一、引言
Triton 作为高性能 AI 算子开发框架,支持开发者快速实现高效的 GPU 算子。但算子开发过程中,常面临逻辑错误、显存访问异常、性能不达预期等问题。本文将从调试工具、自动优化机制、性能分析工具三个维度,结合实战案例,详细讲解 Triton 算子的调试与性能优化方法,帮助开发者提升开发效率与算子性能。
二、Triton调试
Triton 提供了多种调试工具,涵盖编译时检查、运行时打印、CPU 解析执行等场景,帮助开发者精准定位错误。
Debugging Ops
Triton 内置 4 类调试算子,支持编译时与运行时的数值检查、断言验证,适用于快速排查数据异常、显存越界等问题。调试算子功能及执行方法如下表所示:
| 调试算子 | 功能描述 | 执行条件 |
|---|---|---|
| static_print | 编译时打印值(如常量、配置参数) | 不受TRITON_DEBUG环境变量影响 |
| static_assert | 编译时断言条件(如参数合法性校验) | 不满足条件则编译失败 |
| device_print | 运行时从 GPU 设备打印变量值(如线程 ID、数据) | 不受TRITON_DEBUG环境变量影响 |
| device_assert | 运行时断言条件(如数据范围校验) | 仅当TRITON_DEBUG=1时执行 |
- 案例:add_kernel 调试
在向量加法算子中,通过static_print打印编译时的BLOCK_SIZE,通过device_print打印运行时的线程 ID(pid):
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, # *Pointer* to first input vector.
y_ptr, # *Pointer* to second input vector.
output_ptr, # *Pointer* to output vector.
n_elements, # Size of the vector.
BLOCK_SIZE: tl.constexpr, # Number of elements each program should process.
# NOTE: `constexpr` so it can be used as a shape value.
):
pid = tl.program_id(axis=0)
tl.static_print(f"BLOCK_SIZE:{BLOCK_SIZE}")
if pid == 1:
tl.device_print("pid",pid)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
-
常见应用场景
-
结果偏差排查:输出与预期不符时,打印中间计算结果(如
x、y、output),定位数据异常步骤; -
显存越界排查:打印
offsets、block_start等索引值,确认是否超出n_elements范围; -
参数合法性校验:通过
static_assert验证BLOCK_SIZE是否为 2 的幂(如tl.static_assert(BLOCK_SIZE % 32 == 0, "BLOCK_SIZE must be multiple of 32"))。
-
interpreter模式(cpu python解析执行)
Triton 的interpreter模式可将算子代码转换为 Python 代码在 CPU 上执行,无需编译为 GPU 指令,支持 Python 调试生态(如 pdb),是排查逻辑错误、语法错误的高效工具。
启用方式(二选一)
import triton
# 方法1:环境变量
import os
os.environ['TRITON_INTERPRET'] = '1'
# 方法2:在代码中设置
triton.runtime.driver.active.set_interpret_mode(True)
- 案例:结合 pdb 调试 add_kernel
在算子代码中插入 pdb 断点,启用 interpreter 模式后,可逐步执行代码并观察变量变化,具体实现如下:
@triton.jit
def add_kernel(
x_ptr, y_ptr, output_ptr, n_elements,
BLOCK_SIZE: tl.constexpr
):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets
x = tl.load(x_ptr + offsets, mask=mask)
# 插入pdb断点(仅在interpret模式下生效)
import pdb; pdb.set_trace()
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
# 运行命令(启用interpret模式)
# TRITON_INTERPRET=1 python add_kernel.py

如图中所示,运行后将自动进入 pdb 交互环境,可通过以下指令进行断点调试:
-
输入
n(next):单步执行代码,逐步推进执行流程; -
输入
print(offsets)、print(mask)等:查看指定变量的值,验证逻辑正确性; -
输入
c(continue):继续执行到下一个断点(若存在)。
-
技巧
-
优先验证逻辑:开发初期先启用 interpret 模式,在 CPU 上验证核心逻辑,避免 GPU 执行时的错误定位困难;
-
简化 并行 场景:设置
num_warps=1(单线程块),逐步验证并行逻辑,再扩展到多线程; -
结合 Python 工具:使用
assert校验中间结果(如assert (x >= 0).all(), "x contains negative values"),快速触发错误提示。
-
-
限制与适用场景
![]() 优点:
优点:
-
快速迭代:无需编译,缩短调试周期;
-
逻辑定位:精准排查循环边界、条件判断等逻辑错误;
-
跨平台兼容:无 GPU 环境也可调试;
-
教学友好:逐步观察算子执行流程。
![]() 局限性:
局限性:
-
不支持 bfloat16 类型(需通过
tl.cast转为 float32); -
不支持间接内存访问(如
ptr = tl.load(ptr); x = tl.load(ptr)); -
性能较差:解释执行比 GPU 编译执行慢 10~100 倍。
三方调试工具
除内置工具外,Triton 支持集成第三方工具,排查复杂错误(如数据竞争、内存泄漏):
| 工具名称 | 适用场景 | 使用方式 |
|---|---|---|
| compute-sanitizer | NVIDIA GPU:数据竞争、内存访问异常 | 命令前缀:compute-sanitizer python xxx.py |
| LLVM AddressSanitizer | AMD GPU:内存越界、使用后释放 | 编译时启用 ROCm sanitizer 插件 |
| triton-viz | 内存访问可视化(跨 GPU 架构) | 安装后生成内存访问热力图 |
| TritonSan(TritonSanitizer) | CPU 后端:内存越界、数据竞争、未初始化变量 | 自动插桩 LLVM 检测工具,编译为 CPU 可执行文件 |
- TritonSan 解析
TritonSan 是 Triton 框架专门针对 CPU 后端的错误检测工具,依托 triton-shared(Triton 编译器的共享中间件层)将 Triton 内核编译为 CPU 可执行文件。在编译过程中,TritonSan 会启用 LLVM 检测工具(sanitizers)的插桩机制,并实施必要的代码转换,确保检测工具能获取完整的调试信息;当 Triton 内核执行时,将与指定的 LLVM 检测工具协同运行,实现对内核内部错误的精准检测。
TritonSan 涵盖静态检测与动态检测两种模式:静态检测可在算子编译阶段分析代码,发现潜在的语法错误、逻辑风险;动态检测则在算子执行过程中实时监控内存访问、线程行为,一旦触发错误便立即输出详细提示,大幅提升复杂错误的排查效率。下图则是tritonsan工具的一个实现原理:

- TritonSan 基本启用方法
# 查看使用说明
triton-san <sanitizer type> <original command used to launch the triton program...>
# sanitizer type 可选值:
# "asan": 检测缓冲区溢出
# "tsan": 检测数据竞争
# 示例:使用 asan 检测算子内存越界问题
triton-san asan python ./my_triton_program.py
from triton.backends.triton_shared.driver import CPUDriver
triton.runtime.driver.set_active(CPUDriver())
# 确保输出张量在 CPU 上(适配 CPU 后端检测)
# output = torch.empty((size, )).to("gpu") # 注释掉 GPU 输出
output = torch.empty((size, )).to("cpu") # 改为 CPU 输出
三、Triton调优
Triton 采用 SPMD(单程序多数据)模型实现高性能并行,其核心逻辑为:在多核 GPU 架构下,不同 PE(处理单元)执行相同程序,但各自处理不同数据;每个 PE 由多线程实现并发执行,数据加载速度主要取决于 PE 到 DRAM 的带宽,以及 GPU 自身的内存访问模式。
基于上述架构特性,Triton 算子的性能与多个关键因素密切相关,其中核心影响因素包括 block size、num_warps 等配置参数,以及 GPU 内存访问模式。不同参数配置适配不同的数据量场景,如:
-
大数据量场景:block size 配置趋于带宽大小更优,可有效减少数据寻址过程中的开销,提升数据读取与处理效率;
-
小数据量场景:block size 配置趋于数据大小更优,能够避免因数据填充导致的计算资源浪费,降低效率下降风险。
在实际优化中,上述 block size、num_warps 等关键参数,通常会被设置为编译时的常量,以此实现针对性的性能优化。
自动优化机制
为简化参数配置流程、提升适配性,Triton 内置了两种核心自动优化机制——Autotune(自动参数搜索)与启发式 优化。这两种机制可自动控制 block size、num_warps 等关键参数的设置,根据具体业务场景(包括硬件型号、数据规模、计算任务类型等)动态调整参数元数据(metadata),从而实现对不同硬件环境与数据规模的精准适配,无需人工手动调试即可达到较优性能。
Autotune(自动参数搜索)
Autotune 是 Triton 中核心的自动优化手段,其核心思路是通过遍历预设的参数空间,自动筛选出最优的参数组合(如 block size 与 num_warps 的搭配),具备极强的场景适配性,可广泛适用于不同硬件型号、不同输入数据规模的各类场景。
-
核心依赖
-
@triton.autotune:负责遍历参数空间、测试性能、筛选最优配置; -
@triton.Config:定义候选配置,指定 block size、num_warps 等参数。
-
-
工作原理
-
定义参数空间:通过
configs列表指定候选参数组合; -
自动测试:在目标硬件上执行每个配置,记录执行时间、吞吐量;
-
选择最优:根据性能排序,将最优配置作为默认执行参数。
-
-
案例:Autotune 优化 matmul 算子
import triton
import triton.language as tl
# 定义候选配置(不同 block size 与 num_warps 组合)
configs = [
triton.Config({'BLOCK_M': 128, 'BLOCK_N': 128, 'BLOCK_K': 32}, num_warps=4),
triton.Config({'BLOCK_M': 256, 'BLOCK_N': 256, 'BLOCK_K': 32}, num_warps=8),
triton.Config({'BLOCK_M': 512, 'BLOCK_N': 512, 'BLOCK_K': 64}, num_warps=16),
]
# 以输入矩阵维度(M、N、K)为调优key,适配不同输入规模
@triton.autotune(configs=configs, key=['M', 'N', 'K'])
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K, # 矩阵维度
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
):
# 矩阵乘法核心逻辑(省略,核心为分块矩阵乘法与内存高效访问)
pass
启发式优化
Triton 通过@triton.heuristics装饰器预定义参数规则,结合当前硬件特性与输入数据特征,直接推导并生成最优参数配置,无需遍历全部参数空间,从而实现“快速决策、即时适配”的优化效果。
-
启发式优化的参数决策依赖 Triton 内置的经验规则库,该规则库源于大量硬件测试与场景验证,涵盖以下核心维度的适配规则:
-
硬件维度:针对不同架构 GPU(如 NVIDIA Ampere、Hopper 等)的内存带宽、 warp 数量、计算单元规模,预设对应的 block size 与 num_warps 基准值;
-
数据维度:根据输入数据的维度(1D/2D/3D)、数据类型(FP16/FP32/INT8)、数据量范围,定义参数调整系数;
-
任务维度:针对矩阵乘法、卷积、元素级运算等不同算子类型,优化内存访问模式与线程分工策略,匹配对应的参数配置。
-
-
案例:启发式调整 block size
案例1:向量加法 - 根据数据规模调整
import triton
import triton.language as tl
def heuristic_add_block_size(args):
"""根据输入数据量动态选择最优 block size"""
n_elements = args['n_elements']
# 启发式规则:
# - 数据量 < 1024:使用小 block,减少数据填充开销
# - 数据量 >= 1024:使用大 block,提升内存加载效率
if n_elements < 1024:
return {'BLOCK_SIZE': 128}
elif n_elements < 65536:
return {'BLOCK_SIZE': 256}
elif n_elements < 262144:
return {'BLOCK_SIZE': 512}
else:
return {'BLOCK_SIZE': 1024}
@triton.heuristics(values={'BLOCK_SIZE': heuristic_add_block_size})
@triton.jit
def add_kernel(
x_ptr, y_ptr, output_ptr, n_elements,
BLOCK_SIZE: tl.constexpr
):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
案例2:矩阵乘法 - 多参数启发式优化
import math
def next_power_of_2(n):
"""返回大于等于n的最小2的幂"""
return 1 << (n - 1).bit_length() if n > 1 else 1
def heuristic_matmul_block_size(args):
"""矩阵乘法的多参数启发式优化"""
M, N, K = args['M'], args['N'], args['K']
# 根据矩阵维度选择分块大小
# 规则:选择2的幂次,确保内存对齐和合并访问
return {
'BLOCK_M': min(128, next_power_of_2(M // 16)),
'BLOCK_N': min(256, next_power_of_2(N // 8)),
'BLOCK_K': min(64, next_power_of_2(K // 32))
}
def heuristic_matmul_tiling(args):
"""根据计算强度选择分块策略"""
M, N, K = args['M'], args['N'], args['K']
total_ops = 2 * M * N * K
total_bytes = 4 * (M * K + K * N + M * N) # float32
arithmetic_intensity = total_ops / total_bytes
# 根据算术强度调整策略
if arithmetic_intensity > 20: # 计算密集型
return {'GROUP_SIZE_M': 1} # 减少分组,提高计算局部性
else: # 内存密集型
return {'GROUP_SIZE_M': 8} # 增加分组,改善内存访问
# 组合多个启发式函数
@triton.heuristics(values={
'BLOCK_M': lambda args: heuristic_matmul_block_size(args)['BLOCK_M'],
'BLOCK_N': lambda args: heuristic_matmul_block_size(args)['BLOCK_N'],
'BLOCK_K': lambda args: heuristic_matmul_block_size(args)['BLOCK_K'],
'GROUP_SIZE_M': heuristic_matmul_tiling,
})
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
BLOCK_M: tl.constexpr,
BLOCK_N: tl.constexpr,
BLOCK_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
):
# 矩阵乘法核心逻辑
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_M)
num_pid_n = tl.cdiv(N, BLOCK_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (pid % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
# 矩阵分块计算
# ... 详细实现省略 ...
调优工具Proton
Proton 是 Triton 官方推出的 GPU 性能分析工具,基于 NVIDIA NSight 开发,支持精准监控硬件资源使用情况(如 FLOPs、显存带宽、线程利用率),生成可视化性能报告,帮助开发者快速定位性能瓶颈(如框架开销过大、内存访问效率低)。
-
核心功能
-
精准性能采样:支持对指定代码区域进行性能采样,聚焦核心算子的性能表现;
-
自定义指标监控:可根据需求监控 FLOPs、字节吞吐量、执行时间等核心性能指标;
-
可视化报告生成:支持生成包含 TFLOPS/s、内存带宽等指标的可视化报告,直观呈现性能分布;
-
多实现对比:支持为不同算子实现(如 cuBLAS vs Triton)添加语义标签,方便性能对比分析。
-
-
基本使用流程
安装依赖:
# 编译安装 Triton 并启用 Proton 模块
TRITON_BUILD_PROTON=ON pip install -e .
# 安装可视化依赖 hatchet
pip install llnl-hatchet
对指定区域分析:
import torch
import triton
import triton.language as tl
import triton.profiler as proton
# 定义待分析的 add 算子(省略 kernel 实现,复用前文 add_kernel)
@triton.jit
def add_kernel(...):
...
def add(x, y):
n_elements = x.numel()
output = torch.empty_like(x)
BLOCK_SIZE = 1024
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE)
return output
# 启动性能分析,指定分析名称,保存报告到 vec_add_analysis.hatchet
proton.start("vec_add_analysis", hook="triton")
# 测试代码(待分析区域)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device=DEVICE)
y = torch.rand(size, device=DEVICE)
output_torch = x + y
output_triton = add(x, y)
# 验证结果正确性
print(f"最大值差异: {torch.max(torch.abs(output_torch - output_triton))}")
# 结束分析并生成性能报告
proton.finalize()
可视化报告:
# 命令行查看vec_add_analysis.hatchet包含指标
# python -m triton.profiler.viewer --list vec_add_analysis.hatchet
# 方法一:命令行工具
# proton-viewer -m tflops/s_time/s vec_add_analysis.hatchet # 以TFLOPs和时间为指标
# 方法二: 代码添加
import triton.profiler.viewer as proton_viewer
metric_names = ["tflops/s", "time/ms"]
tree, metrics = proton_viewer.parse(metric_names, "vec_add_analysis.hatchet")
proton_viewer.print_tree(tree, metrics)
报告分析:

上图的结果使用time/ms作为性能指标分析vec_add的性能消耗,显示了一个根节点 ROOT: 0.097 ms 和多个子节点,即总执行时间是0.097 ms(根节点),Triton 内核add_kernel 只占了 0.002 ms(最后一行),大部分时间(0.095 ms)花在了 PyTorch 框架的开销上如内存分配和拷贝、张量初始化、CUDA 上下文管理以及其他辅助操作。
图例显示了时间占比的颜色编码:
![]() 深色 (0.09-0.10 ms): ROOT 节点
深色 (0.09-0.10 ms): ROOT 节点
![]() 中等色 (0.03-0.09 ms): 多个 PyTorch 内核
中等色 (0.03-0.09 ms): 多个 PyTorch 内核
![]() 浅色 (0.00-0.03 ms):
浅色 (0.00-0.03 ms): add_kernel 和其他小开销
- 高级用法: 语义标注用户区域
通过 proton.scope 为不同算子实现添加语义标签,可直观对比性能差异(如 cuBLAS、PyTorch 原生、Triton 实现的矩阵乘法性能):
import cublas
import torch
def cublas_matmul(a, b):
# 校验维度兼容性
assert a.shape[1] == b.shape[1], "Incompatible dimensions (b is transposed)"
M, K = a.shape
N, K = b.shape
dtype = a.dtype
c = torch.empty((M, N), device=a.device, dtype=dtype)
bytes_per_elem = a.element_size()
flops_str = f"flops{bytes_per_elem * 8}" # 定义 FLOPs 指标(区分精度)
# 添加语义标签,记录性能指标
with proton.scope(f"cublas [M={M}, N={N}, K={K}]",
{"bytes": bytes_per_elem * (M * K + N * K + M * N),
flops_str: 2. * M * N * K}):
cublas.matmul(a, b, c)
return c
def torch_matmul(a, b):
M, K = a.shape
N, K = b.shape
bytes_per_elem = a.element_size()
flops_str = f"flops{bytes_per_elem * 8}"
with proton.scope(f"torch [M={M}, N={N}, K={K}]",
{"bytes": bytes_per_elem * (M * K + N * K + M * N),
flops_str: 2. * M * N * K}):
c = torch.matmul(a, b.T)
return c
# 性能基准测试
def bench(K, dtype, reps=10000, warmup_reps=10000):
M = 8192
N = 8192
a = torch.randn((M, K), device="cuda", dtype=torch.float16).to(dtype)
b = torch.randn((K, N), device="cuda", dtype=torch.float16).to(dtype)
b = b.T.contiguous() # 转置并确保内存连续
# 测试不同实现的性能
if cublas is not None:
bench_fn("cublas", reps, warmup_reps, cublas_matmul, a, b)
if dtype == torch.float16:
bench_fn("torch", reps, warmup_reps, torch_matmul, a, b)
# 可添加 Triton 实现的测试代码
# bench_fn("triton", reps, warmup_reps, triton_matmul, a, b)
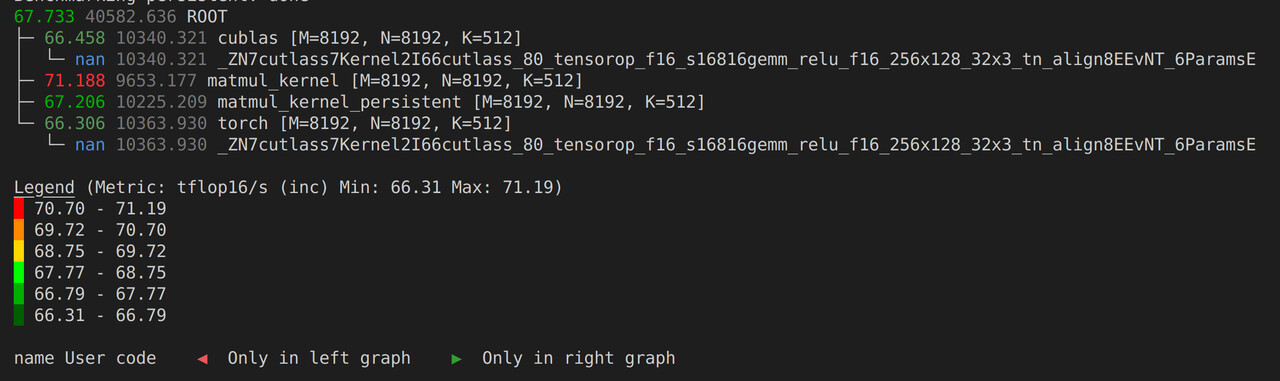
上图显示了不同矩阵乘法实现(包括 Triton)的性能比较,使用 TFLOPS/s(半精度 FLOPs) 作为性能指标。在 8192×8192 矩阵乘法场景下,cuBLAS、PyTorch 原生、Triton 三种实现的性能均在 66-71 TFLOPS/s 范围内,性能接近,说明 Triton 算子可达到工业级高性能水平。
四、总结
本文系统讲解了 Triton 算子开发中的调试与性能优化方法:
-
调试层面:通过
static_print/device_print快速排查编译时 / 运行时错误,利用interpreter模式结合 pdb 定位逻辑漏洞,第三方工具辅助解决复杂内存问题; -
优化层面:Autotune 自动搜索最优参数组合,启发式机制适配硬件与数据规模,无需手动调整;
-
性能分析:Proton 工具精准定位瓶颈,通过可视化报告指导进一步优化。
掌握这些技巧后,开发者可大幅提升 Triton 算子的开发效率,实现兼顾正确性与高性能的算子实现。实际开发中,建议遵循 “先调试后优化” 的流程:先通过 interpreter 模式验证逻辑正确性,再通过 Autotune 与启发式优化提升性能,最后用 Proton 定位剩余瓶颈,实现极致优化。