引言
在了解了当前开源 EDA 工具的碎片化现状以及 CIRCT 的创立动机和发展历程后,读者应对 CIRCT 项目为定制化硬件设计带来的优势有了基本的认识。接下来,本文将重点介绍 CIRCT 项目中的技术细节。然而,在深入探讨这些技术细节之前,我们首先为读者普及一些必要的概念——方言(dialect)。本文将重点介绍 SystemVerilog 和 Chisel 这两条技术路线所涉及的所有方言(按照层次顺序),未提及的其他方言将在后续文章中单独介绍。
方言概述
方言是与 MLIR 生态系统交互和扩展的机制。它们允许定义新的 Operations、Type System、Attributes。可用于建模各种不同的抽象,从传统的算术运算到模式重写,方言是 MLIR 中最基本的组成部分之一。
- Type System:用于映射某种语言中定义的合法类型,为 Operations 提供支持。它确保在执行 Operations 时,所有数据类型都是有效且一致的。
- Attributes:用于表示常量数据,如数字、字符以及自定义信息等。与类型不同,在通过.td 文件生成的.inc 文件中,type 会被当做 operand,而 attribute 是 properties。
- Operations:用于映射某种语言中的特性,包括变量声明、运算符、条件语句和函数声明等。它们是方言的核心,定义了程序如何在特定上下文中执行。
方言这一抽象概念是 MLIR 编译器框架的核心,每个方言都代表着不同的功能模块,例如:
- Affine:用于表示与仿射相关的操作,如 for 循环定义了循环迭代的空间;
- Arith:专注于处理整型和浮点类型的数学运算,提供丰富的算术功能;
- CF:用于表示非结构化的控制流,适用于更复杂的执行路径;
- SCF:用于表示结构化的控制流,帮助简化和优化程序逻辑;
这一设计理念使得 MLIR 具备了模块化和可扩展的特征。通过这种方式,开发者可以根据特定需求,灵活地定义新的方言或扩展现有方言,使 MLIR 能够支持多种编程模型和硬件架构。 在对方言这一抽象概念有了初步了解后,我们可以进一步探讨 CIRCT 中各个方言所代表的功能。CIRCT 项目应用了 MLIR 的方言机制,定义了多个专门用于硬件设计和编译的方言。具体如下:
- FIRRTL(Flexible Internal Representation for RTL):用于映射 Chisel 代码中的特性,并且提供了对 SFC(Scala FIRRTL Compiler)注释的强大支持,这些注释可用于编码任意元数据;
- Moore:致力于映射 SystemVerilog IEEE Std 1800-2017 中的所有特性;
- FSM:对有限状态机进行建模;
- HW:CIRCT 项目中的核心方言,专用于表示硬件设计中的公共特性。该方言定义的 Operations 不涉及组合逻辑、时序逻辑和线网之间的连接逻辑,因此具有高度的通用性,并能够与其他方言灵活结合使用。这使得 HW 方言不依赖于特定的硬件语言。例如,它可以有效地表示硬件中的 module、instance 和 port;
- Comb:CIRCT 项目中的核心方言,与 HW 方言类似,提供一种不依赖于特定硬件语言的通用表示方式。专注于表示硬件电路中的组合电路,其设计理念强调简洁性,力求用更少的 Operations 表达更多的功能。例如,通过将 x 与全 1 进行异或运算,可以有效地表示一元位运算符(~x)。
- Seq:CIRCT 项目中的核心方言,用于表示带复位信号和使能信号的寄存器逻辑。例如
seq.comreg.ce用于描述具有使能信号和复位信号的同步时序逻辑,而seq.firreg则表示带有复位信号的同步或异步时序逻辑。 - SV:专为生成 SystemVerilog 代码而设计的方言,能够与 HW 方言和 Comb 方言灵活结合使用。它以类似 AST 的格式表示 SystemVerilog 中的语法特性和行为级特性,为开发者提供一种简单且可预测的访问方式,以便高效利用这些强大的功能;
- SystemC:用 C++编写的库,允许对系统进行功能建模,同样也是一种标准(IEEE Std 1666-2011)。在 CIRCT 项目中是专为生成 C++代码而设计的方言;
- Arc:用于表示硬件电路中信号的变化状态、时钟域、时钟树等;
- LLHD:目前仅用于 SV 技术路线,专门表示那些无法从 Moore 方言降级到 Core 方言的与时序逻辑相关的 Operations。例如,时延控制、无法区分复位信号和使能信号的时序逻辑。但由于语言本身的问题,如不能像 Chisel 那样区分使能信号与复位信号,因此目前该方言承担所有的时序逻辑转换。
SystemVerilog 细节举例
组合逻辑-全加器
SV 源码:
module half_add(
input A, B, // 输入端口
output Sum, Cout // 和输出端口以及进位输出端口
);
// 计算和和进位
assign Sum = A ^ B; // 和
assign Cout = A & B; // 进位
endmodule
module full_add(
input A,B,Cin,
output Sum,Cout
);
wire w1,w2,w3;
// 实例化两个半加器
half_add add1(A, B, w1, w2);
half_add add2(.A(Cin), .B(w1), .Sum(Sum), .Cout(w3));
assign Cout = w2 | w3; // 计算最终进位
endmodule
Moore IR:
module {
moore.module private @half_add(in %A : !moore.l1, in %B : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%0 = moore.xor %A, %B : l1
%1 = moore.and %A, %B : l1
moore.output %0, %1 : !moore.l1, !moore.l1 // %0 对应out Sum, %1 对应out Cout
}
moore.module @full_add(in %A : !moore.l1, in %B : !moore.l1, in %Cin : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%w1 = moore.assigned_variable %add1.Sum : l1 // 表示 w1 这根线与 %add1.Sum 相连
%w2 = moore.assigned_variable %add1.Cout : l1 // 表示 w2 这根线与 %add1.Cout 相连
%w3 = moore.assigned_variable %add2.Cout : l1 // 表示 w3 这根线与 %add2.Cout 相连
%add1.Sum, %add1.Cout = moore.instance "add1" @half_add(A: %A: !moore.l1, B: %B: !moore.l1) -> (Sum: !moore.l1, Cout: !moore.l1) // 表示将half_add中的Sum端口的值传给 %add1.Sum,Cout端口的值传给 %add1.Count
%add2.Sum, %add2.Cout = moore.instance "add2" @half_add(A: %Cin: !moore.l1, B: %w1: !moore.l1) -> (Sum: !moore.l1, Cout: !moore.l1) // 同上
%0 = moore.or %w2, %w3 : l1
moore.output %add2.Sum, %0 : !moore.l1, !moore.l1 // %add2.Sum 对应out Sum, %0 对应out Cout
}
}
Core IR:
module {
hw.module private @half_add(in %A : i1, in %B : i1, out Sum : i1, out Cout : i1) {
%0 = comb.xor %A, %B : i1
%1 = comb.and %A, %B : i1
hw.output %0, %1 : i1, i1
}
hw.module @full_add(in %A : i1, in %B : i1, in %Cin : i1, out Sum : i1, out Cout : i1) {
// 优化掉了 w1, w2, w3 临时变量,用 %add1.Sum, %add1.Cout,%add2.Cout 分别替代
%add1.Sum, %add1.Cout = hw.instance "add1" @half_add(A: %A: i1, B: %B: i1) -> (Sum: i1, Cout: i1) {sv.namehint = "w2"}
%add2.Sum, %add2.Cout = hw.instance "add2" @half_add(A: %Cin: i1, B: %add1.Sum: i1) -> (Sum: i1, Cout: i1) {sv.namehint = "w3"}
%0 = comb.or %add1.Cout, %add2.Cout : i1
hw.output %add2.Sum, %0 : i1, i1
}
}
时序逻辑-Johnson 计数器
SV 源码:
module JS_Counter(
input clk, rst_n, // 时钟信号和复位信号
output reg [3:0] q // 输出计数值
);
always @(posedge clk or negedge rst_n) begin // 异步时序逻辑,下降沿时触发复位信号
if (!rst_n) begin
q <= 4'b0000; // 触发复位信号置为0
end else begin
q <= {~q[0],q[3:1]}; // 将最后一位取反并移位
end
end
endmodule
Moore IR:
module {
moore.module @JS_Counter(in %clk : !moore.l1, in %rst_n : !moore.l1, out q : !moore.l4) {
%0 = moore.constant 0 : l4
// 端口默认类型为logic,并且会生成 moore.net表示线网
// 如果显示标明类型,如 out reg q,生成moore.variable以表示变量
// 下列声明的 %clk_0、%rst_n_1、%q表示在module内部进行运算的线网和变量
%clk_0 = moore.net name "clk" wire : <l1>
%rst_n_1 = moore.net name "rst_n" wire : <l1>
%q = moore.variable : <l4>
moore.procedure always {
// 检测敏感列表中的信号变化
moore.wait_event {
%10 = moore.read %clk_0 : <l1>
moore.detect_event posedge %10 : l1
%11 = moore.read %rst_n_1 : <l1>
moore.detect_event negedge %11 : l1
}
%2 = moore.read %rst_n_1 : <l1>
%3 = moore.not %2 : l1
%4 = moore.conversion %3 : !moore.l1 -> i1
cf.cond_br %4, ^bb1, ^bb2 // %4为true表示触发复位逻辑,否则进入取反移位逻辑
^bb1: // pred: ^bb0
moore.nonblocking_assign %q, %0 : l4 // 非阻塞赋值 <=
cf.br ^bb3
^bb2: // pred: ^bb0
%5 = moore.read %q : <l4>
%6 = moore.extract %5 from 0 : l4 -> l1 // 表示对变量q取其第0位
%7 = moore.not %6 : l1
%8 = moore.extract %5 from 1 : l4 -> l3 // 表示对变量q取其第1位到第三位
%9 = moore.concat %7, %8 : (!moore.l1, !moore.l3) -> l4 // 连接{}运算符
moore.nonblocking_assign %q, %9 : l4
cf.br ^bb3
^bb3: // 2 preds: ^bb1, ^bb2
moore.return
}
moore.assign %clk_0, %clk : l1
moore.assign %rst_n_1, %rst_n : l1
// 读取%q的值并返回给out reg q
// % 开头的才是表示MLIR中的SSA值,out reg q中的q仅是字符串
%1 = moore.read %q : <l4>
moore.output %1 : !moore.l4
}
}
Core IR + LLHD IR:
module {
hw.module @JS_Counter(in %clk : i1, in %rst_n : i1, out q : i4) {
%0 = llhd.constant_time <0ns, 0d, 1e>
%1 = llhd.constant_time <0ns, 1d, 0e>
%true = hw.constant true
%c0_i4 = hw.constant 0 : i4
%false = hw.constant false
%clk_0 = llhd.sig name "clk" %false : i1 // 声明%clk_0变量
%2 = llhd.prb %clk_0 : !hw.inout<i1> // 读取%clk_0的值
%rst_n_1 = llhd.sig name "rst_n" %false : i1
%3 = llhd.prb %rst_n_1 : !hw.inout<i1>
%q = llhd.sig %c0_i4 : i4
llhd.process {
cf.br ^bb1
^bb1: // 4 preds: ^bb0, ^bb2, ^bb4, ^bb5
%5 = llhd.prb %clk_0 : !hw.inout<i1>
%6 = llhd.prb %rst_n_1 : !hw.inout<i1>
llhd.wait (%2, %3 : i1, i1), ^bb2 // 等待时钟信号和复位信号的变化
// 开始检测时钟信号和复位信号是否符合在时钟沿才进行跳变
^bb2: // pred: ^bb1
%7 = llhd.prb %clk_0 : !hw.inout<i1>
%8 = comb.xor bin %5, %true : i1
%9 = comb.and bin %8, %7 : i1
%10 = llhd.prb %rst_n_1 : !hw.inout<i1>
%11 = comb.xor bin %10, %true : i1
%12 = comb.and bin %6, %11 : i1
%13 = comb.or bin %9, %12 : i1
cf.cond_br %13, ^bb3, ^bb1 // 不符合预期返回^bb1重新检测,否则执行后续逻辑
// 当符合时钟信号跳变时,检测是否触发复位信号
^bb3: // pred: ^bb2
%14 = llhd.prb %rst_n_1 : !hw.inout<i1>
%15 = comb.xor %14, %true : i1
cf.cond_br %15, ^bb4, ^bb5
// 执行复位信号逻辑
^bb4: // pred: ^bb3
llhd.drv %q, %c0_i4 after %1 : !hw.inout<i4>
cf.br ^bb1
// 执行取反移位逻辑
^bb5: // pred: ^bb3
%16 = llhd.prb %q : !hw.inout<i4>
%17 = comb.extract %16 from 0 : (i4) -> i1
%18 = comb.xor %17, %true : i1
%19 = comb.extract %16 from 1 : (i4) -> i3
%20 = comb.concat %18, %19 : i1, i3
llhd.drv %q, %20 after %1 : !hw.inout<i4>
cf.br ^bb1
}
llhd.drv %clk_0, %clk after %0 : !hw.inout<i1>
llhd.drv %rst_n_1, %rst_n after %0 : !hw.inout<i1>
%4 = llhd.prb %q : !hw.inout<i4>
hw.output %4 : i4
}
}
Chisel 细节举例:
组合逻辑-全加器
scala 源码:
import chisel3._
class HalfAdder extends Module {
val io = IO(new Bundle {
val a = Input(UInt(1.W)) // 输入a
val b = Input(UInt(1.W)) // 输入b
val sum = Output(UInt(1.W)) // 和输出
val carry = Output(UInt(1.W)) // 进位输出
})
// 计算和和进位
io.sum := io.a ^ io.b // 和
io.carry := io.a & io.b // 进位
}
class FullAdder extends Module {
val io = IO(new Bundle {
val a = Input(UInt(1.W)) // 第一个输入
val b = Input(UInt(1.W)) // 第二个输入
val cin = Input(UInt(1.W)) // 进位输入
val sum = Output(UInt(1.W)) // 和输出
val cout = Output(UInt(1.W)) // 进位输出
})
// 实例化两个半加器
val ha0 = Module(new HalfAdder())
val ha1 = Module(new HalfAdder())
// 将输入连接到第一个半加器
ha0.io.a := io.a
ha0.io.b := io.b
// 将第一个半加器的输出连接到第二个半加器
ha1.io.a := ha0.io.sum
ha1.io.b := io.cin
// 输出连接
io.sum := ha1.io.sum
io.cout := ha0.io.carry | ha1.io.carry // 使用OR门计算最终进位
}
// 用于测试的对象
object FullAdder extends App {
chisel3.Driver.execute(args, () => new FullAdder)
}
.fir:
FIRRTL version 2.0.0
circuit FullAdder :
// 实例化后得到的第一个半加器模块
module HalfAdder :
input clock : Clock
input reset : Reset
output io : { flip a : UInt<1>, flip b : UInt<1>, sum : UInt<1>, carry : UInt<1>}
// 半加器和与进位逻辑
node _T = xor(io.a, io.b) @[FullAdder.scala 12:18]
io.sum <= _T @[FullAdder.scala 12:10]
node _T_1 = and(io.a, io.b) @[FullAdder.scala 13:20]
io.carry <= _T_1 @[FullAdder.scala 13:12]
// 实例化后得到的第二个半加器模块
module HalfAdder_1 :
input clock : Clock
input reset : Reset
output io : { flip a : UInt<1>, flip b : UInt<1>, sum : UInt<1>, carry : UInt<1>}
// 半加器和与进位逻辑
node _T = xor(io.a, io.b) @[FullAdder.scala 12:18]
io.sum <= _T @[FullAdder.scala 12:10]
node _T_1 = and(io.a, io.b) @[FullAdder.scala 13:20]
io.carry <= _T_1 @[FullAdder.scala 13:12]
module FullAdder :
input clock : Clock
input reset : UInt<1>
output io : { flip a : UInt<1>, flip b : UInt<1>, flip cin : UInt<1>, sum : UInt<1>, cout : UInt<1>}
inst ha0 of HalfAdder @[FullAdder.scala 26:19] // 实例化第一个半加器
ha0.clock <= clock // 将FullAdder中的时钟信号传输给halfAdder
ha0.reset <= reset // 将FullAdder中的复位信号传输给halfAdder
inst ha1 of HalfAdder_1 @[FullAdder.scala 27:19] // 实例化第二个半加器
ha1.clock <= clock
ha1.reset <= reset
// 匹配实例化中的输入输出端口
ha0.io.a <= io.a @[FullAdder.scala 30:12]
ha0.io.b <= io.b @[FullAdder.scala 31:12]
ha1.io.a <= ha0.io.sum @[FullAdder.scala 34:12]
ha1.io.b <= io.cin @[FullAdder.scala 35:12]
io.sum <= ha1.io.sum @[FullAdder.scala 38:10]
// 计算最终进位值并输出
node _T = or(ha0.io.carry, ha1.io.carry) @[FullAdder.scala 39:27]
io.cout <= _T @[FullAdder.scala 39:11]
FIRRTL IR:
module {
firrtl.circuit "FullAdder" {
firrtl.module private @HalfAdder(in %io_a: !firrtl.uint<1>, in %io_b: !firrtl.uint<1>, out %io_sum: !firrtl.uint<1>, out %io_carry: !firrtl.uint<1>) {
// 声明信号
%io_sum_0 = firrtl.wire {name = "io_sum"} : !firrtl.uint<1>
%io_carry_1 = firrtl.wire {name = "io_carry"} : !firrtl.uint<1>
// firrtl.matchingconnect表示将两个信号相连
firrtl.matchingconnect %io_sum, %io_sum_0 : !firrtl.uint<1>
firrtl.matchingconnect %io_carry, %io_carry_1 : !firrtl.uint<1>
%0 = firrtl.xor %io_a, %io_b : (!firrtl.uint<1>, !firrtl.uint<1>) -> !firrtl.uint<1>
firrtl.matchingconnect %io_sum_0, %0 : !firrtl.uint<1>
%1 = firrtl.and %io_a, %io_b : (!firrtl.uint<1>, !firrtl.uint<1>) -> !firrtl.uint<1>
firrtl.matchingconnect %io_carry_1, %1 : !firrtl.uint<1>
}
firrtl.module @FullAdder(in %clock: !firrtl.clock, in %reset: !firrtl.uint<1>, in %io_a: !firrtl.uint<1>, in %io_b: !firrtl.uint<1>, in %io_cin: !firrtl.uint<1>, out %io_sum: !firrtl.uint<1>, out %io_cout: !firrtl.uint<1>) attributes {convention = #firrtl<convention scalarized>} {
%io_sum_0 = firrtl.wire {name = "io_sum"} : !firrtl.uint<1>
%io_cout_1 = firrtl.wire {name = "io_cout"} : !firrtl.uint<1>
firrtl.matchingconnect %io_sum, %io_sum_0 : !firrtl.uint<1>
firrtl.matchingconnect %io_cout, %io_cout_1 : !firrtl.uint<1>
// 实例化半加器
%ha0_io_a, %ha0_io_b, %ha0_io_sum, %ha0_io_carry = firrtl.instance ha0 @HalfAdder(in io_a: !firrtl.uint<1>, in io_b: !firrtl.uint<1>, out io_sum: !firrtl.uint<1>, out io_carry: !firrtl.uint<1>)
// 为端口声明临时变量
%ha0.io_sum = firrtl.wire : !firrtl.uint<1>
%ha0.io_carry = firrtl.wire : !firrtl.uint<1>
// 实例化中端口连接逻辑
firrtl.matchingconnect %ha0_io_a, %io_a : !firrtl.uint<1>
firrtl.matchingconnect %ha0_io_b, %io_b : !firrtl.uint<1>
firrtl.matchingconnect %ha0.io_sum, %ha0_io_sum : !firrtl.uint<1>
firrtl.matchingconnect %ha0.io_carry, %ha0_io_carry : !firrtl.uint<1>
// 实例化半加器
%ha1_io_a, %ha1_io_b, %ha1_io_sum, %ha1_io_carry = firrtl.instance ha1 @HalfAdder(in io_a: !firrtl.uint<1>, in io_b: !firrtl.uint<1>, out io_sum: !firrtl.uint<1>, out io_carry: !firrtl.uint<1>)
// 为端口声明临时变量
%ha1.io_a = firrtl.wire : !firrtl.uint<1>
%ha1.io_sum = firrtl.wire : !firrtl.uint<1>
%ha1.io_carry = firrtl.wire : !firrtl.uint<1>
// 实例化中端口连接逻辑
firrtl.matchingconnect %ha1_io_a, %ha1.io_a : !firrtl.uint<1>
firrtl.matchingconnect %ha1_io_b, %io_cin : !firrtl.uint<1>
firrtl.matchingconnect %ha1.io_sum, %ha1_io_sum : !firrtl.uint<1>
firrtl.matchingconnect %ha1.io_carry, %ha1_io_carry : !firrtl.uint<1>
firrtl.matchingconnect %ha1.io_a, %ha0.io_sum : !firrtl.uint<1>
firrtl.matchingconnect %io_sum_0, %ha1.io_sum : !firrtl.uint<1>
// 计算最终进位值
%0 = firrtl.or %ha0.io_carry, %ha1.io_carry : (!firrtl.uint<1>, !firrtl.uint<1>) -> !firrtl.uint<1>
firrtl.matchingconnect %io_cout_1, %0 : !firrtl.uint<1>
}
}
}
Core IR:
module {
hw.module private @HalfAdder(in %io_a : i1, in %io_b : i1, out io_sum : i1, out io_carry : i1) {
%0 = comb.xor bin %io_a, %io_b {sv.namehint = "io_sum"} : i1
%1 = comb.and bin %io_a, %io_b {sv.namehint = "io_carry"} : i1
hw.output %0, %1 : i1, i1
}
hw.module @FullAdder(in %clock : !seq.clock, in %reset : i1, in %io_a : i1, in %io_b : i1, in %io_cin : i1, out io_sum : i1, out io_cout : i1) {
// 与SV中细节举例类似,优化掉了临时变量声明逻辑
%ha0.io_sum, %ha0.io_carry = hw.instance "ha0" @HalfAdder(io_a: %io_a: i1, io_b: %io_b: i1) -> (io_sum: i1, io_carry: i1) {sv.namehint = "ha1.io_a"}
%ha1.io_sum, %ha1.io_carry = hw.instance "ha1" @HalfAdder(io_a: %ha0.io_sum: i1, io_b: %io_cin: i1) -> (io_sum: i1, io_carry: i1) {sv.namehint = "ha1.io_sum"}
%0 = comb.or bin %ha0.io_carry, %ha1.io_carry {sv.namehint = "io_cout"} : i1
hw.output %ha1.io_sum, %0 : i1, i1
}
om.class @FullAdder_Class(%basepath: !om.basepath) {
om.class.fields
}
}
时序逻辑-JohnSon 计数器
scala 源码:
import chisel3._
import chisel3.util._
class JohnsonCounter(n: Int) extends Module {
val io = IO(new Bundle {
val clk = Input(Clock()) // 时钟输入
val reset = Input(Bool()) // 复位信号
val count = Output(UInt(n.W)) // 输出计数值
})
// 创建一个寄存器数组,用于存储计数器状态
val reg = RegInit(0.U(n.W))
// Johnson计数器的逻辑
when(io.reset) {
reg := 0.U // 在复位时清零
}.otherwise {
reg := Cat(~reg(n-1), reg(n-1, 1)) // 将最后一位取反并移位
}
io.count := reg // 输出当前计数值
}
// 用于测试的对象
object JohnsonCounter extends App {
chisel3.Driver.execute(args, () => new JohnsonCounter(4)) // 创建一个4位的Johnson计数器
}
.fir:
FIRRTL version 2.0.0
circuit JohnsonCounter :
module JohnsonCounter :
input clock : Clock
input reset : UInt<1>
output io : { flip clk : Clock, flip reset : UInt<1>, count : UInt<4>}
// 创建一个寄存器数组,用于存储计数器状态
reg reg : UInt<4>, clock with :
reset => (reset, UInt<4>("h0")) @[JohnsonCounter.scala 12:20]
// 当触发复位信号时,将寄存器数组置为0
when io.reset : @[JohnsonCounter.scala 15:18]
reg <= UInt<1>("h0") @[JohnsonCounter.scala 16:9]
else :
// 否则执行取反移位逻辑
node _T = bits(reg, 3, 3) @[JohnsonCounter.scala 18:20]
node _T_1 = not(_T) @[JohnsonCounter.scala 18:16]
node _T_2 = bits(reg, 3, 1) @[JohnsonCounter.scala 18:30]
node _T_3 = cat(_T_1, _T_2) @[Cat.scala 30:58]
reg <= _T_3 @[JohnsonCounter.scala 18:9]
io.count <= reg @[JohnsonCounter.scala 21:12]
FIRRTL IR:
module {
firrtl.circuit "JohnsonCounter" {
firrtl.module @JohnsonCounter(in %clock: !firrtl.clock, in %reset: !firrtl.uint<1>, in %io_clk: !firrtl.clock, in %io_reset: !firrtl.uint<1>, out %io_count: !firrtl.uint<4>) attributes {convention = #firrtl<convention scalarized>} {
%c0_ui4 = firrtl.constant 0 : !firrtl.uint<4>
%io_count_0 = firrtl.wire {name = "io_count"} : !firrtl.uint<4>
firrtl.matchingconnect %io_count, %io_count_0 : !firrtl.uint<4>
// %clock 是时钟信号
// %reset 是复位信号
// %c0_ui4 是复位值
%reg = firrtl.regreset %clock, %reset, %c0_ui4 {firrtl.random_init_start = 0 : ui64} : !firrtl.clock, !firrtl.uint<1>, !firrtl.uint<4>, !firrtl.uint<4>
// 取%reg的第3位
%0 = firrtl.bits %reg 3 to 3 : (!firrtl.uint<4>) -> !firrtl.uint<1>
%1 = firrtl.not %0 : (!firrtl.uint<1>) -> !firrtl.uint<1>
// 取%reg的第1~3位
%2 = firrtl.bits %reg 3 to 1 : (!firrtl.uint<4>) -> !firrtl.uint<3>
// 连接运算
%3 = firrtl.cat %1, %2 : (!firrtl.uint<1>, !firrtl.uint<3>) -> !firrtl.uint<4>
// 根据信号变化为寄存器赋值
%4 = firrtl.mux(%io_reset, %c0_ui4, %3) : (!firrtl.uint<1>, !firrtl.uint<4>, !firrtl.uint<4>) -> !firrtl.uint<4>
firrtl.matchingconnect %reg, %4 : !firrtl.uint<4>
firrtl.matchingconnect %io_count_0, %reg : !firrtl.uint<4>
}
}
}
Core IR:
module {
hw.module @JohnsonCounter(in %clock : !seq.clock, in %reset : i1, in %io_clk : !seq.clock, in %io_reset : i1, out io_count : i4) {
%true = hw.constant true
%c0_i4 = hw.constant 0 : i4
// %4 代表触发时钟信号,但不触发复位信号时的值
// %clock 代表时钟信号
// sync 代表同步逻辑
// %reset 代表复位信号
// %c0_i4 代表触发复位信号时的复位值
%reg = seq.firreg %4 clock %clock reset sync %reset, %c0_i4 {firrtl.random_init_start = 0 : ui64, sv.namehint = "reg"} : i4
%0 = comb.extract %reg from 3 : (i4) -> i1 // 取 %reg的第3位
%1 = comb.xor bin %0, %true : i1
%2 = comb.extract %reg from 1 : (i4) -> i3 // 取 %reg的1~3位
%3 = comb.concat %1, %2 : i1, i3
%4 = comb.mux bin %io_reset, %c0_i4, %3 : i4
hw.output %reg : i4
}
om.class @JohnsonCounter_Class(%basepath: !om.basepath) {
om.class.fields
}
}
上述方言均可在下图(方言转换图)中找到其在 CIRCT 项目中对应的位置,但与验证、仿真、调试相关的方言并没有展现在下图中,如:
- Debug:提供独特的 Operations 来表示调试信息,主要用于追踪硬件电路中的信号变化;
- Verif:用于表示硬件语言中如断言等验证相关的特性;
- Sim:用于表示和仿真器进行互动的特性,如 SystemVerilog 中的
$value$plusargs; - LTL:用于表示 SystemVerilog 中的线性时序逻辑,如 sequence、property 等。
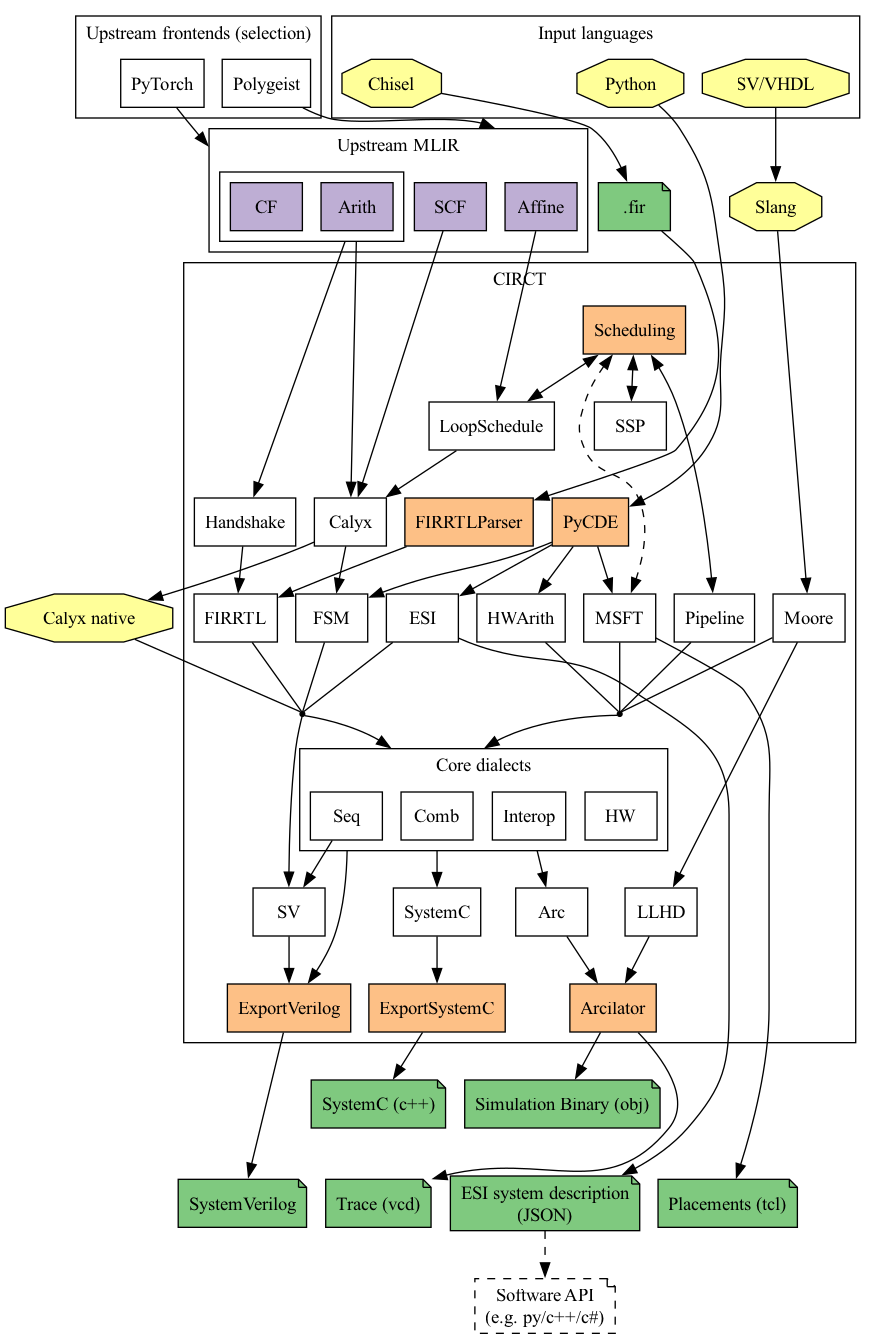
总的来说,方言是由 Operations、Types、Attributes 组成的集合。不同的方言代表着各自独特的功能,同时为开发者提供了在方言层进行特定优化的灵活性。通过这种方式,方言能够有效地支持多样化的应用需求和优化策略。
定义方言
在前文中,我们简要介绍了一些方言及其用途,并提到方言这一概念源于 MLIR。接下来,我们将深入探讨如何在 CIRCT 中使用 TableGen 定义一个新的方言。这种方法的主要优势在于,开发者可以专注于方言的逻辑和功能,而无需过多关注底层实现细节。这不仅能够显著减少代码量,还能提高开发效率,确保生成的代码结构清晰且易于维护,从而加速新方言的开发和集成过程。
TableGen:一种通用语言,带有维护特定领域信息记录的工具;它通过自动生成所有必要的 c++样板代码来简化定义过程,在更改方言定义的各个方面时显著减少了维护负担,并且还提供了额外的工具,如文档生成。
假设我们要定义一个名为 Foo 方言,其中还定义了 IntType、FVIntegerAttr、ConstantOp,以下是需要新增的文件夹以及实现细节举例:
circt/include/circt/Dialect/Foo:定义自己的方言名、Types、Attributes 以及 Operations;
# FooDialect.td //此文件用于定义Foo方言的名字、描述等基本信息
include "mlir/IR/DialectBase.td" // 定义方言是必须引入的头文件,其中定义了基类class Dialect
def FooDialect : Dialect {
let name = "foo";
let cppNamespace = "::circt::foo";
let summary = "一句话说明Foo方言的用途";
let description = [{概述Foo方言的设计理念或者展开说明Foo方言的用途}];
let extraClassDeclaration = [{
void registerTypes();
void registerAttributes();
}];
... // 其余未提到的字段请查看引入的头文件
}
# FooTypes.td // 自定义所需Types
include "circt/include/circt/Dialect/Foo/FooDialect.td"
include "mlir/IR/AttrTypeBase.td" // 此文件定义了有关Types的基类class TypeRef
class FooTypeDef<string name> : TypeDef<FooDialect, name> {}
def IntType : FooTypeDef<"Int"> {
let mnemonic = "int"; // 将以 !foo.int 的形式打印在终端
let summary = "同上";
let description = [{同上}];
let parameters = (ins); // 如果是定义数组等复杂类型,需要用到此字段
let assemblyFormat = [{}]; // 类型的输出格式将按照assemblyFormat中的形式打印在终端
}
# FooAttributes.td // 自定义所需Attributes
include "circt/include/circt/Dialect/Foo/FooDialect.td"
include "mlir/IR/AttrTypeBase.td" // 此文件定义了有关Attributes的基类class AttrDef
def FVIntegerAttr : AttrDef<FooDialect, "FVInteger"> { // FV = four-valued : 0, 1, x, z
let mnemonic = "fvint"; // 生成的IR并不会显示的打印此信息
let summary = "同上";
let description = [{同上}];
let parameters = (ins "FVInt":$value); // FVInt是CIRCT中通用的类型,用于表示硬件电路中的四值态
let hasCustomAssemblyFormat = 1; // 开启此字段代表着需要在circt/lib/Dialect/Foo/FooAttributes.cpp中实现其定义
}
# FooOps.td // 自定义所需Operations
include "circt/lib/circt/Dialect/Foo/FooAttributes.td"
include "circt/lib/circt/Dialect/Foo/FooDialect.td"
include "circt/lib/circt/Dialect/Foo/FooTypes.td"
include "mlir/IR/OpBase.td" // 其中定义了有关Operations的特征,如ConstantLike, Commutative, SameOperandsAndResultType
include "mlir/Interfaces/SideEffectInterfaces.td" // 标识某个Op是否会对内存进行操作,如MemRead, RecursiveMemoryEffects, Pure(无副作用)
def ConstantOp : FooOp<"constant", [Pure, ConstantLike]> {
let summary = "同上";
let arguments = (ins I32Attr:$value); // 表示需要传入一个32位的Attribute,否则会报错
let results = (outs IntType:$result); // 返回值类型为自定义的IntType
let assemblyFormat = [{ $value attr-dict `:` type($result)}]; // 这里不展开讨论细节
let hasFolder = 1; // 需要在circt/lib/Dialect/Foo/FooOps.cpp中实现其定义
}
circt/lib/Dialect/Foo:初始化方言,或者在定义 Operations 时,当使用let hasCustomAssemblyFormat = 1时,需要在这个文件夹中实现相应代码等;
# FooDialect.cpp // 初始化方言
#include "circt/include/circt/Dialect/Foo/FooOps.h"
void FooDialect::initialize() {
// Register types and attributes.
registerTypes();
registerAttributes();
// Register operations.
addOperations<
#define GET_OP_LIST
#include "circt/build/include/circt/Dialect/Foo/Foo.cpp.inc"
>();
}
circt/lib/Dialect/Foo/Transforms:在方言内部进行优化时,将对应的优化 Pass 实现写在此文件夹中;circt/test/Dialect/Foo:测试定义的 Type、Attributes 是否符合预期;circt/lib/Conversion/FooToXX:此文件夹用于实现从 Foo 方言到其他方言的转换。
上述代码是核心实现部分,相关的头文件以及 CMakeLists 并未一一列举,这些头文件主要用于引入必要的依赖项,CMakeLists 主要用于辅助生成 C++代码、文档以及添加依赖等。此外,在实际开发中,可能还需要定义 CAPI 接口等,这要求在 circt/include/circt-c/Dialect 目录中新增 Foo.h 文件。关于这一点,我们在此不作过多详述。
应用场景
在 CIRCT 系列教程的另一篇文章CIRCT - 基于 MLIR 的电路编译器和工具链中,我们简要介绍了 CIRCT 的发展历程和 MLIR 起源。CIRCT 项目仅是 MLIR 框架下众多实际应用场景之一,具体应用包括:
- 高性能计算:如 PolyBlocks,这是一个基于 MLIR 的高性能端到端编译器,适用于深度学习和非深度学习计算,支持 JIT 和 AOT 编译;如 Polygeist,可以自动将以一种编程模型 (CUDA) 编写的程序转换为基于 Polygeist/MLIR 的另一种编程模型(CPU 线程);
- 机器学习 & 深度学习:如 IREE、OpenXLA 和 Torch-MLIR,能够将 PyTorch、JAX 和 TensorFlow 等主流机器学习框架映射到 MLIR,并进一步降低到目标硬件;
- 量子计算:如 Catalyst,该项目是一个用于 PennyLane 的 AOT/JIT 编译器,支持混合量子程序加速,并具备完整的自动微分支持、动态量子编程模型;
- 代码生成:如 MLIR-EmitC,提供将机器学习模型转换为 C++ 代码的方法;
- 硬件验证:如 BTOR2MLIR,该项目支持使用软件验证方法解决以 Bᴛᴏʀ2 格式表示的硬件验证问题,并促进形式化验证领域的研究,结果显示其性能与现有方法具有竞争力;
为工业界带来的变化
MLIR 的方言机制为工业界带来了显著的变化,主要体现在以下几个方面:
- 灵活性与扩展性:允许开发者根据特定需求定义新的 Operations、Types、Attributes。这种灵活性使得 MLIR 能够适应多种不同的计算模型和应用场景,从而满足各种领域的需求。
- 多层级中间表示:可以在不同的抽象层次上进行操作和优化。通过这种结构,开发者可以逐步将高层次的描述降低到特定硬件架构上,提升了代码的可重用性和可维护性。
- 简化的转换与优化:提供了便捷的机制来支持同一方言内部以及不同方言之间的转换。这使得在编译过程中可以轻松实现各种优化策略,而无需重写大量代码。
- 统一的命名空间:方言在同一命名空间中定义,确保了不同方言之间的互操作性。这种设计避免了命名冲突,并简化了跨方言操作的实现。
- 丰富的工具支持:MLIR 生态系统提供了多种内置工具和库,支持方言的创建、分析和优化。这些工具极大地提高了开发效率,使得开发者能够专注于功能实现而非底层细节。
- 兼容 LLVM:MLIR 包括 LLVM IR 方言,允许开发者将自定义方言转换为 LLVM IR,从而利用现有的 LLVM 工具链进行后端代码生成。这种兼容性为开发者提供了更广泛的选择和灵活性。
总结
本文首先阐述了方言的本质,即由 Operations、Types 和 Attributes 构成的集合,不同的方言代表着各自独特的功能。通过具体实例,详细介绍了 CIRCT 中部分方言的用途,以加深读者对 CIRCT 的理解。接着,文章提供了如何定义自定义方言的示例,帮助读者掌握这一过程。最后,我们探讨了 MLIR 框架的应用场景,强调了 MLIR 的方言机制不仅提升了编译器开发的效率,还促进了软硬件协同设计,为工业界提供了更高效、更灵活的编译解决方案。
参考资料:
[1] CIRCT官方文档
[2] Exciting times at the intersection of Compilers and Applied Cryptography: Cairo and MLIR
[3] IREE源码仓库
[4] MLIR官方文档
[5] OpenXLA源码仓库
[6] Torch-MLIR源码仓库