的性能,包括循环展开、软件流水线和数据流图优化等;最终,编译器生成目标代码,供处理单元执行。
Dataflow架构的芯片实现案例
随着人工智能(AI)算力需求的爆炸性增长和AI加速器市场的快速扩张,许多创业公司涌现出来,专注于开发高效的AI加速器。Dataflow架构是其中一个重要的方向,Groq、SambaNova、Tenstorrent等这些知名创业公司都选择了使用Dataflow架构研发自己的AI加速器。
TPU(Tensor Processing Unit)
TPU v1
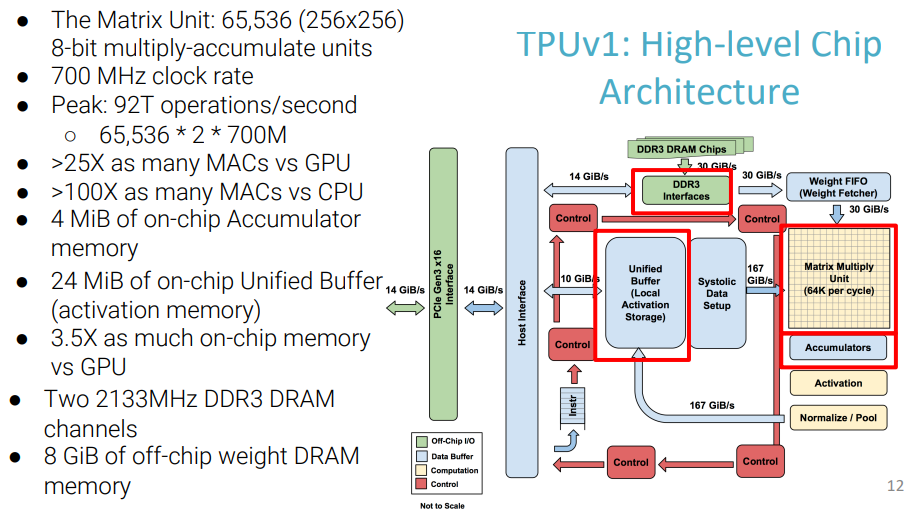
图 6: TPUv1架构(来源:【7】)
TPU(Tensor Processing Unit)是由Google开发的一种专用AI加速器,专门用于加速深度学习任务。
TPU包括以下计算资源:
-
矩阵乘法单元(MUX):65,536个8位乘法和加法单元,运行矩阵计算
-
统一缓冲(UB):作为寄存器工作的24MB容量SRAM
-
激活单元(AU):硬件实现的激活函数
TPU为了控制MUX、UB和AU进行计算,设计了十几条指令,以下是五条重要指令:
-
Read_Host_Memory – 将数据从 CPU 主机内存读取到统一缓冲区 (UB)
-
Read_Weights – 将权重从权重存储器读入权重 FIFO
-
MatrixMultiply/Convolve – 执行从统一缓冲区到累加器的矩阵乘法或卷积
-
Activate – 执行人工神经元的非线性函数
-
Write_Host_Memory – 将统一缓冲区中的数据写入 CPU 主机内存
传统CPU每次运算中都需要从多个寄存器(register)中进行存取,而TPU的脉动阵列将多个运算逻辑单元(ALU)串联在一起,复用从一个寄存器中读取的结果,从而提高了效率。
TPU v2、TPU v3
TPU v2对比TPU v1:
-
使用HBM代替DDR3,更高的带宽。
-
添加了Interconnect,提供了扩展能力(Scale Up & Scale Out)。
-
添加了General Purpose Vector Unit,替代了固定的激活单元。
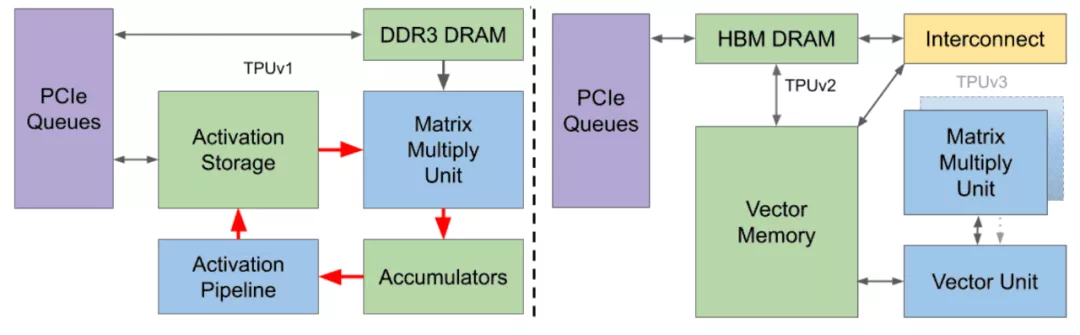
图 7: TPU v1和TPU v2/TPU v3的架构对比(来源:【8】)
TPU v4
TPU v4是Google在2020年发布的最新一代TPU,相比TPU v2和TPU v3,TPU v4在性能和能效方面进一步提升。
TPU的优势和局限
-
优势:专为深度学习优化、能效高、性能强大、与谷歌云紧密集成。
-
局限:灵活性相对较低、仅支持特定的深度学习框架(如TensorFlow)、市场可用性有限。
Groq
Groq的创始团队包括前Google工程师,他们曾参与开发Google的第一代TPU,Groq的LPU( Language Processing Unit)在TPU的架构的基础上进行开发。Groq自称架构为Software-defined Tensor Streaming Multiprocessor(TSP),突出软件定义的硬件。设计思路是将硬件尽可能的简化,然后将一切调度的工作留给软件。由于需要编译器提前规划好所有的行为,所以芯片上发生的一切操作需要有确定的延迟。分三个部分考虑:计算、访存和通信。计算的确定性是简单的;要想获得确定延迟的访存,应避免使用DRAM作为存储单元,DRAM的访问延迟是不确定的;如何获取确定性的通信则是Groq设计的重点所在。
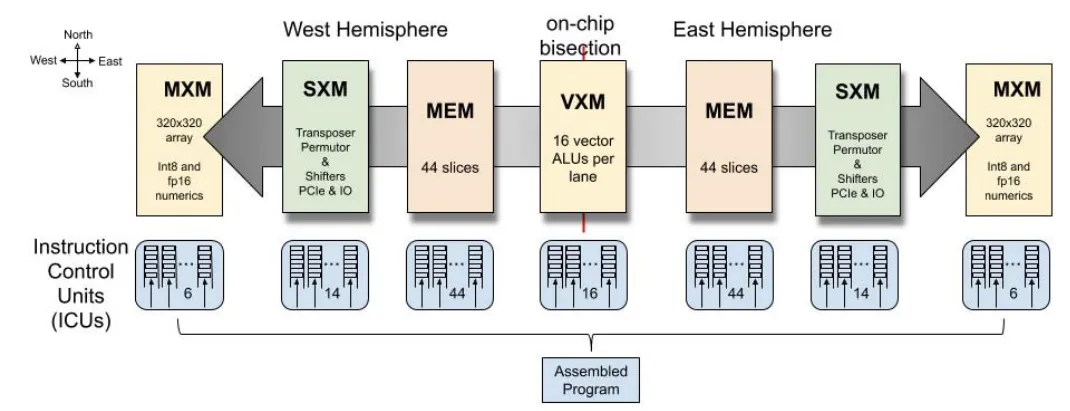
图 8: Groq TSP 执行框图(来源:Groq)
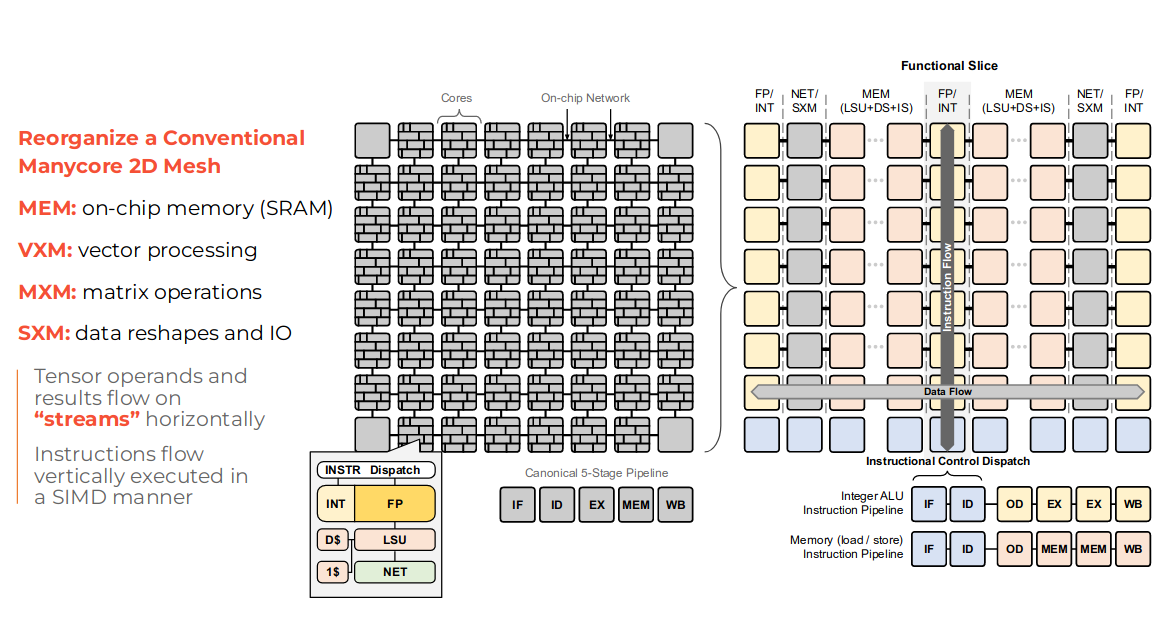
图 9: TSP功能切片微架构(来源:【5】)
SambaNova
SambaNova的架构自称为可重构数据流架构(Reconfigurable Dataflow Architecture),提供了灵活的数据流执行模型,可对操作(op)进行流水线处理,实现可编程数据访问模式,并最大限度地减少多余数据移动。
RDU(Reconfigurable Dataflow Unit)的组成:
-
PCU(Pattern Compute Unit 模式计算单元)-- 执行单个最内部并行操作。
-
PMU(Pattern Memory Unit 模式内存单元)-- 提供片上存储器容量并执行许多专门的智能功能。
-
S(Switch 交换结构)-- 连接PCU和PMU的高速交换结构由标量、矢量和控制三种交换网络组成。
-
Address Generator Units (AGU) and Coalescing Units (CU) – RDU 和系统其余部分之间的互连,包括片外 DRAM、其他 RDU 和主机处理器。
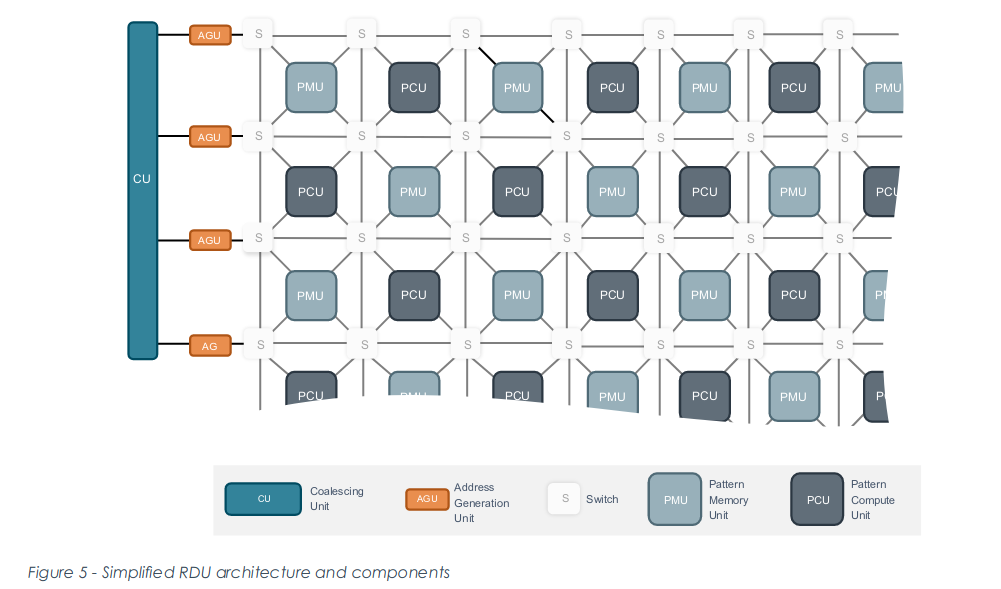
图 10:RDU(Reconfigurable Dataflow Unit)架构 (来源:【6】)
当程序启动时,SambaFlow会执行一次配置,将整个模型映射到RDU。整个系统组成一个pipeline,RDU的不同部分执行模型的不同层,如图2所示。
Tenstorrent
Tenstorrent是一家成立于2016年的AI加速器公司,总部位于加拿大多伦多。该公司由前 AMD Ljubisa Bajic、Milos Trajkovic 和 Ivan Hamer 创立,Jim Keller 于2021 年 1 月加入,现担任CEO,公司致力于开发高性能、可扩展的AI处理器,以满足不断增长的AI算力需求。
Tenstorrent先后开发了Grayskull、Wormhole、BlackHole三代产品,自第二代产品Wormhole开始,片上网络 (NoC) 可以通过以太网端口进行多卡互联(scale out)。
Tenstorrent的AI加速器技术特点(以Wormhole为例):
-
高并行性:Wormhole处理器包含上百个计算单元,能够同时执行大规模的并行计算任务。
-
可扩展性:通过模块化设计,Wormhole处理器可以轻松扩展计算资源,满足不同规模的AI任务需求。多个Wormhole处理器可以通过高速互连网络连接在一起,形成一个强大的计算集群。
-
高效数据流控制:Wormhole处理器采用先进的数据流控制机制,能够高效管理数据传输和处理,减少数据依赖和延迟。
Tenstorrent使用RISC-V ISA作为基础计算核心架构(Tensix core),计算单元之间通过片上网络(NoC)互联。架构如下图所示:

图 11:Tenstorrent Wormhole 架构 (来源:Tenstorrent)
软件方面,Tenstorrent开源了两套软件开发框架:
-
tt-metal 自下而上的框架,面向底层开发者
tt-metal 提供了一套底层API,这些API能直接操作底层硬件(譬如:RISC-V内核、NoC、矩阵和矢量引擎等)。开发者可以使用底层API实现自定义的算子、自定义跨核的数据流动,也可以开发非AI的程序。
-
tt-buda 自上而下的框架,面向上层AI开发者
tt-buda包含frontend、backend两大部分。frontend调用TVM编译器将AI模型翻译成计算图,然后对图做优化、平衡,最后映射到硬件的计算单元。这种操作(op)和硬件的映射关系表现为网表格式(netlist,可以理解为一种中间的配置文件)。Backend根据网表生成可执行文件和路由文件。
后续教程中,将会详细介绍Tenstorrent的硬件和软件。
AI加速器领域的竞争者
AI加速器领域除了新的挑战者(Dataflow架构芯片)以外,还有GPU这种成熟的方案。
GPU
GPU虽然也是冯诺依曼架构,但是去除了CPU中的分支预测、乱序执行等模块,遵循SIMT(Single Instruction Multiple Thread)的编程模型,同一条指令可以同时在多个线程上执行,极大的增强了并行性,更加适应于需要大量并行计算的任务,譬如图像处理和神经网络。
除了并行性以外,GPU作为AI加速器还有以下特性:
专用硬件加速:Nvidia开发了张量核心(tensor core)针对矩阵乘法进行了优化,而矩阵乘法是神经网络中最基本、最常用的计算。
内存带宽:Nvidia使用高带宽HBM降低了“内存墙”的影响。
可扩展性:Nvidia开发了nvlink技术用于解决GPU之间的通讯,方便进行GPU集群(大模型的参数指数型增长,单张卡已经无法满足算力需求,集群是不可避免的趋势)。
GPU在AI加速器市场上占据了主导地位,除了上述的硬件优势以外,软件也起到了关键作用。因为神经网络兴起之初,就使用GPU作为加速器,导致现有大量的算子使用cuda进行开发。上层的AI公司如果想更换硬件,需要将整个算子库进行迁移,算子库的开发极大的增加了硬件公司的工作量,所以才有了“cuda是Nvidia最深的护城河”的说法。针对不同硬件开发的AI算子不通用,同一个算子往往需要针对不同硬件开发不同的版本,导致了AI算子碎片化。为了解决这个问题,需要将算子的开发和硬件进行解耦。为此,OpenAI提出了Triton项目,Triton编译器可以基于Triton开发的算子翻译到不同的GPU(Nvidia、AMD);Modular推出了新的语言mojo(python的超集)和基于MLIR的编译器,我们后续会推出mojo的系列文章(https://1nfinite.ai/c/mojo/16),敬请期待。
GPU的优势与局限
-
优势:并行计算能力强、灵活性高、广泛支持各种深度学习框架(如TensorFlow、PyTorch)。
-
局限:功耗较高、价格昂贵、针对特定AI任务的优化有限、scale-out过于复杂。
更多
除了上述芯片外,AI加速器领域还有许多挑战者。譬如单晶圆芯片Cerebras(dataflow架构)、专注于边缘设备的Hailo等等。
总结和展望
使用Dataflow架构作为AI加速器的架构的优点:
-
并行计算能力:深度学习应用程序的结构天然就是计算图,从计算图映射到数据流图,然后部署到数据流芯片上,整个过程是自然的。相比之下,冯·诺依曼架构需要将图序列化,然后重新并行化。
-
高效的数据流处理:Dataflow架构通过数据驱动的执行模型,能够高效处理AI任务中的数据流动,减少不必要的计算和数据传输。
Dataflow架构的特点使得其不仅仅适合作为AI加速器,也可以用于高性能计算、物理仿真、RTL仿真等领域。
AI加速器的设计不仅是硬件设计,更需要考虑软件栈的实现。如何适应日益复杂和多样化的硬件设备,提高程序的性能,将硬件和上层软件解耦是工具链开发领域的一大挑战。
参考资料
【1】Evaluating Emerging AI/ML Accelerators: IPU, RDU, and NVIDIA/AMD GPUs https://arxiv.org/pdf/2311.04417
【2】AI and Memory Wall https://arxiv.org/pdf/2403.14123
【3】TPU, In-Datacenter Performance Analysis of a Tensor Processing Unit
【4】Groq, Think Fast: A Tensor Streaming Processor(TSP) for Accelerating Deep Learning Workloads (ISCA 2020)
【5】Groq, A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning (ISCA 2022)
【6】SambaNova Accelerated Computing with a Reconfigurable Dataflow Architecture Whitepaper
【7】TPU, TPUv1, Domain-Specific Architectures for Deep Neural Networks
【8】TPU, Ten Lessons From Three Generations Shaped Google’s TPUv4i
【9】AI Accelerators — Part V: Final Thoughts https://medium.com/@adi.fu7/ai-accelerators-part-v-final-thoughts-94eae9dbfafb