Triton 简介
Triton是一种由OpenAI开发的基于Python的开源DSL编程语言,旨在简化高性能GPU代码的编写。最早于2019年,由Tillet等人在哈佛大学的论文《Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations》中提出基本设计理念,包括线程块级并行编程、基于LLVM的中间表示及分阶段的优化流程。自2020年起,OpenAI开始全面推进Triton的开发,经过多年的迭代,目前已发布3.0版本。多个开源项目,包括PyTorch、Unsloth、FlagGems等,已采用Triton来开发部分或全部算子。
最初,Triton 仅支持英伟达的消费级 GPU,随后逐步扩展至 A100、H100 等工业级 GPU。其他品牌的 AI 芯片,如国内外的 GPGPU 和 DSA 加速器等硬件平台,也逐渐支持 Triton。在今年硅谷的 Triton 大会(2024 年 9 月 17 日)上,Intel、AMD、微软、AWS、高通、Nvidia 等芯片厂商分享了他们在 Triton 上的进展及性能成果,展示了 Triton 在不同硬件平台上的广泛应用。此外,Triton 也已开始探索对 CPU 的适配,以进一步提升其硬件兼容性。
Triton在硬件层面面向计算线程阵列(Cooperrative Thread Arrays),在软件层面面向线程块级别的并行进行编程。相比PyTorch等高级框架,Triton更专注于计算操作的具体实现,开发者可以灵活操作Tile级数据的读写、执行计算原语并定义线程块划分方式。Triton隐藏了线程块级以下的调度细节,编译器自动管理共享内存、线程并行、访存合并和张量布局等复杂内容,从而降低了并行编程难度,提升了开发效率。开发者只需理解基本的并行原理,即可专注于算法的设计与实现,快速编写出性能优异的算子。
尽管在编程灵活性上有所折中,Triton 通过多层次编译与优化,依然能实现媲美 CUDA 的性能。以矩阵乘法为例,官方教程中的 Triton 实现,在特定测试环境下性能可与 cuBLAS 比肩,充分发挥硬件的计算能力,展示了出色的性能表现。
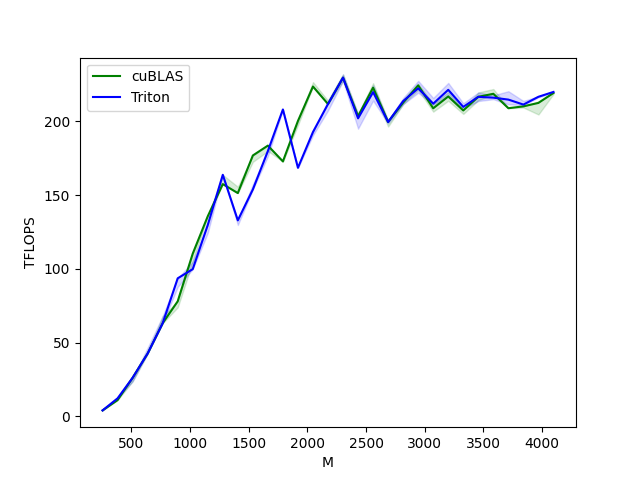
)
Triton on CPU
背景
Triton 的 CPU 后端目前包括微软的 Triton-Shared 和 Triton 官方的 Triton-CPU等项目,此外还有寒武纪的 Triton-Linalg,但是Triton-Linalg目前只完成了前端接入,后端CPU支持尚未完成,仍处于开发阶段。Triton-Shared采用了MLIR上游的linalg方言接入Triton的IR,然后进行lowering,最终转换为标量的LLVM表示,整个转换pipeline中没有加入硬件平台的优化,当前仍属于实验性阶段,性能表现较低,主要用于探索新功能和验证概念。
相比之下,Triton-CPU 项目采用 MLIR 上游的 vector 方言接入 Triton 的上层 IR,能够有效实现代码的向量化,并在最后使用 OpenMP 多线程 C 函数 Wrapper 来让生成的算子支持多线程,从而显著提升了并行计算性能。在官方 Meetup 的演示中,Triton-CPU 已表现出接近甚至超越 Torch 在 CPU 上的性能,展示了其在高效利用多核资源和指令级并行方面的潜力。
RISC-V作为一个开放的指令集架构(ISA),在AI芯片领域展现出巨大的潜力。其灵活性、可扩展性以及对定制化需求的支持,使其成为设计高效AI处理器的理想选择。目前已经提出的V扩展(Vector Extension)指令集为RISC-V提供了强大的向量处理能力,能够高效地执行并行计算任务,这是AI算法(如深度学习中的矩阵运算和向量操作)的关键需求。同时RISC-V允许开发者添加自定义指令,以加速特定的AI计算任务。例如,可以为常见的神经网络操作(如卷积、激活函数等)设计专用指令,提高执行效率。
Triton的python语言特性和更高层次的编程模型抽象可以显著降低芯片厂商在算子库开发与维护方面的成本;其依托的MLIR软件栈所提供的多层次中间表示(IR)机制,进一步增强了Triton算子库对RISC-V架构的适配能力,提升了不同RISC-V AI芯片之间的兼容性。同时,RISC-V AI芯片的高度可定制化特性,使得芯片厂商能够设计针对对应的算子定制出专用的指令,从而充分发挥算子库的潜力。因此,深入研究Triton算子库在现有RISC-V AI芯片平台上的性能表现,并针对主要性能瓶颈进行优化,对于推动Triton、MLIR及RISC-V生态系统的发展具有关键意义。这不仅促进了各类RISC-V AI芯片的协同发展,也推动了整个生态系统的健康繁荣。
目标
在 Triton-CPU 官方 Meetup 演示中,仅展示了 x86 平台上部分算子的性能表现,而 RISC-V 平台上各种类型算子的性能尚未得到充分研究。本研究的目标是比较使用 OpenAI 的 Triton 语言编写的算子与使用 C 语言编写的算子在相同算法实现条件下,仅依靠编译器优化所产生的性能差异。通过深入分析两者在编译器优化后的汇编代码的差异,旨在发现 Triton-CPU 编译器进一步的优化空间,从而为后续的性能提升提供指导。
开发环境
我们在 X86 平台选择采用交叉编译方案编译 RISC-V 的可执行文件。具体来说,我们使用 Triton-CPU 生成的 LLVM IR,通过交叉编译生成适用于 RISC-V 平台的汇编代码。程序运行在进迭时空的 K1 开发板上,该开发板配备了 8 个双发顺序的 RISC-V CPU,并支持 RVV 1.0 向量扩展,拥有 256bit 的向量寄存器宽度,能够充分测试算子在硬件并行计算能力下的表现。
在编译器方面,C版本的算子分别使用RISC-V GCC 15.0.0和兆松科技的ZCC 3.2.4(基于LLVM的优化编译器)编译器进行编译;Triton算子的LLVM IR由Triton-CPU项目自带的编译器生成,随后通过ZCC编译器转换为RISC-V汇编代码。整个编译过程均启用了-O3优化选项,以确保代码性能的最大化。
算子实现
在算子部分,我们选取了在大语言型模型中常用的 RoPE、Matmul、Softmax、Layernorm 以及图像处理中的 Resize、Warp、Correlation 等算子作为基准测试。具体的算子实现代码可在兆松科技 AI-Benchmark 仓库中获取。
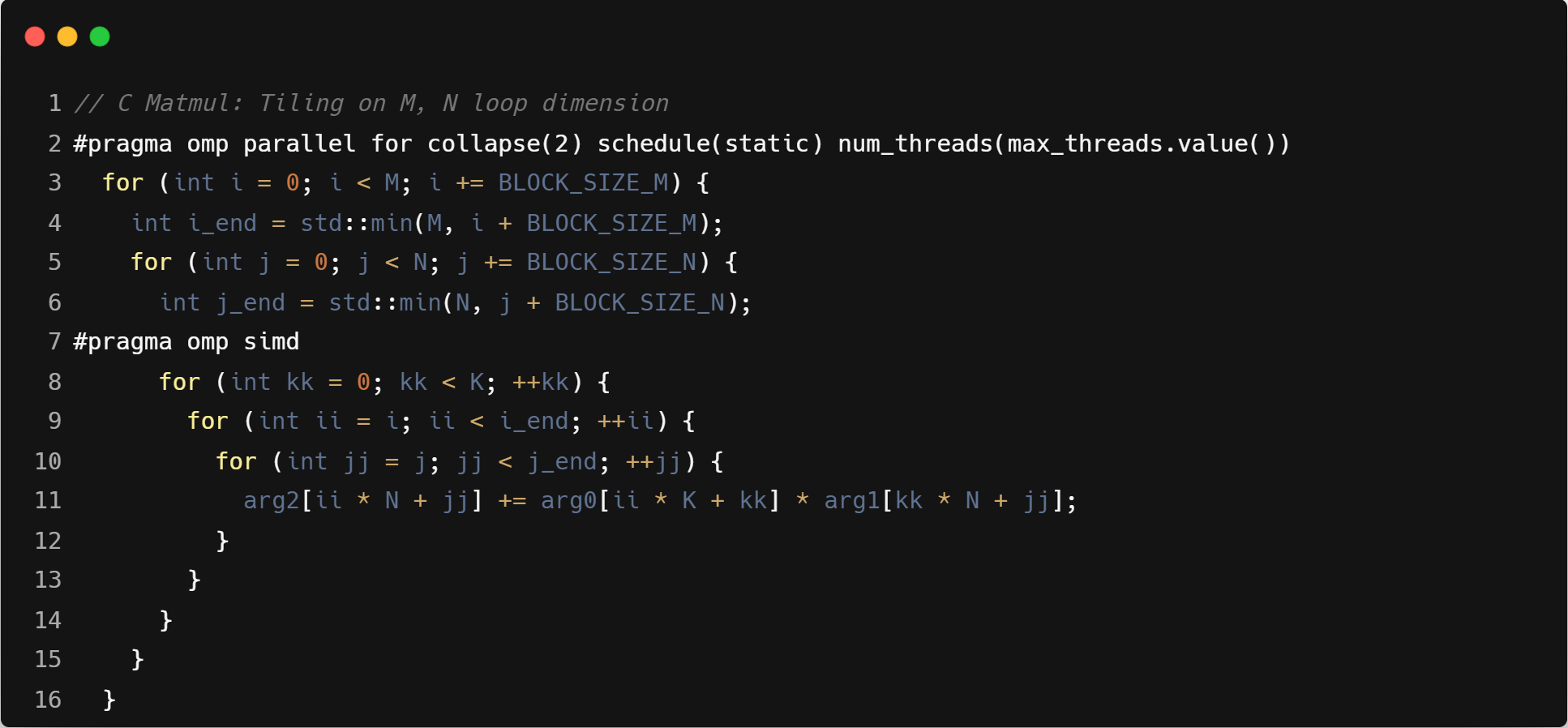
这些算子的实现采用了常见的方案,虽然并非每个算子都是最优的算法实现,但尽量确保了 C 语言与 Triton 语言实现的一致性。C 语言版本的向量化和多线程主要通过#pragma指令实现,未使用任何 RISC-V 的 intrinsic,完全依赖编译器的自动优化能力。
通过这种设计,我们确保了编译器在算子不同编程语言实现之间的公平比较,同时这也为后续的编译器优化提供了明确的基础。
性能数据
在统一的硬件环境和相同的编译器优化级别-O3下,我们对两种实现方案进行了性能测试。对于每个算子,分别在不同的输入形状(shape)下测量 1,4,8 线程(T1, T4, T8)的运行时间。为了便于展示和比较,针对不同的输入输出形状的性能数据相对于算子的时间复杂度进行了归一化处理,最终的性能结果以 GB/s 作为显示单位,数据越大性能越好。
RoPE
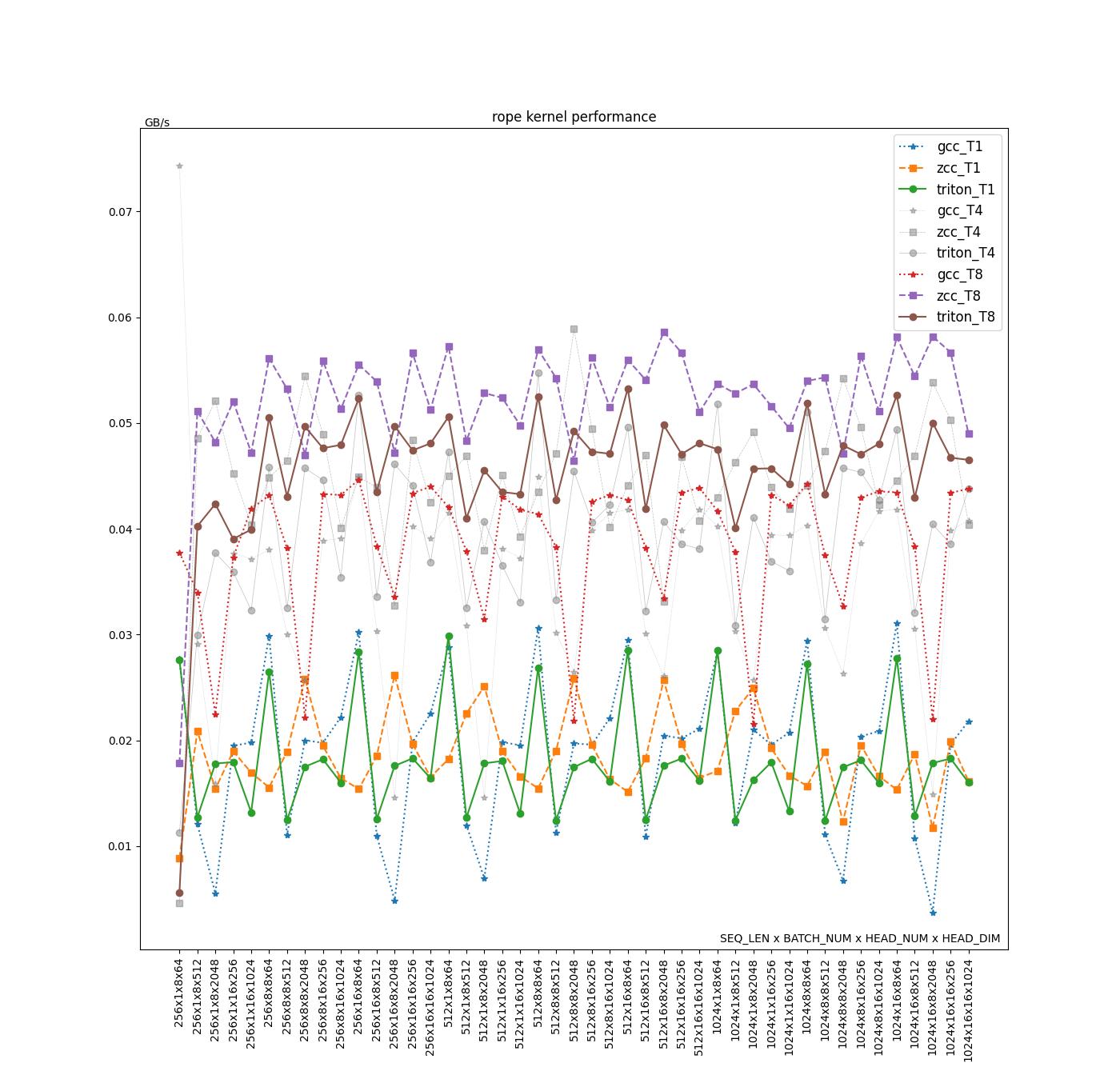
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.01874 | 0.01871 | 0.01825 | 97.55% | 97.40% | ||
| T4 | 0.03489 | 0.04454 | 0.04022 | 90.31% | 115.27% | 103.91% | 100.90% |
| T8 | 0.03874 | 0.05293 | 0.04596 | 86.84% | 118.65% | 100.95% | 100.62% |
| T4/T1 | 200.71% | 263.82% | 229.29% | 86.91% | 114.24% | ||
| T8/T1 | 227.35% | 311.65% | 268.09% | 86.02% | 117.92% |
注(加速比概念在后续表格中同样使用):
- 线程的加速比由原始数据计算比例后求平均值得出(即 T4/T1 和 T8/T1)。
- (Triton/ZCC)/(TN/T1)为去除平均线程加速比后,多线程环境编译器的相对性能相对于单线程编译器的相对性能的差距的变化。
在单线程情况下,Triton、ZCC 和 GCC 的性能表现相近(仅有 2.5%的性能差距)。然而,在四线程和八线程的多线程环境下,ZCC 编译的 C 算子相较于 Triton 算子拥有 10% 至 13% 的性能优势,而 Triton 算子相对于 GCC 编译的 C 算子则提升了约 15% 以上,目前我们认为性能差距主要原因包含以下几点:
- 多线程的影响:根据线程加速比可以看出,不同编译器翻译出来的代码在多线程环境下性能差距较大,具体原因有待分析,其他算子均会受此影响。
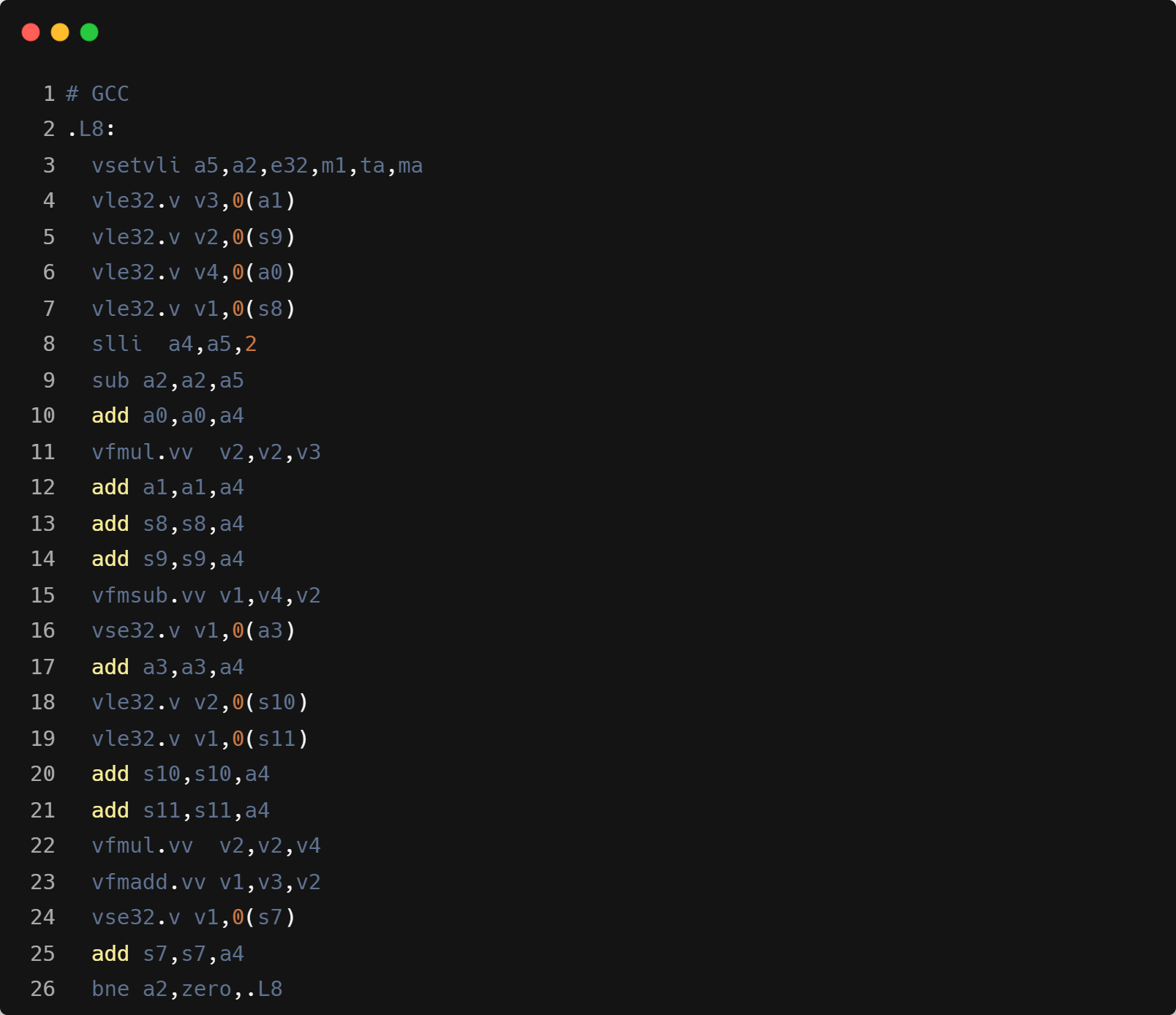
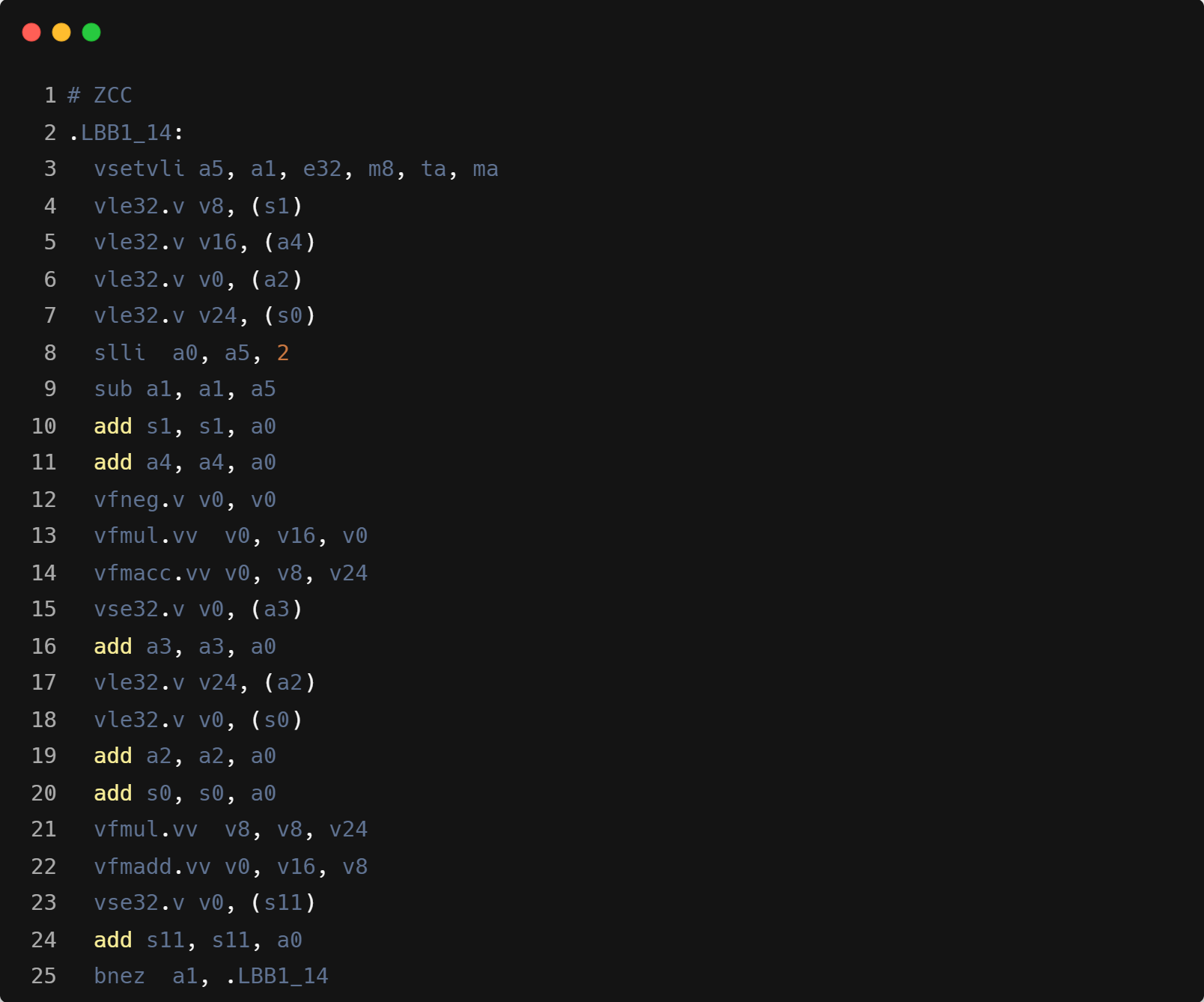
- Triton 循环内指令数会更多,主要是因为需要处理显式的带 mask 的 load 操作计算。可能在单线程性能上会相对 ZCC 和 GCC 有一定差距。 如下是 RoPE 中从输入数组中采用带 mask 的 load 读取数据的示例,以及对应的核心循环汇编中的 mask 计算:
x1 = tl.load(input_ptr + x1_offset, mask=mask, other=0.0)
x2 = tl.load(input_ptr + x2_offset, mask=mask, other=0.0)
Matmul
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.03113 | 0.02568 | 0.03716 | 144.71% | 119.35% | ||
| T4 | 0.12045 | 0.10183 | 0.14484 | 142.24% | 120.25% | 98.94% | 98.82% |
| T8 | 0.22966 | 0.19614 | 0.26273 | 133.95% | 114.40% | 99.12% | 98.88% |
| T4/T1 | 320.55% | 271.35% | 390.08% | 143.76% | 121.69% | ||
| T8/T1 | 611.60% | 523.58% | 707.58% | 135.14% | 115.69% |
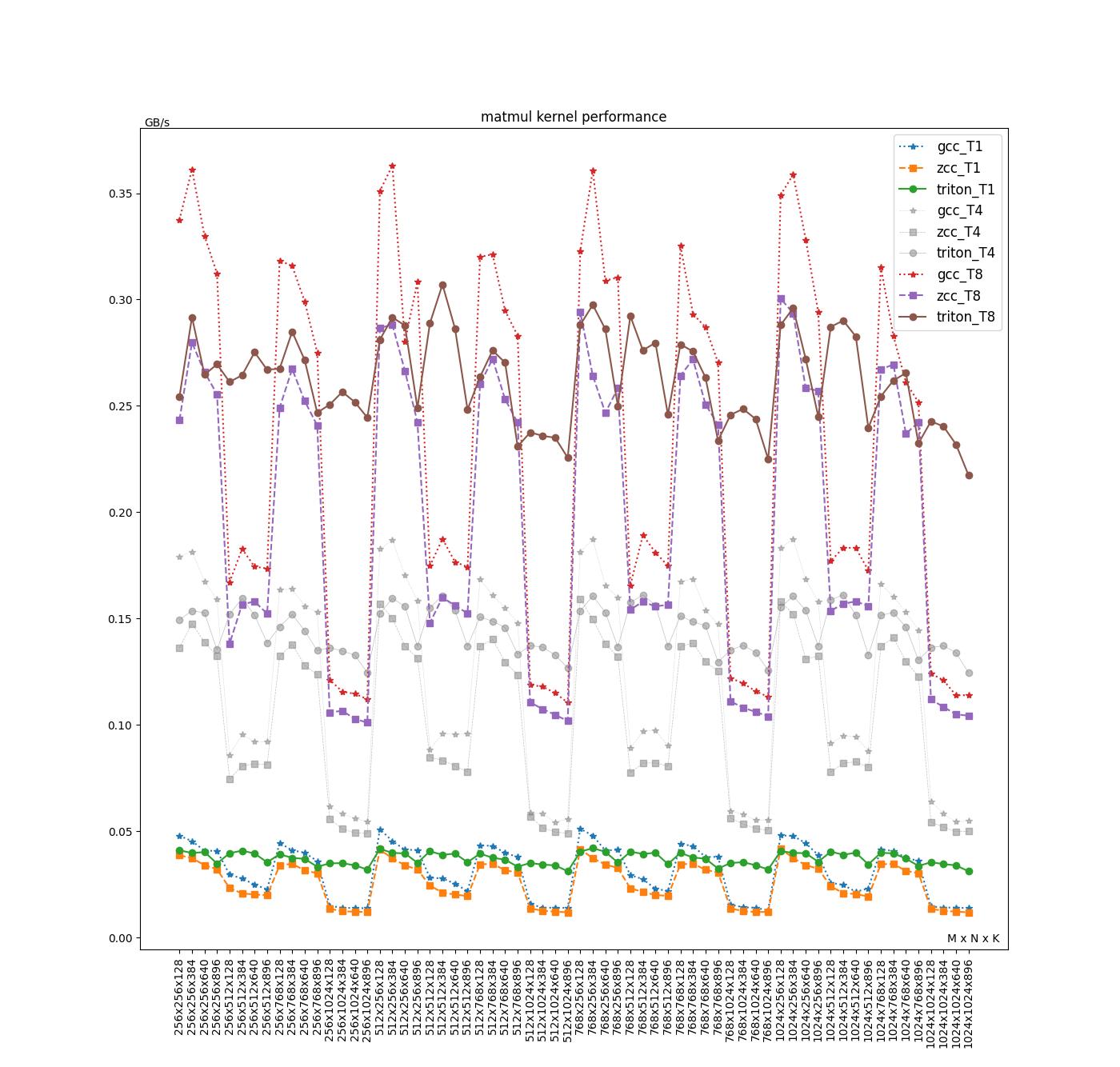
注:Triton 与 C 算子实现均采用分块矩阵乘的实现,但是在针对 M、N 维度上做 tiling 后,GCC/ZCC 无法对外层的 K 维度做自动向量化,导致最后编译出来的汇编有较大差异。
在当前的分块(16x16)下,Triton 性能比 GCC/ZCC 编译得到的 C 算子都更好,且在不同 shape 下的性能表现基本稳定。目前我们认为性能差距主要原因包含以下几点:
-
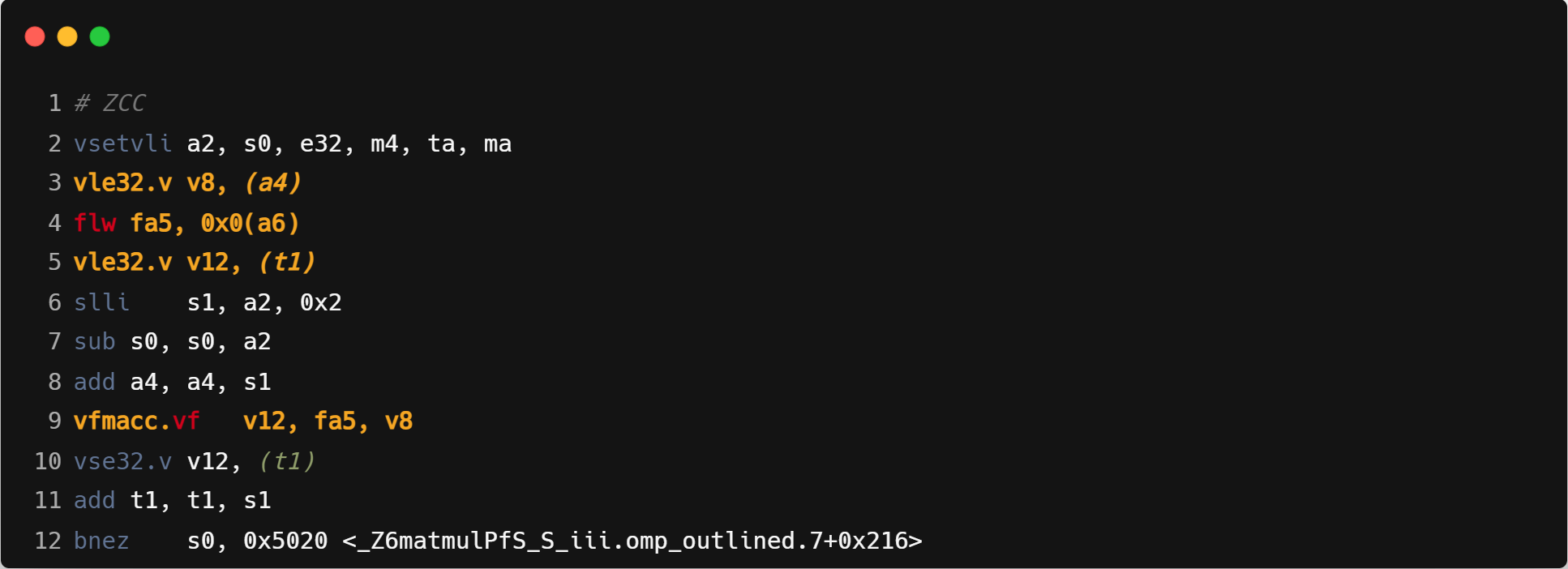
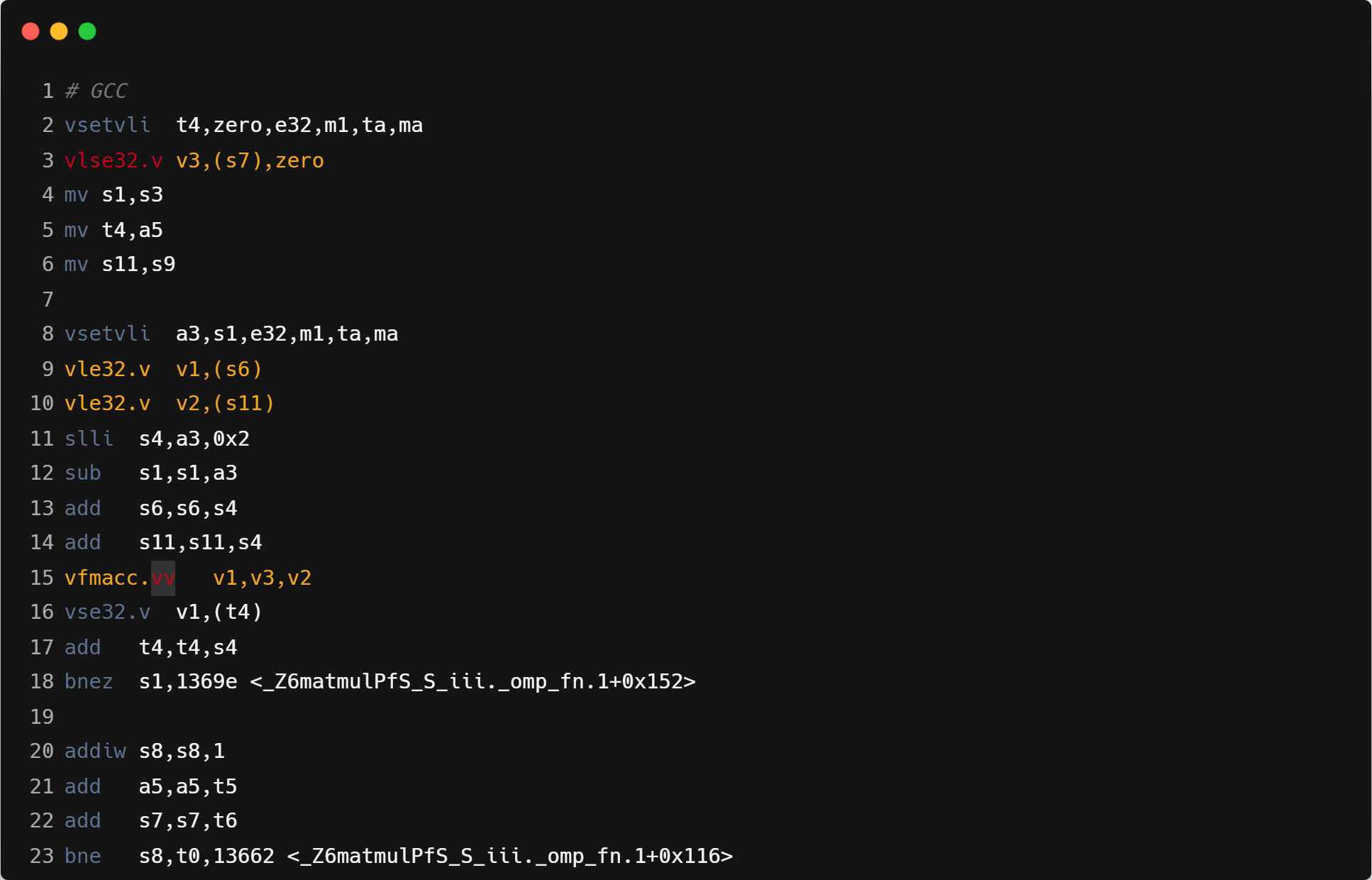
访存方式:GCC 识别出了 strided load 并且利用了 RVV 的 strided load 指令,但是 ZCC 和 Triton 则没有利用 strided load,Triton 使用了标量循环实现 load(见:离散访存的向量化)。
-
寄存器分组:ZCC 分组更大,在 32x32 时才能够完全利用 m4 分组,在当前的 16x16 的分块下,性能没有充分发挥。Triton 会根据切块后的 Block 大小调整分组的大小,GCC 使用 m1 作为分组。
-
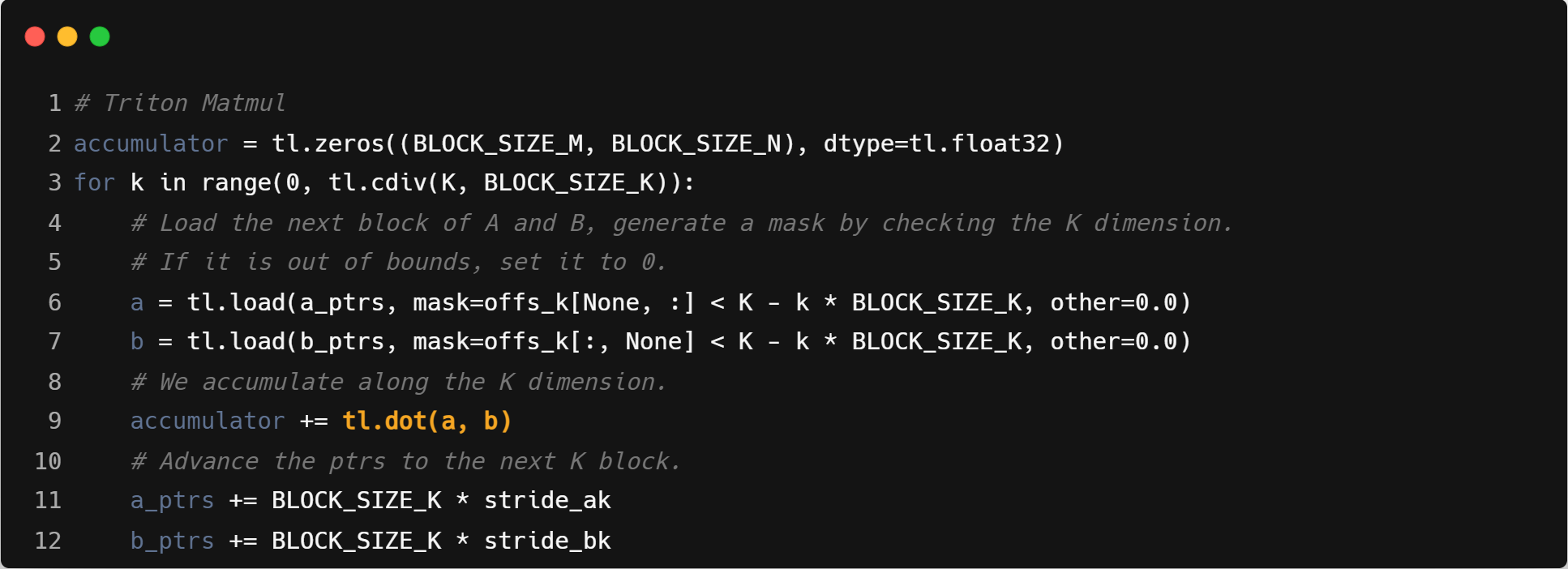
运算方式:GCC 由于利用了 strided load,所以可以使用向量-向量运算,而 ZCC 只能使用标量-向量运算。Triton 会将整个块载入寄存器,将块之间的点积 (dot product highlighted in the code snippet below) 展开,全部利用向量指令进行运算。运算中间可能产生 spill,通过调整块大小可以减少 spill 次数。
如下面的ttir中的块之间的点积就是将tensor<16x8xf32>中的16x8个f32的数据,使用m2的分组,按照长度为16的向量fit进8个向量寄存器中,与tensor<64x16xf32>中的每一行直接做乘法和reduce操作。
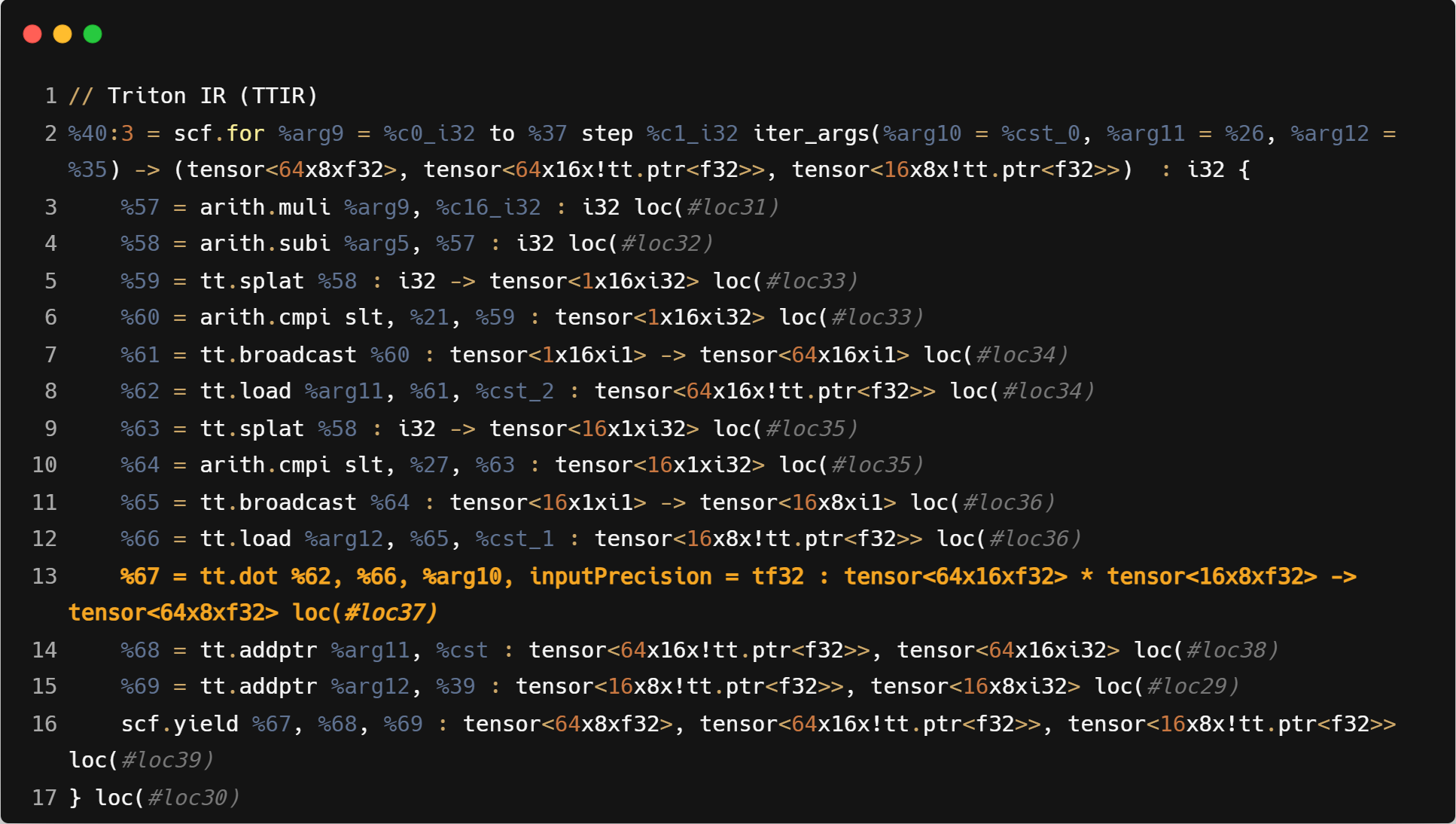
- 核心循环汇编
Softmax
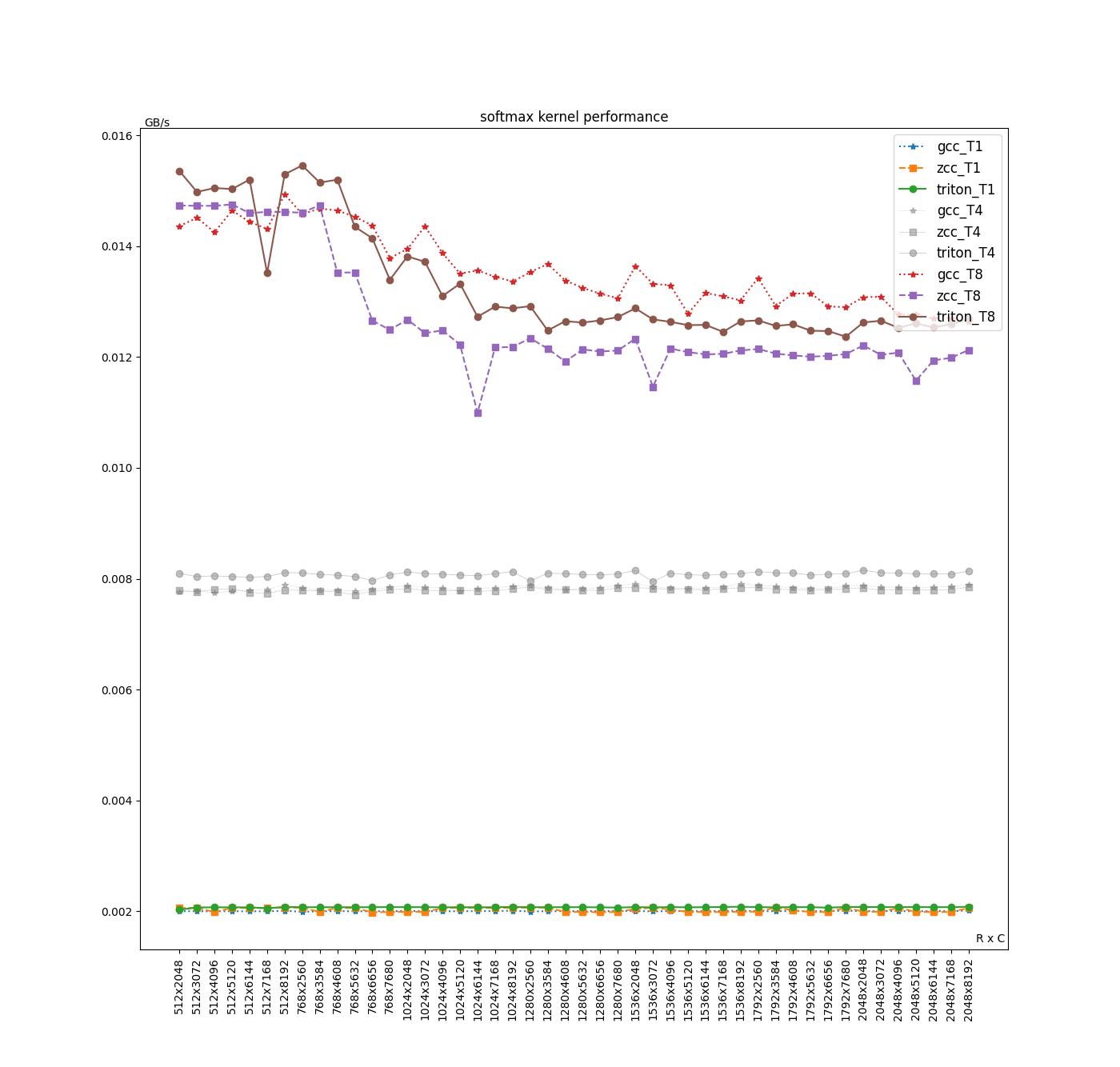
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.00200 | 0.00202 | 0.00207 | 102.53% | 103.50% | ||
| T4 | 0.00783 | 0.00780 | 0.00808 | 103.59% | 103.17% | 100.00% | 100.00% |
| T8 | 0.01356 | 0.01267 | 0.01330 | 104.99% | 98.09% | 100.00% | 100.00% |
| T4/T1 | 378.27% | 376.71% | 390.25% | 103.59% | 103.17% | ||
| T8/T1 | 654.91% | 611.87% | 642.39% | 104.99% | 98.09% |
Triton、ZCC 和 GCC 的性能表现相近。在单,四线程下,Triton 性能整体比 GCC、ZCC 高 2~4%,而在 8 线程时,GCC 性能最好,会比 Triton 高 2%。目前我们认为性能差距主要原因包含以下几点:
-
Safe-Softmax 中的第一步运算:求所有元素的最大值
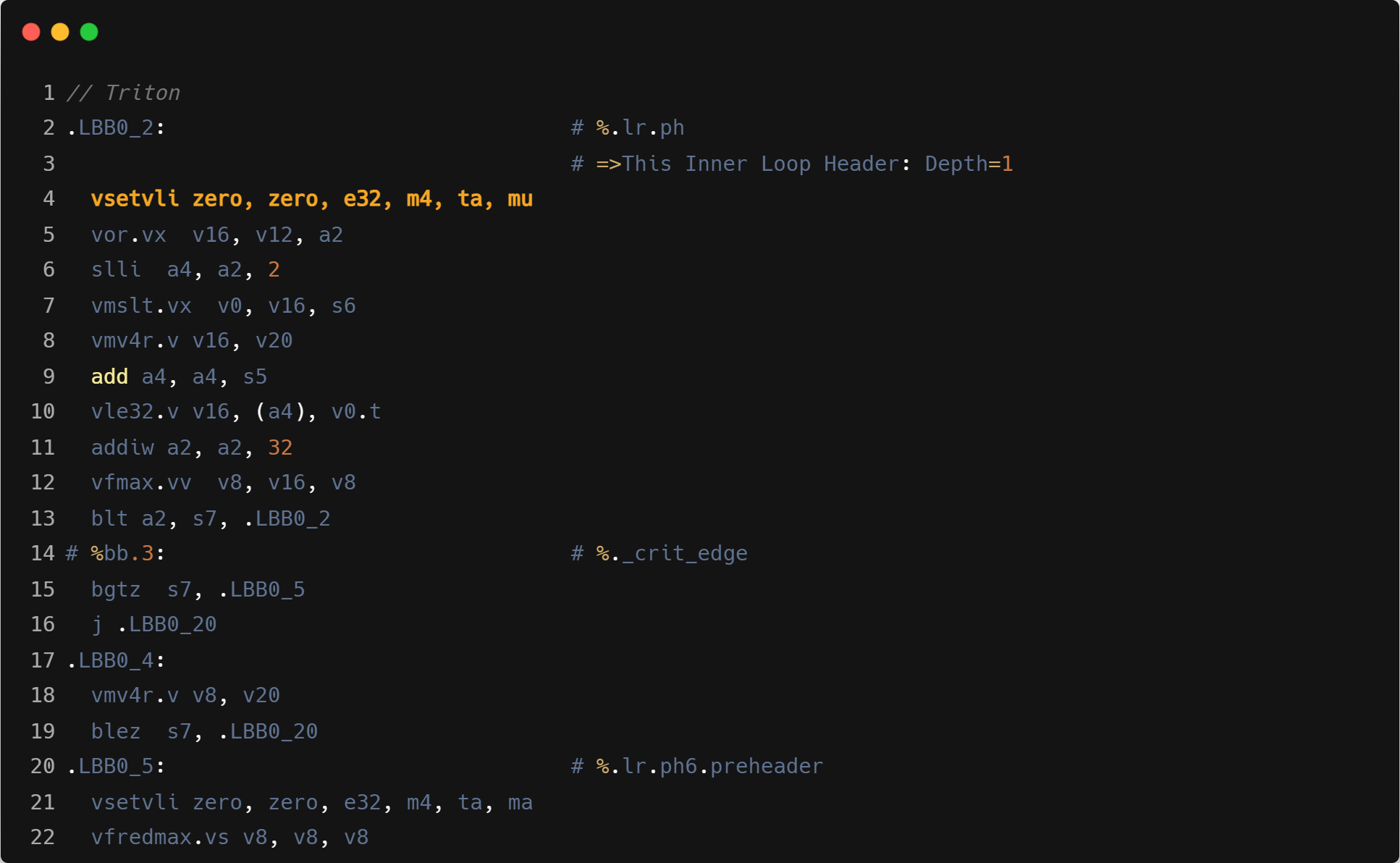
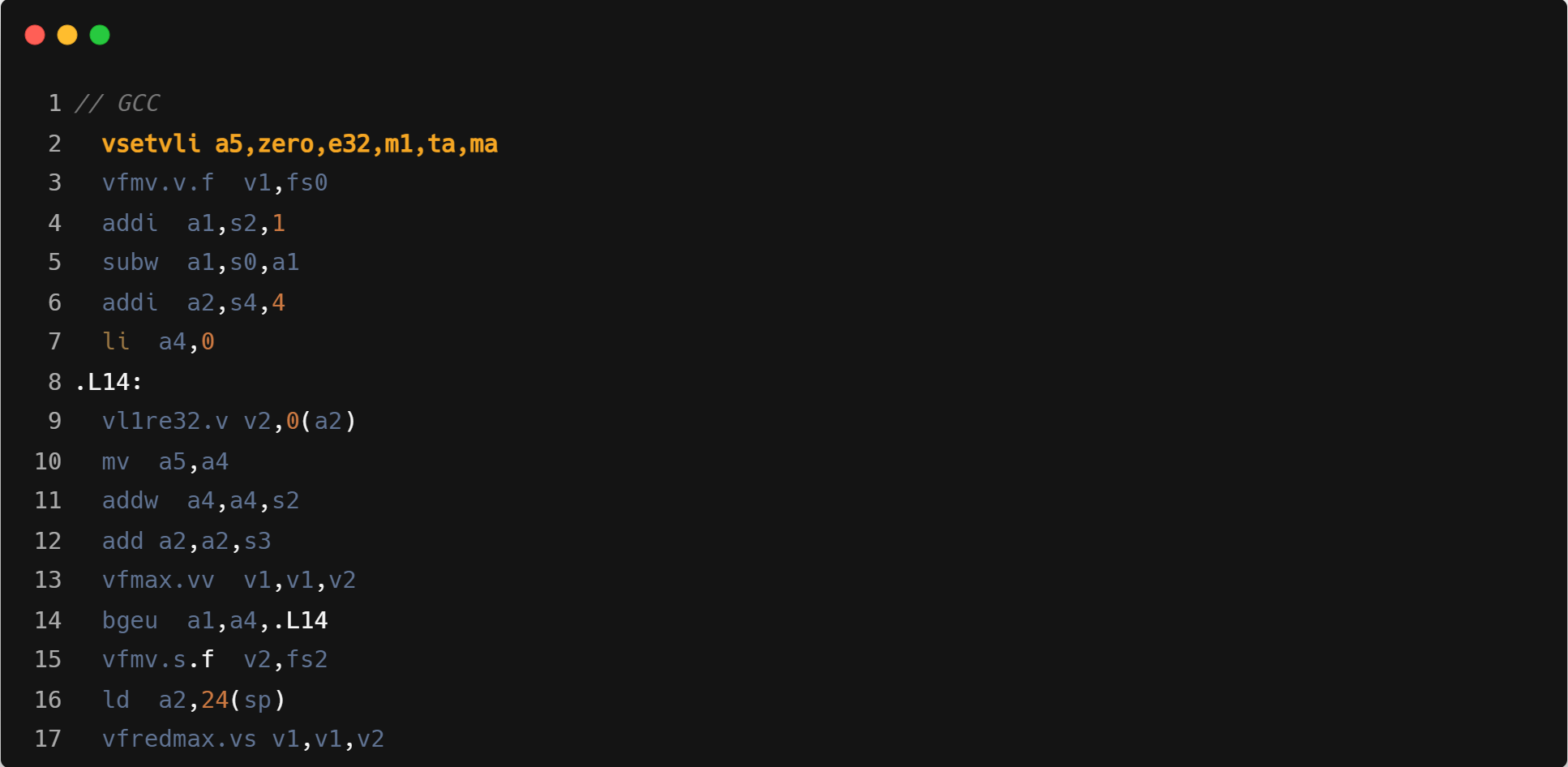
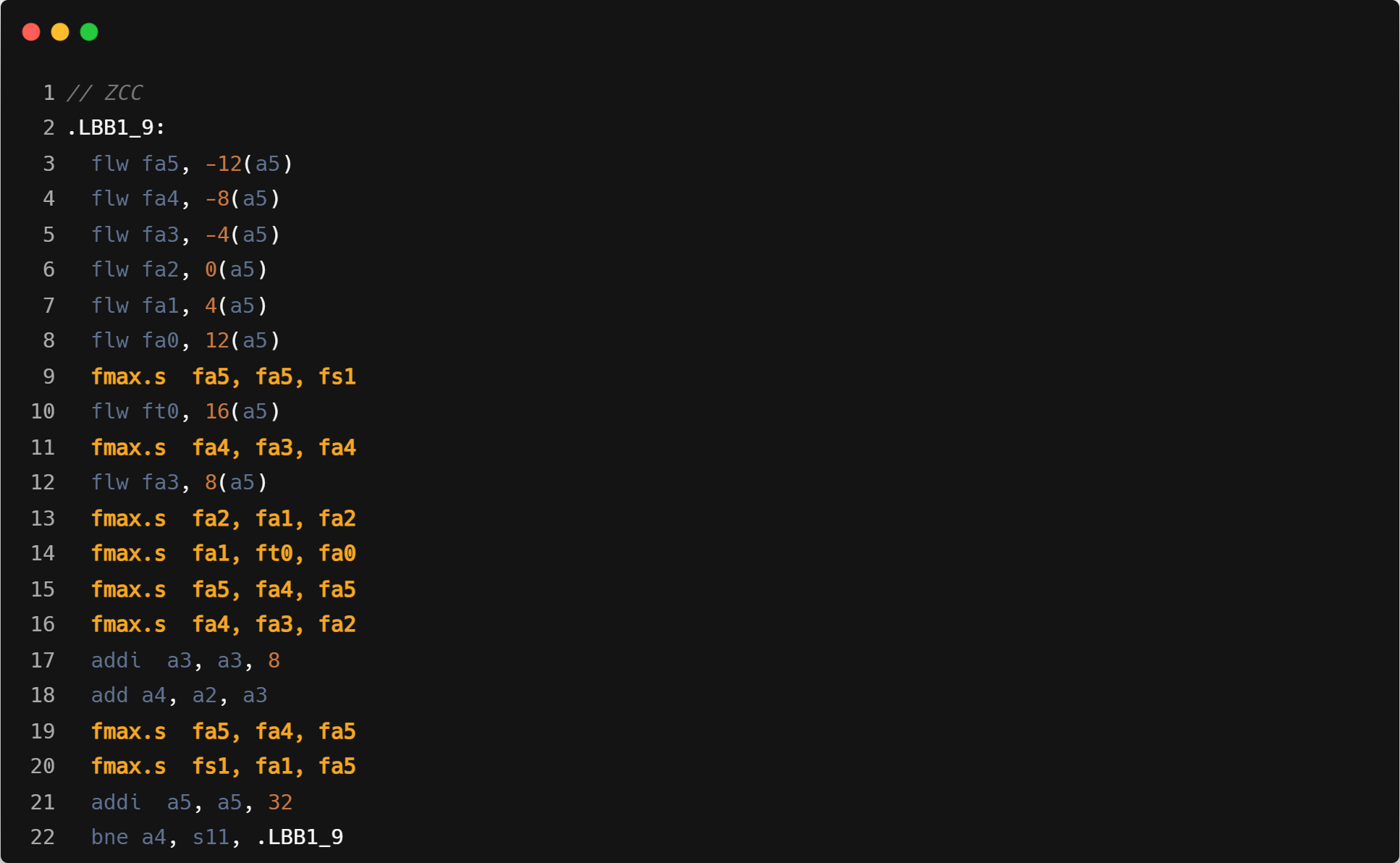
- Triton 与 GCC 都采用 vfredsum,Triton 分组为 m4,GCC 分组为 m1,而 ZCC 使用 unroll 8 次的标量 fmax 替代;
-
Safe-Softmax 中的第二步运算:计算分母(所有元素的指数和)
- Triton、GCC、ZCC 都使用标量运算,Triton unroll 8 次,GCC 与 ZCC 无 unroll。

-
Safe-Softmax 中的第三步运算:计算每一个元素的 Softmax 结果
- Triton、GCC、ZCC 都使用向量除法,Triton 分组为 m4,GCC 分组为 m1,ZCC 分组为 m8。
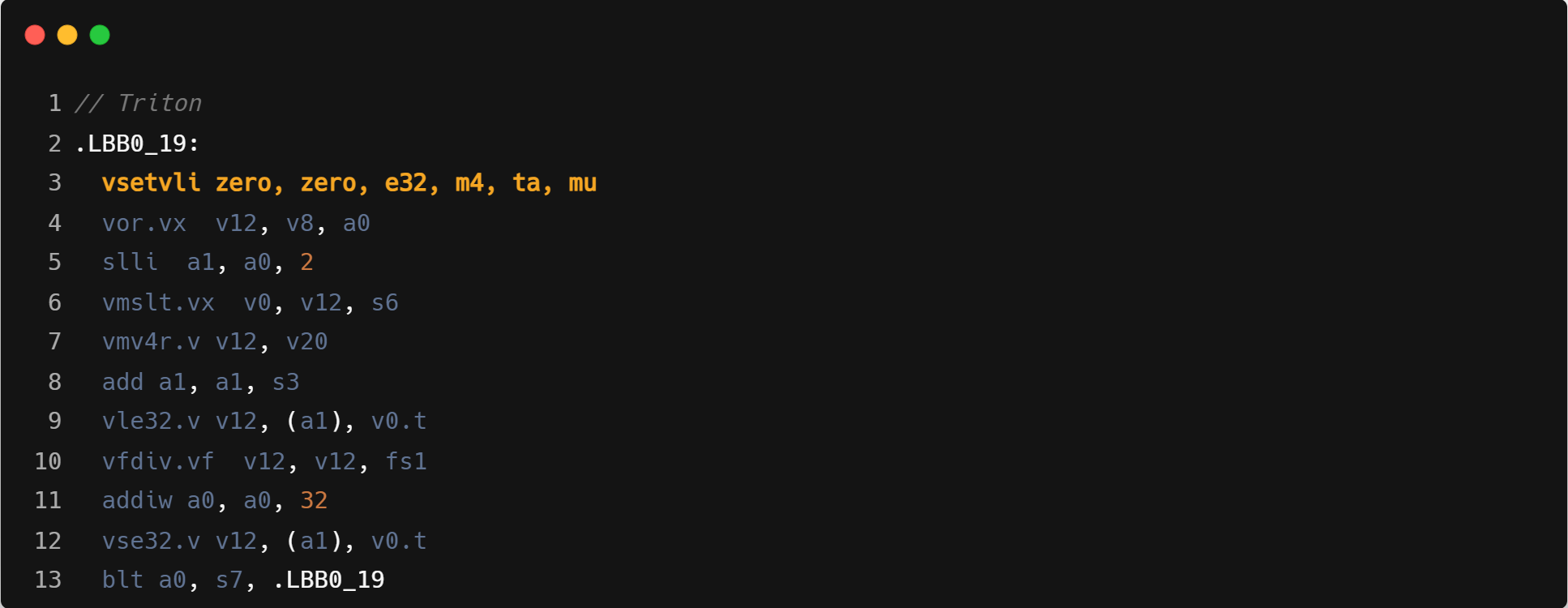


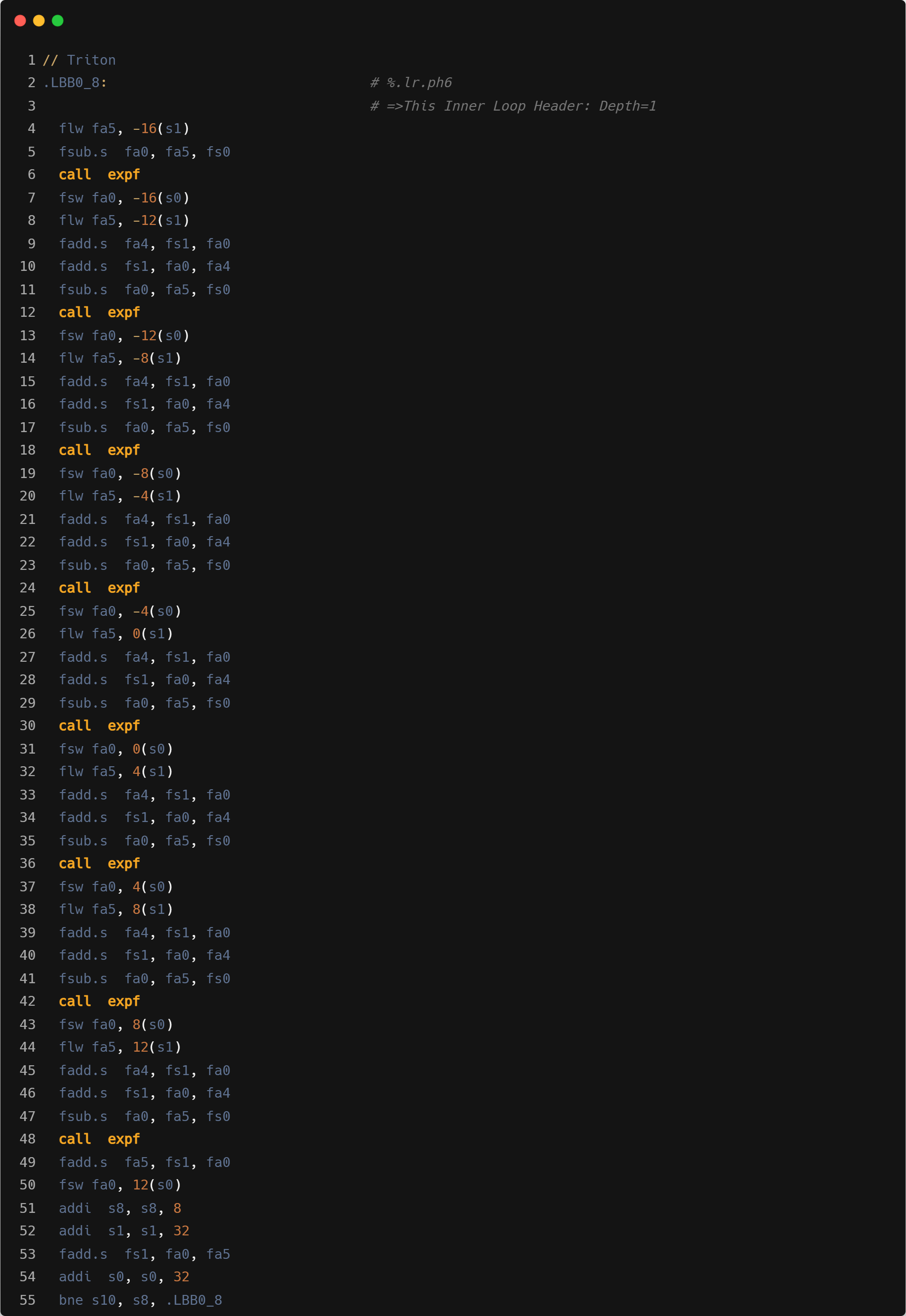
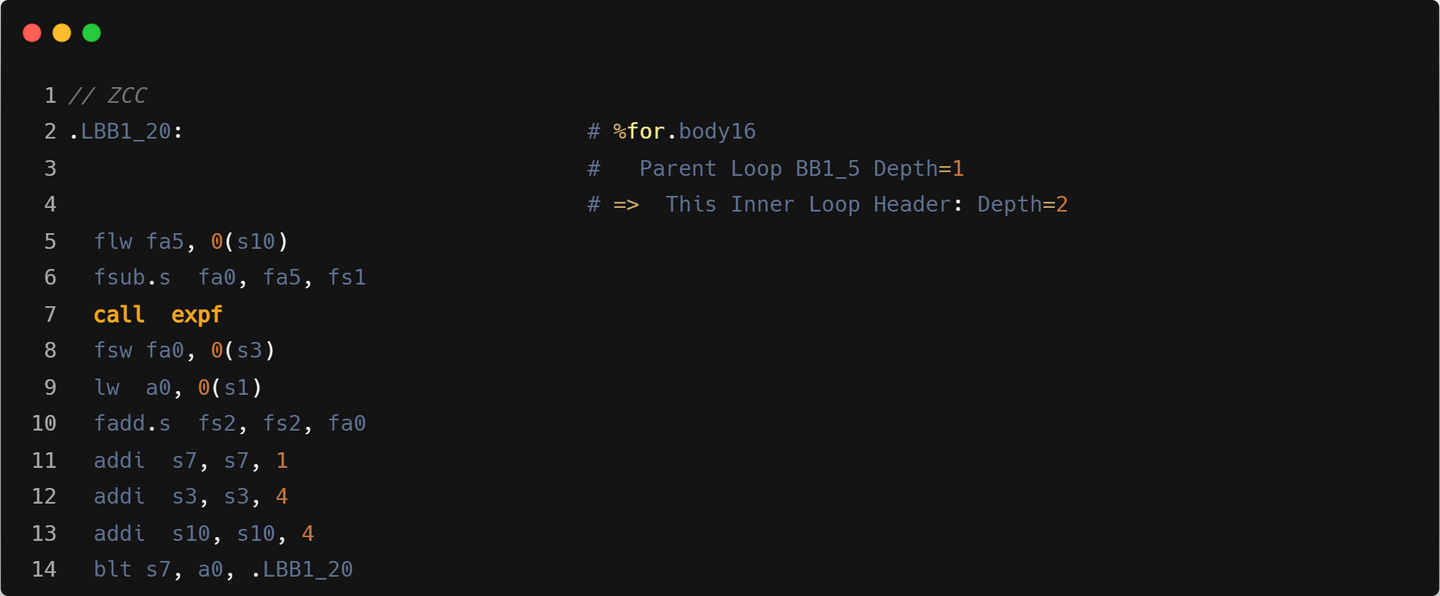
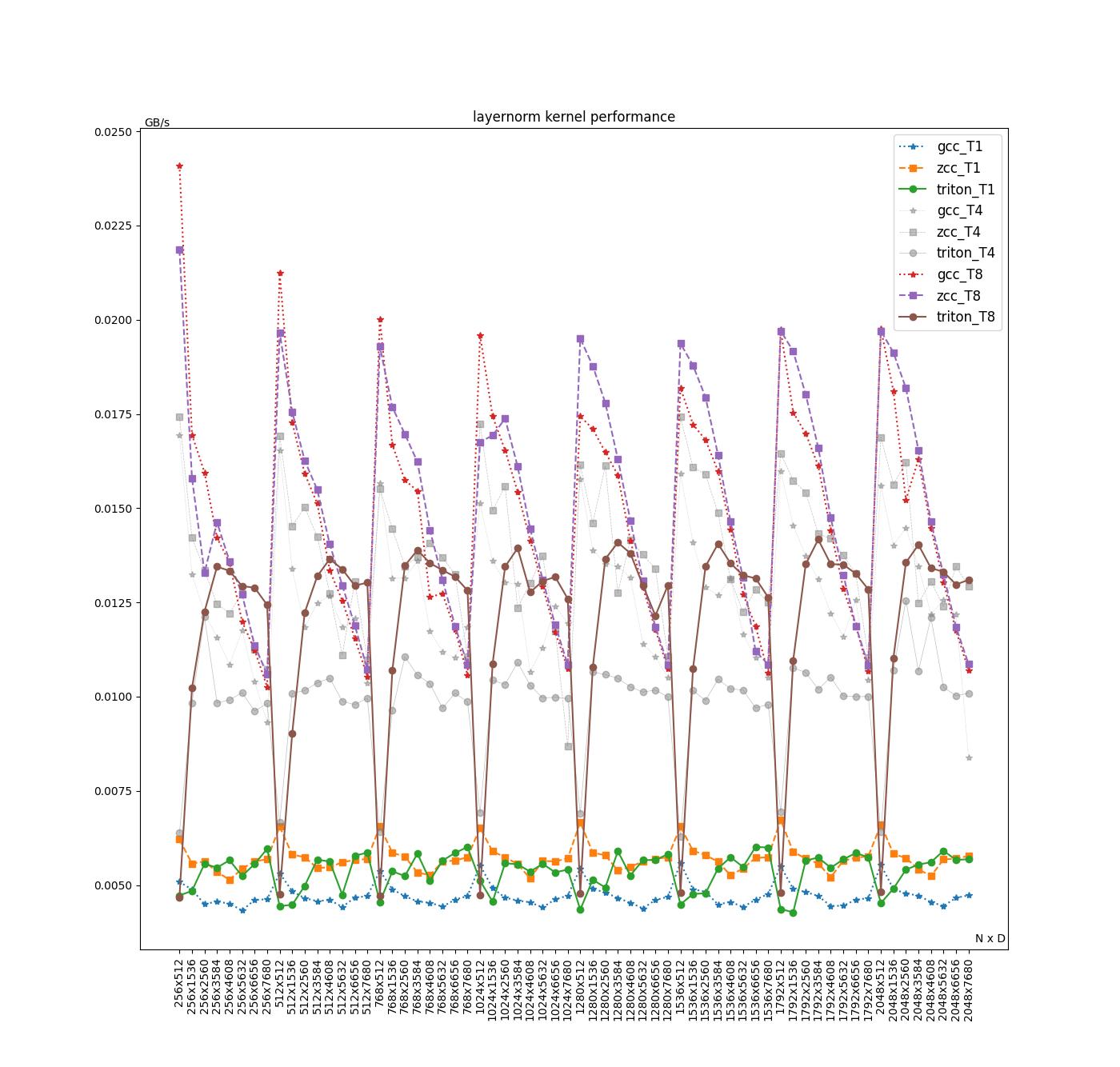
Layernorm
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.0047 | 0.0057 | 0.0053 | 93.28% | 112.83% | ||
| T4 | 0.0127 | 0.0138 | 0.0098 | 71.21% | 77.52% | 104.29% | 105.23% |
| T8 | 0.0147 | 0.0151 | 0.0118 | 78.67% | 80.33% | 101.70% | 101.56% |
| T4/T1 | 237.86% | 256.63% | 175.23% | 68.28% | 73.67% | ||
| T8/T1 | 275.60% | 281.81% | 217.99% | 77.35% | 79.09% |
注: Layernorm 统计的性能数据为 forward 算子加上 backward 算子的性能数据。
在单线程情况下,Triton 性能相较于 GCC 提升接近 13%,但是相比 ZCC 大概差 7%。然而,在四线程和八线程的多线程环境下,ZCC 和 GCC 相较于 Triton 拥有 20%至 25%的性能优势,同时 ZCC 和 GCC 在多线程的情况下,随着 shape 的变化,性能变化会较大。目前我们认为性能差距主要原因包含以下几点:
- Layernorm backward 的算子实现会导致在多线程环境下性能差距较大
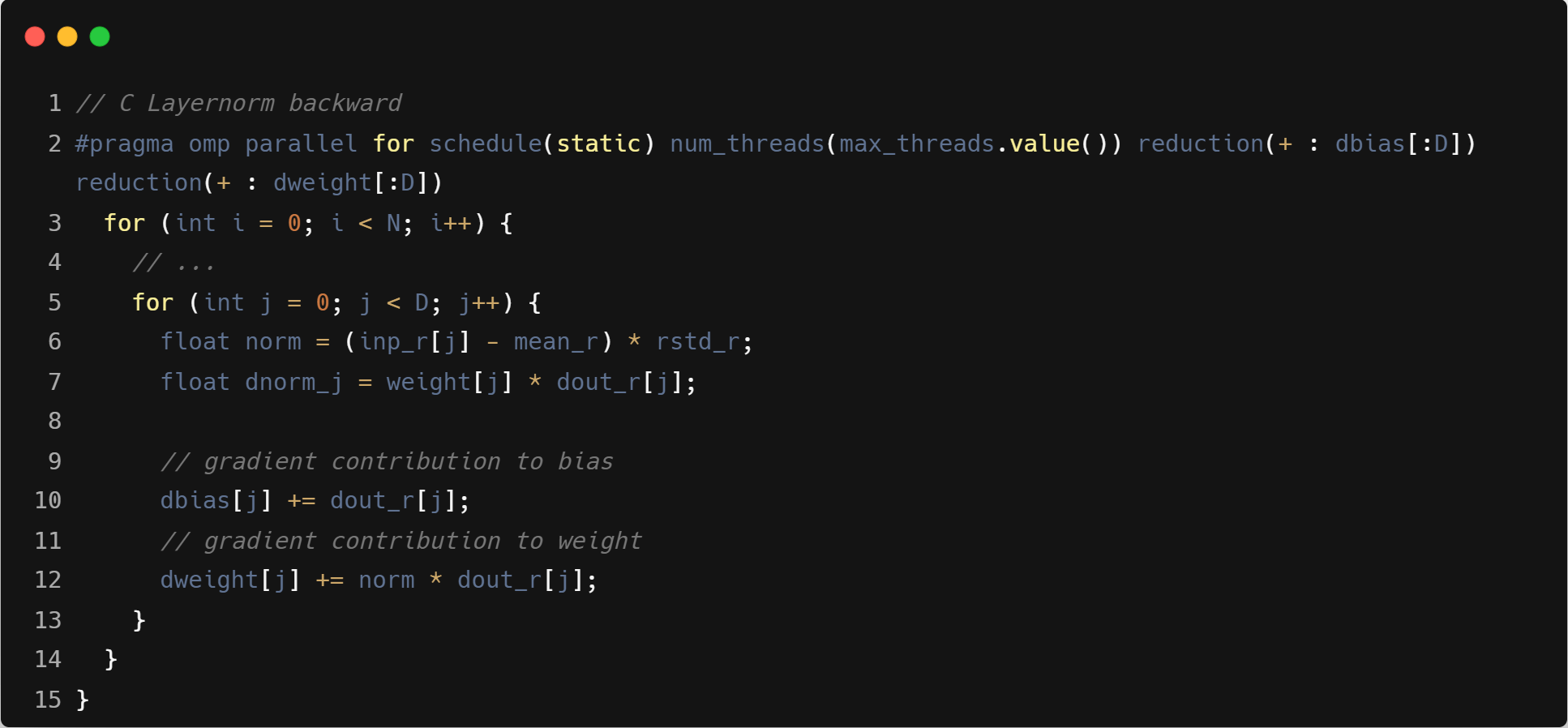
- C 算子的 reduction 操作是使用 omp 的 reduction pragma 实现
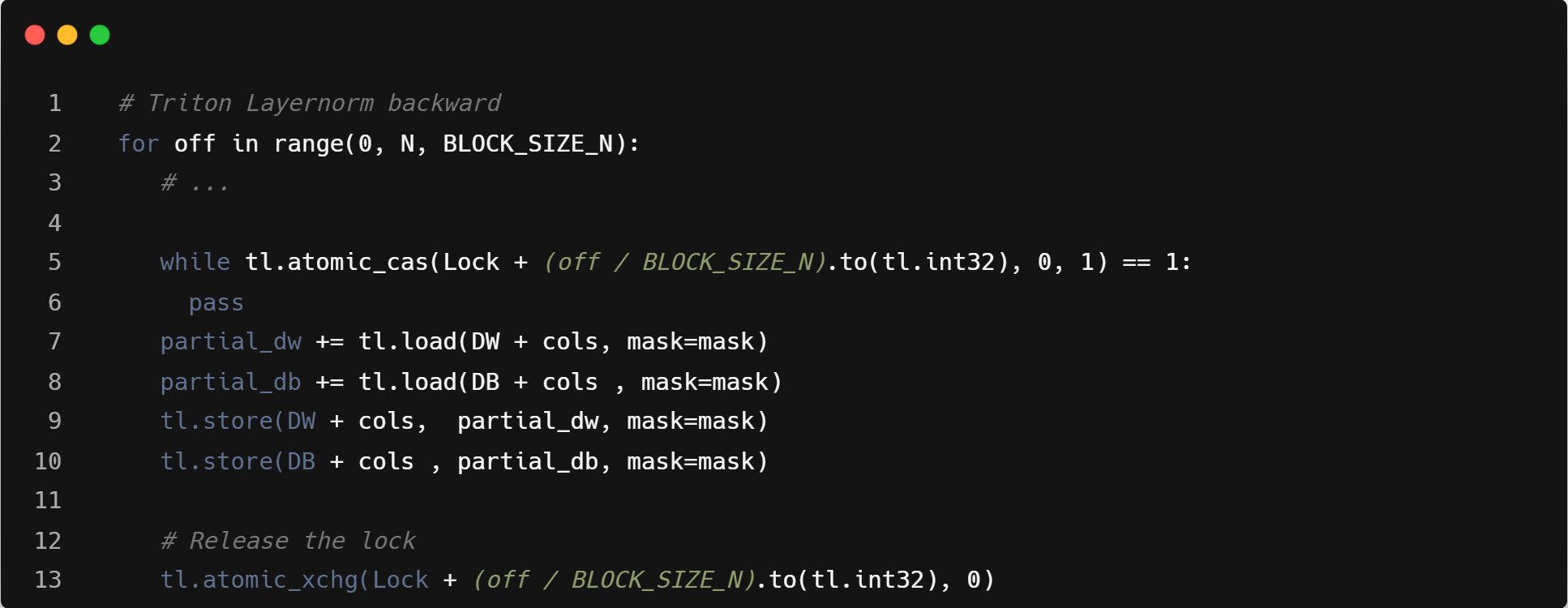
- Triton 算子的 reduction 操作,需要使用原子操作来实现
-
Layernorm 核心循环内寄存器分组
-
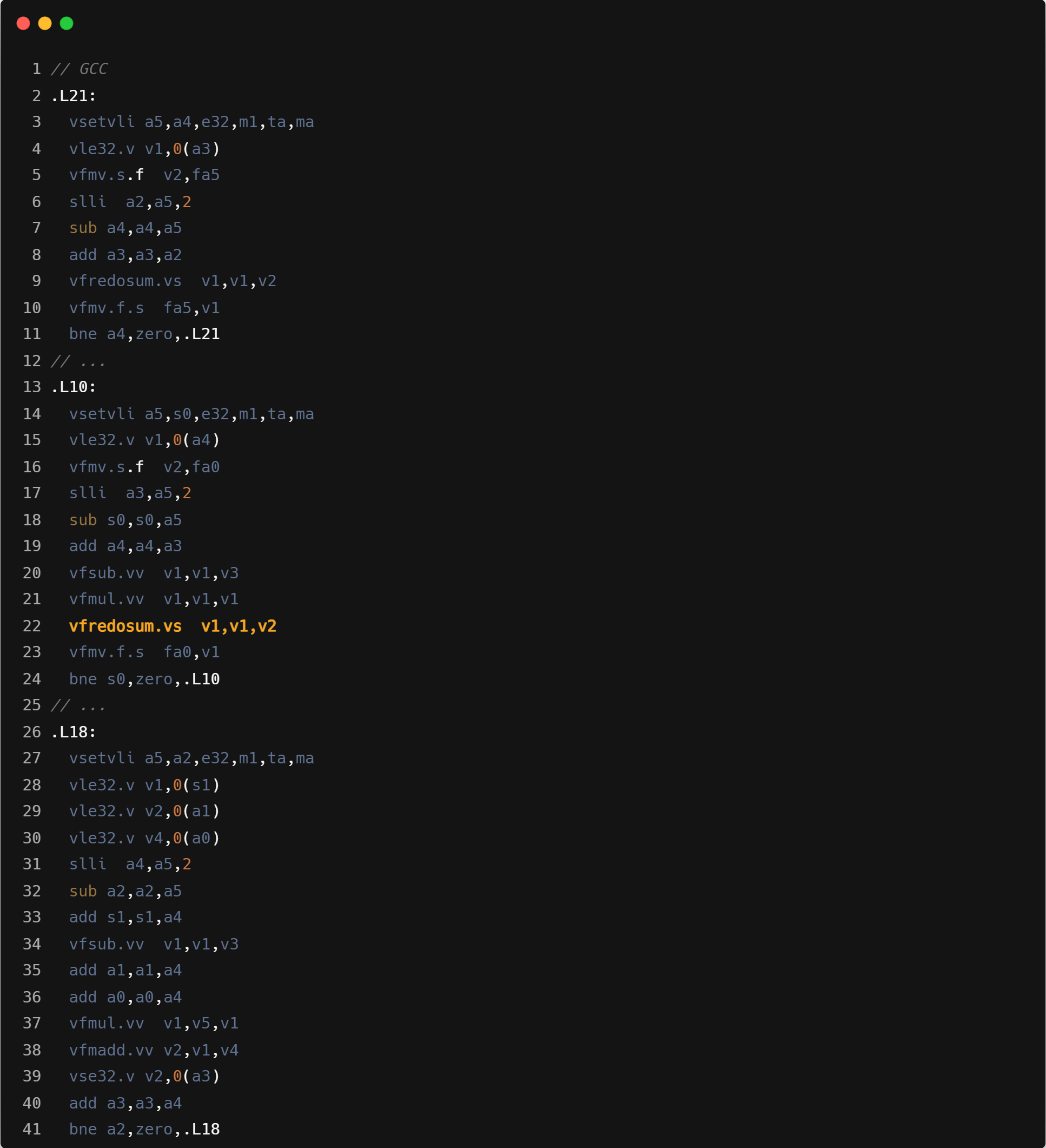
GCC 倾向于使用较小的寄存器分组,这里 forward 和 backward 两个算子均使用的 SEW/LMUL 为 e32/m1。
-
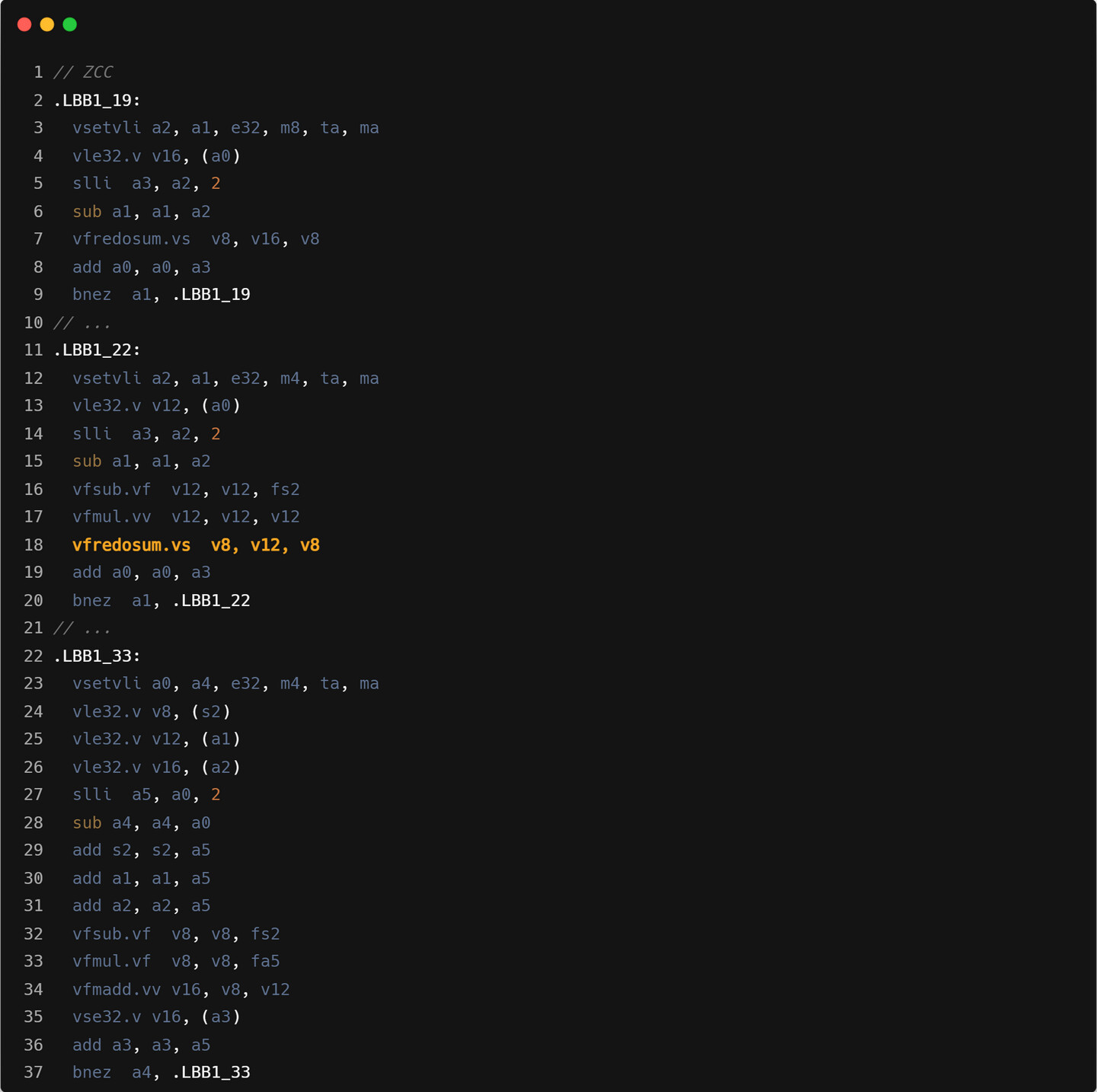
ZCC 会在不引起寄存器溢出的情况下使用较大的寄存器分组,这里 forward 算子使用的 SEW/LMUL 为 e32/m4, backward 使用的 SEW/LMUL 为 e32/m2。
-
Triton 会根据给定的分块大小使用最小的可以满足的寄存器分组,这里 forward 和 backward 两个算子均使用的 SEW/LMUL 为 e32/m2。
尝试给 GCC 添加参数 “-mrvv-max-lmul=m2” ,使用的 SEW/LMUL 变为 e32/m2,在单线程上性能提升 10%。
-
forward 算子三段核心循环
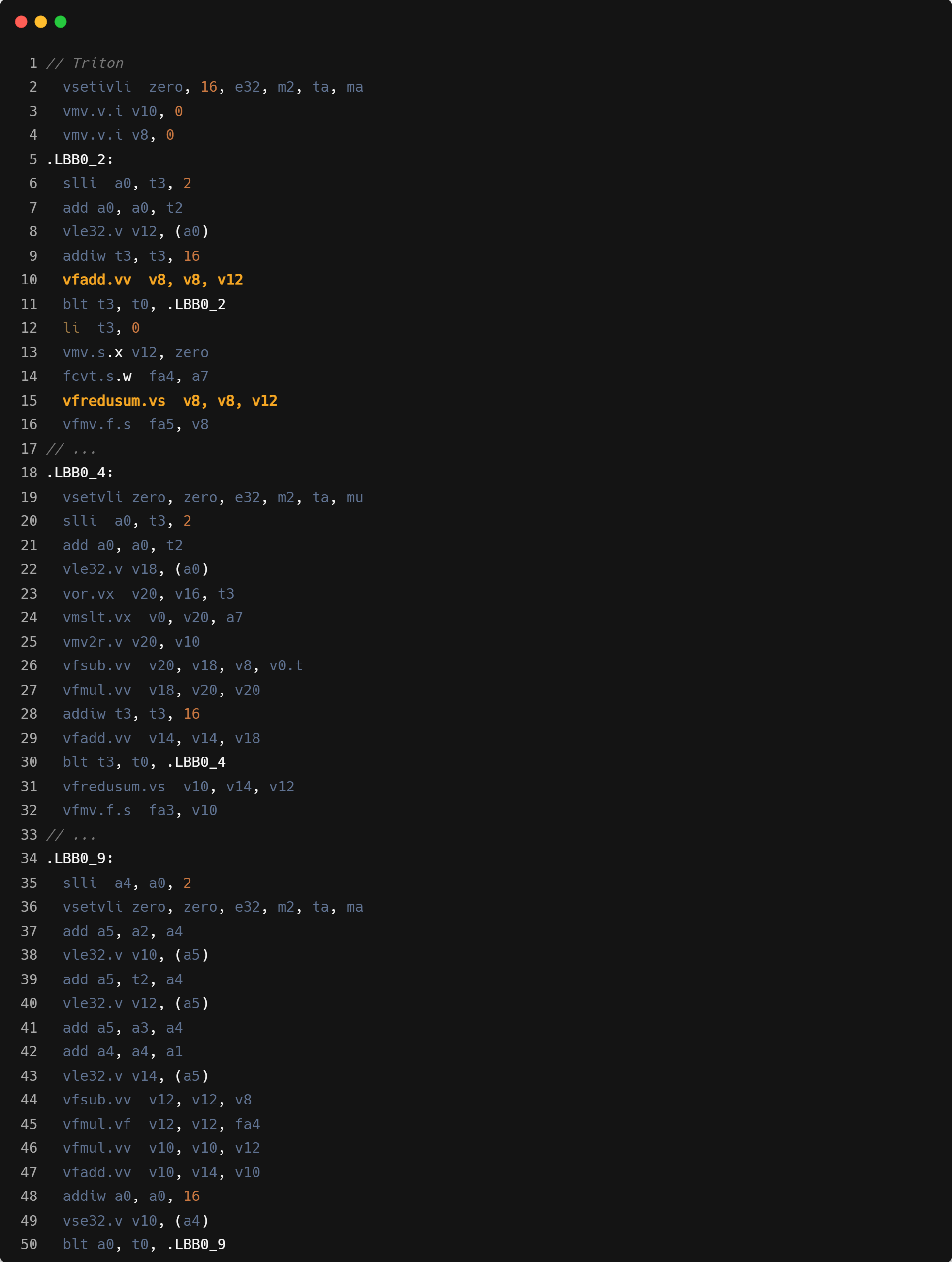
backward 算子两段核心循环
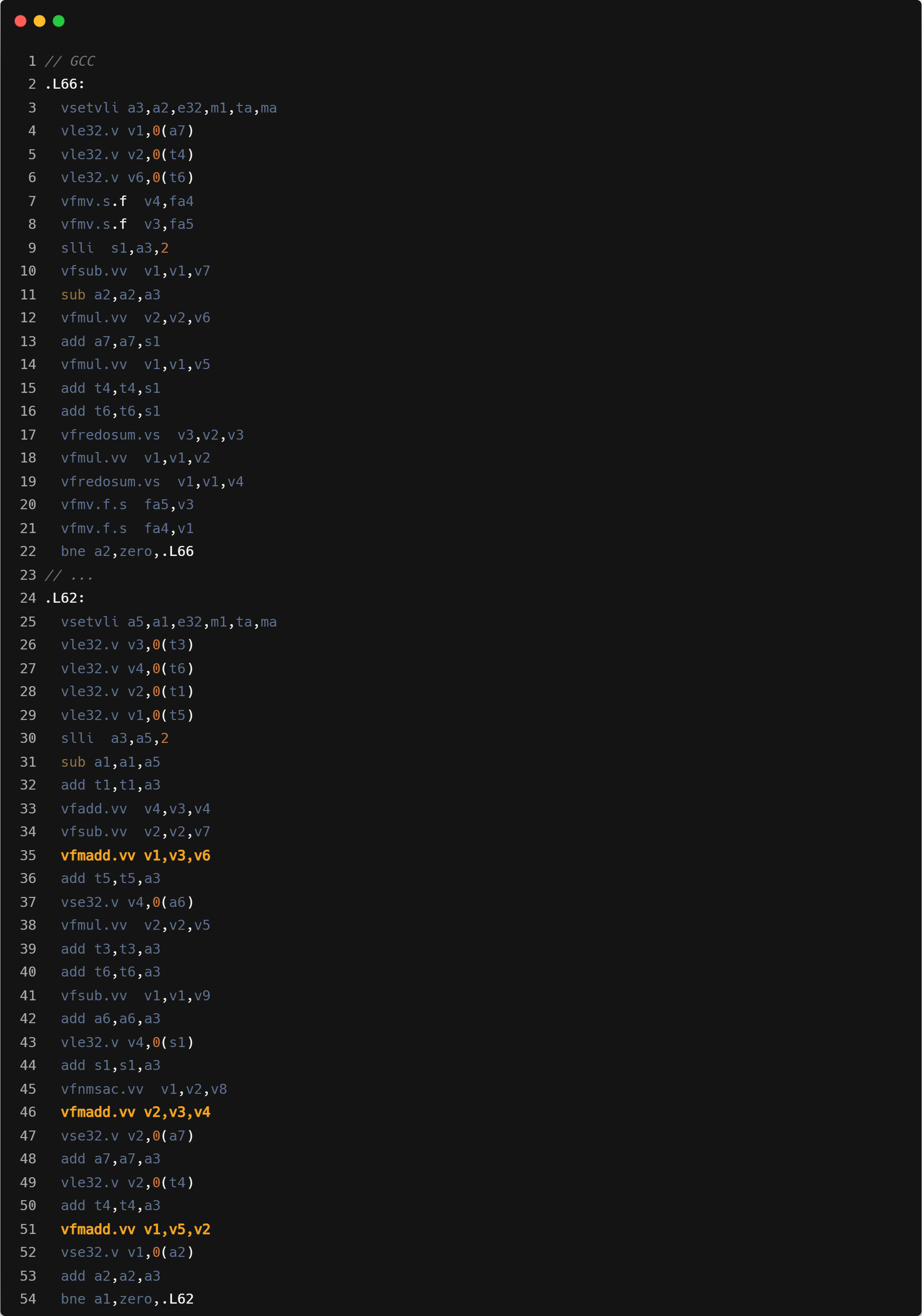
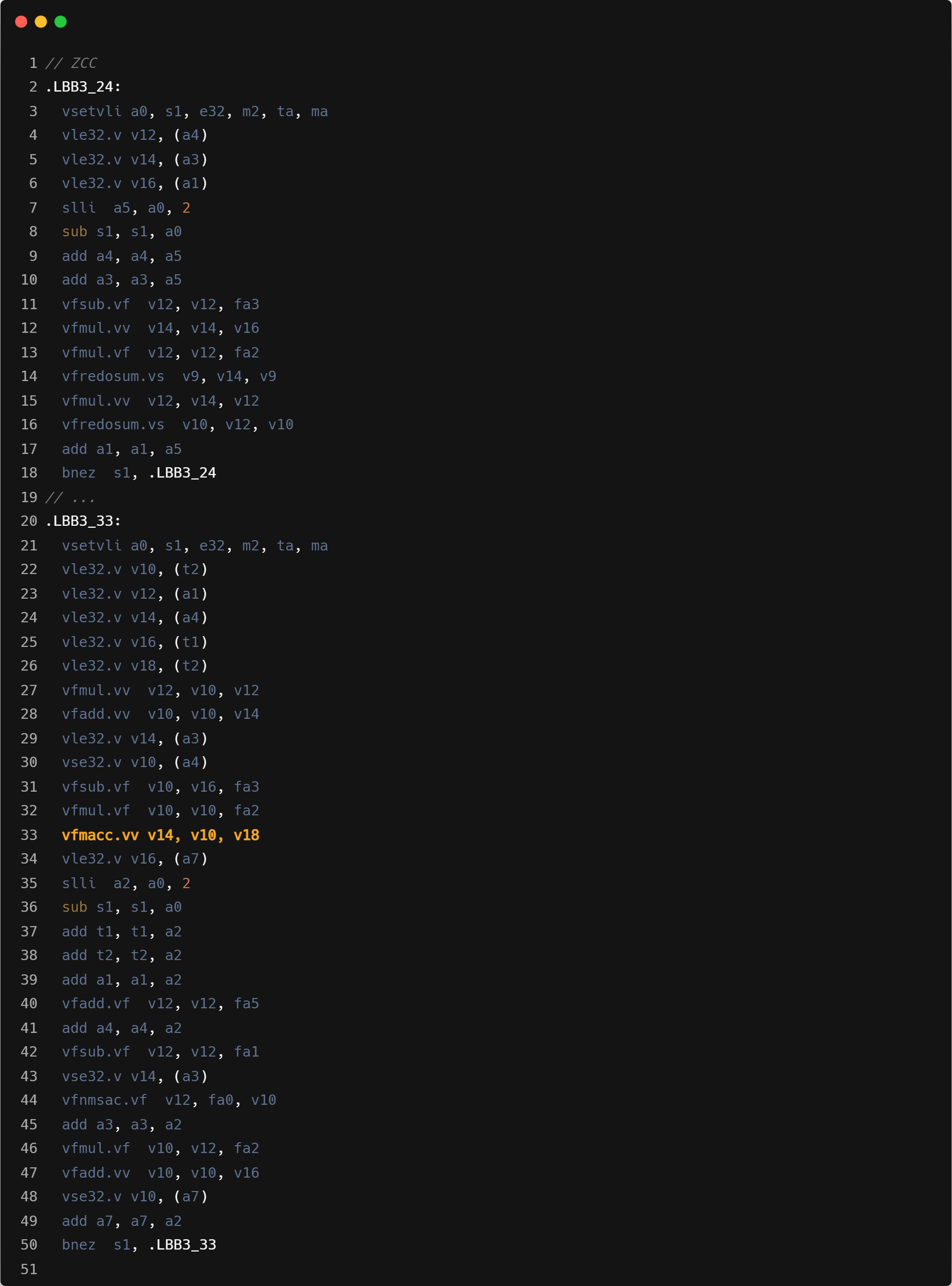
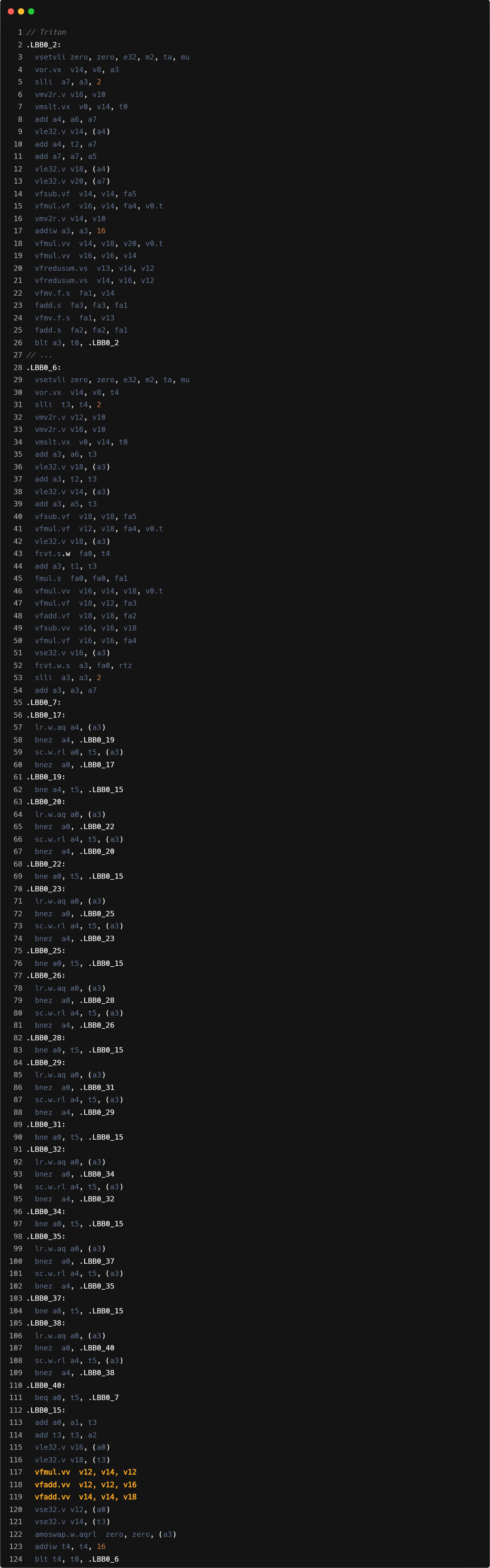
- Mask load:Triton 循环内指令数会更多,主要是因为需要处理显式的带 mask 的 load 操作计算。可能在单线程性能上和 ZCC 有一定差距.
- 指令融合:GCC/ZCC 使用 vfmadd 进行乘加操作,Triton 单独进行的 mul+add。
- 循环中的 reduction 优化: forward 部分,Triton 采用了在循环外 vfredusum,循环内按照 vfadd 计算的方式,通常性能会更加优化。
Resize
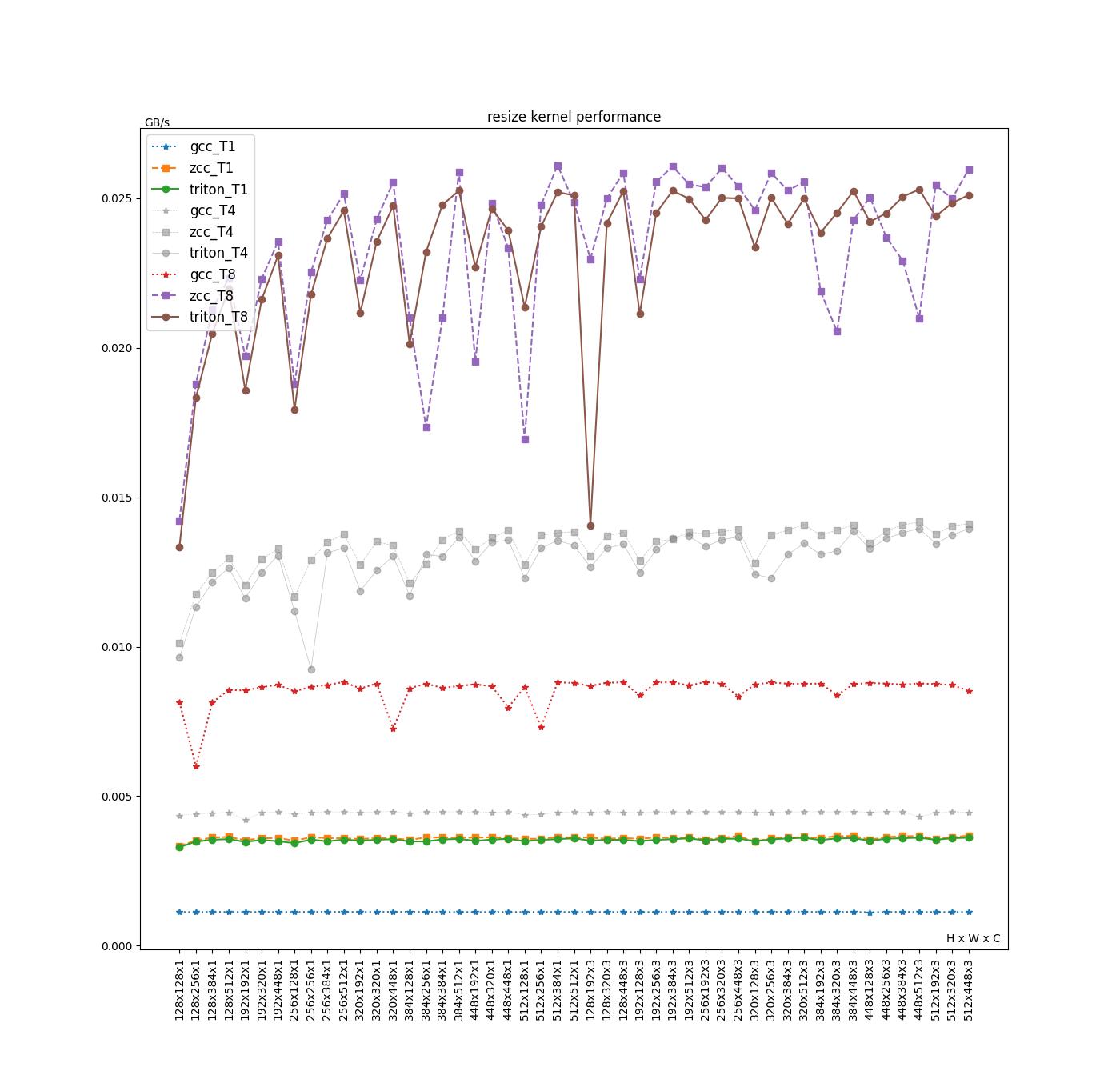
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.0011 | 0.0036 | 0.0035 | 98.43% | 314.69% | ||
| T4 | 0.0044 | 0.0134 | 0.0129 | 96.35% | 289.70% | 100.00% | 100.07% |
| T8 | 0.0086 | 0.0231 | 0.0231 | 100.35% | 269.72% | 100.01% | 100.11% |
| T4/T1 | 125.67% | 377.60% | 363.81% | 96.35% | 289.49% | ||
| T8/T1 | 242.47% | 650.97% | 653.24% | 100.35% | 269.42% |
Triton 与 ZCC 在各个线程和输入 shape 上,整体性能相近;而 GCC 的性能相对较差。目前我们认为性能差距主要原因是:
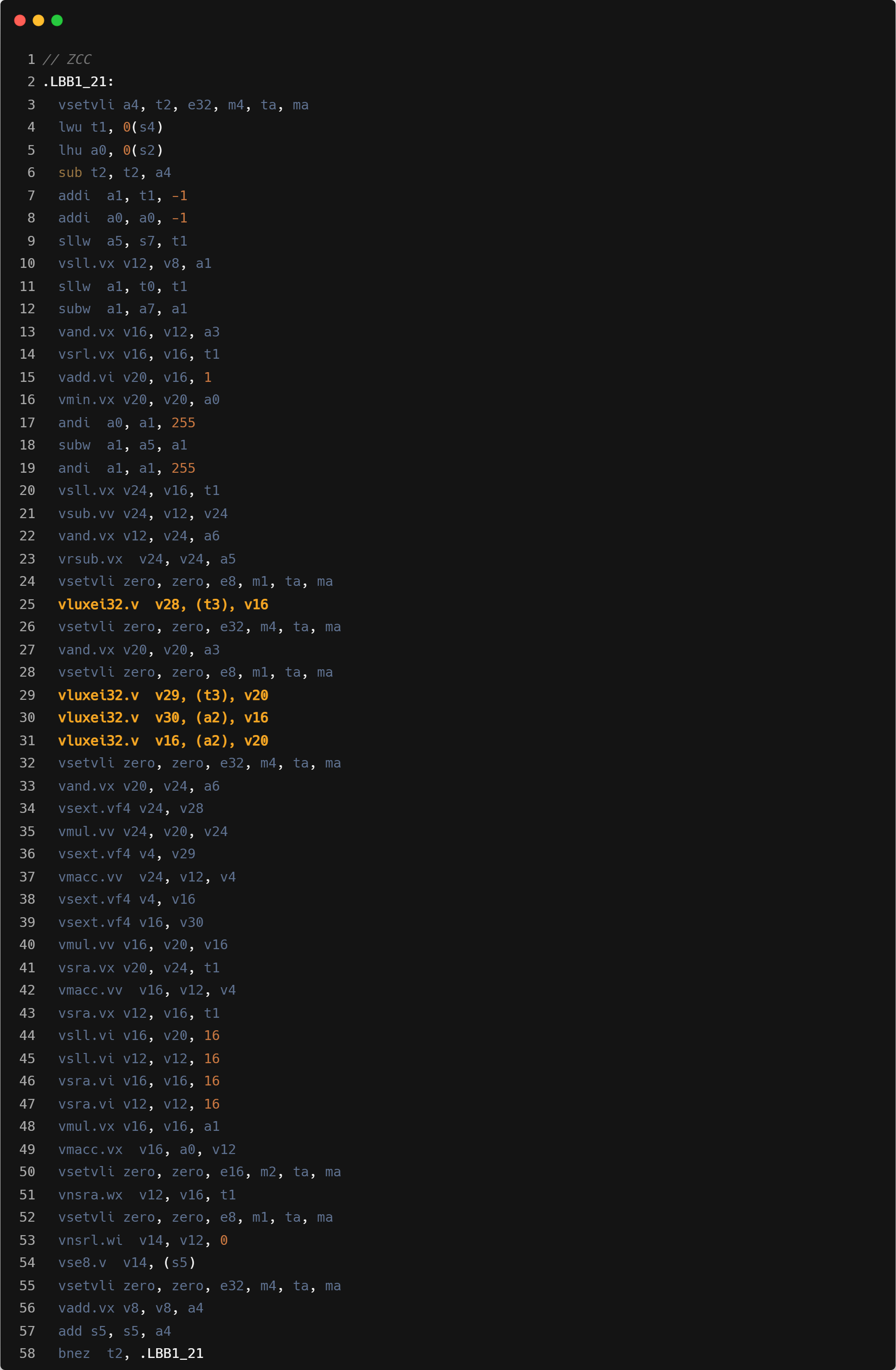
- 访存指令的翻译方式:如下文核心循环汇编中 highlight 的位置,GCC 针对离散的访存采用了 strided load 的方式,会生成许多额外的指令来用于实现 strided load。而 ZCC 和 Triton 会直接使用 index load,相对 GCC 会生成更少的指令,并且没有产生 permutation 类型的指令(
vslidedown等)。具体来说,在下文的 C 源码中,src_ptr0和src_ptr1的索引数据(x0和x1)都是变量,且不存在固定的 stride 长度,因此不适合使用 strided load。然而,GCC 仍然使用了 strided loadvlse8.vv5,0(a3),zero指令(strided 值为 0),并通过vslidedown.vi和vmv.x.s将向量寄存器中的每个元素提取到标量寄存器进行运算,产生了大量不必要的指令。这种优化方式实际上是一种反向优化。

Warp
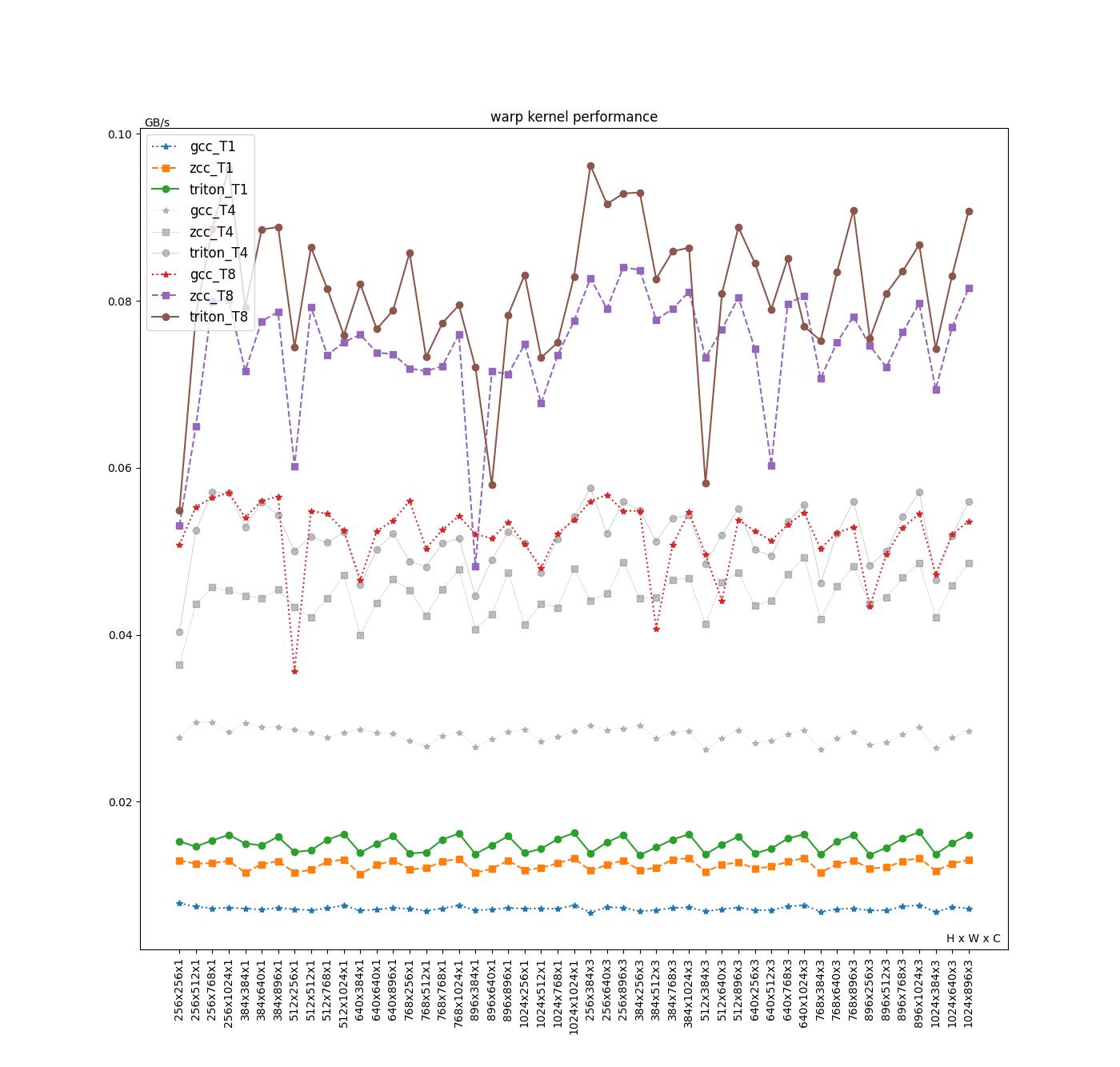
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.007 | 0.012 | 0.015 | 120.39% | 208.86% | ||
| T4 | 0.028 | 0.045 | 0.052 | 115.27% | 184.87% | 100.00% | 100.15% |
| T8 | 0.052 | 0.074 | 0.081 | 109.11% | 155.61% | 99.99% | 100.04% |
| T4/T1 | 187.51% | 300.27% | 346.13% | 115.27% | 184.59% | ||
| T8/T1 | 349.68% | 498.48% | 543.93% | 109.12% | 155.55% |
Triton 性能整体相对于 ZCC 拥有 10% 至 20% 的性能优势,相对于 GCC 则有 50% 甚至 100% 的性能优势。目前我们认为性能差距主要原因包含以下几点:
- 核心循环内寄存器分组
- GCC 倾向于使用较小的寄存器分组,这里使用的 SEW/LMUL 为 e64/m1;
- ZCC 和 Triton 使用的最大的 SEW/LMUL 为 e64/m8。
- 优化:给 GCC 尝试添加参数 “-mrvv-max-lmul=m8” ,使用的 SEW/LMUL 变为 e64/m8,在单线程上性能上提升 100%。
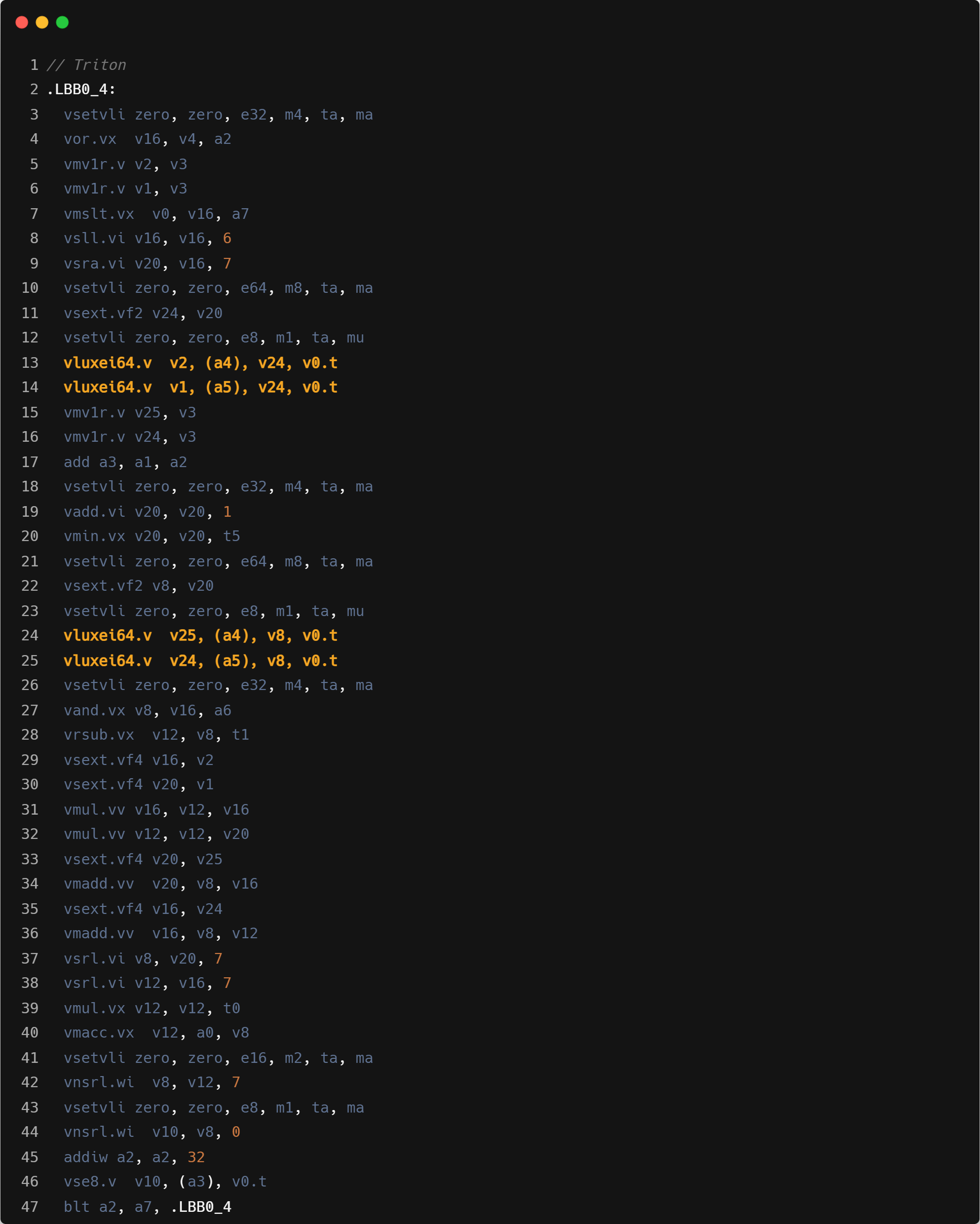
- 核心循环内 ZCC 将其中的一个顺序访问操作翻译成了 index load 的操作, index load 相对于 unit stride load 性能会更差。如下文核心循环汇编中 highlight 的三条用于读取输入数组数据的访存指令。
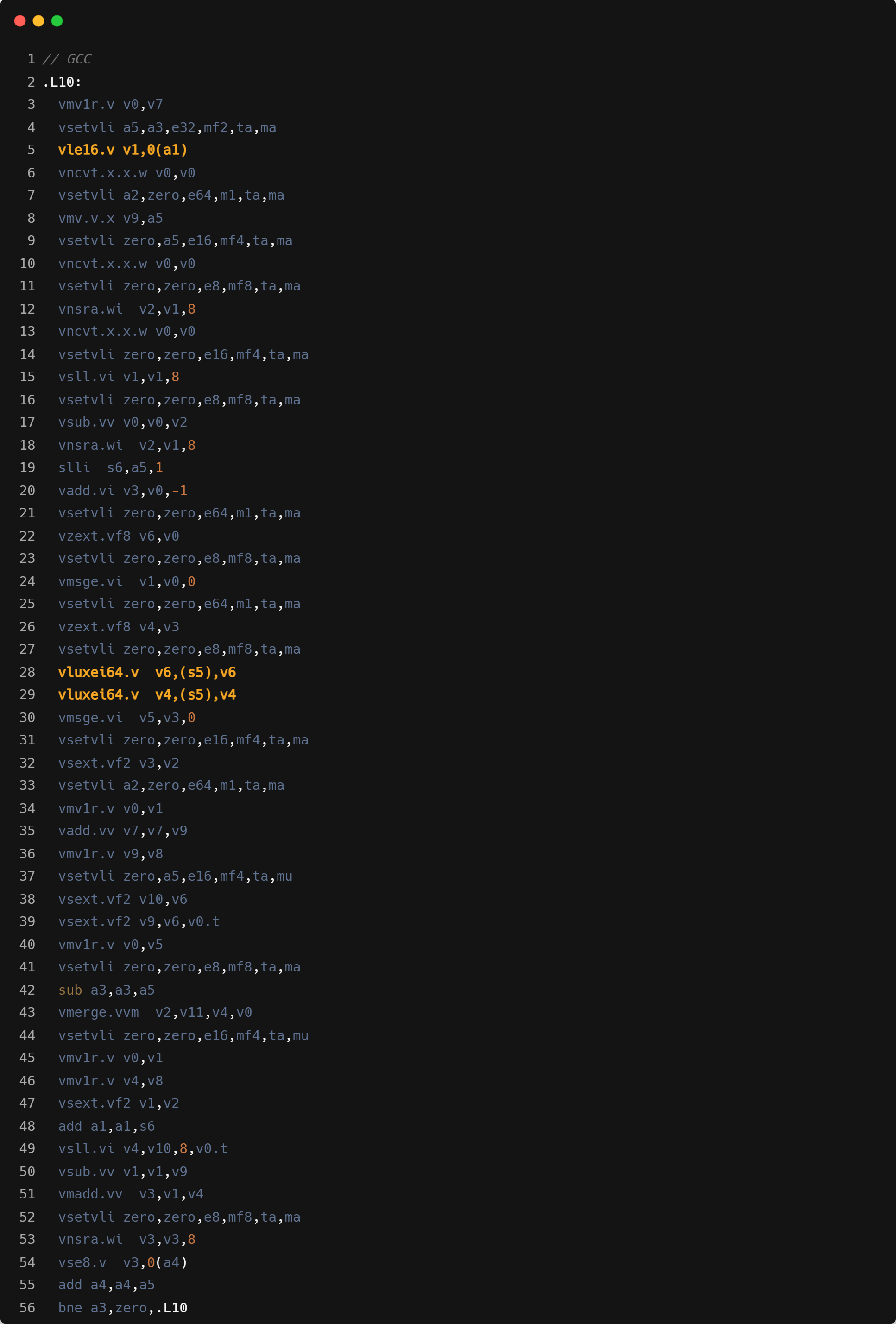
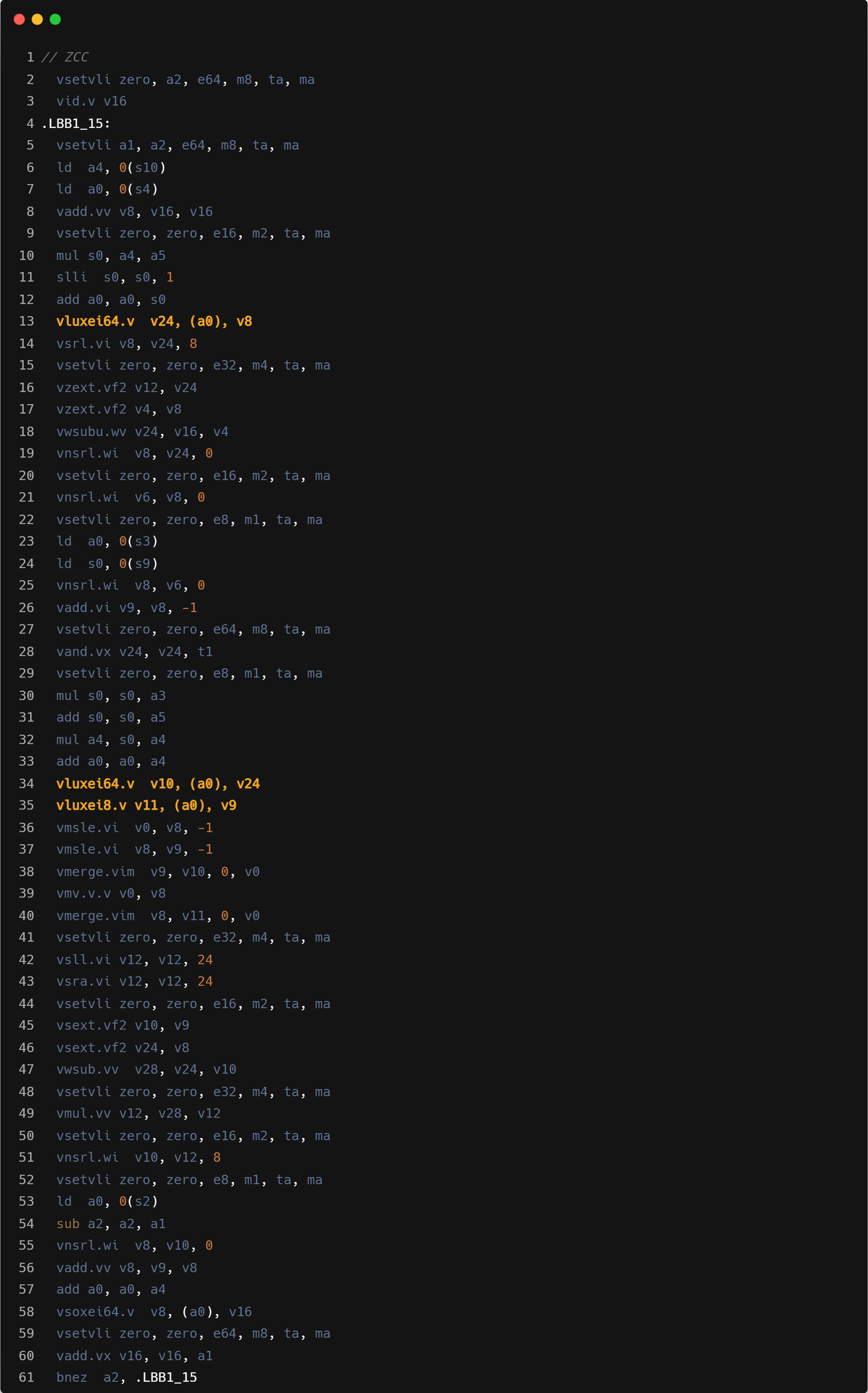
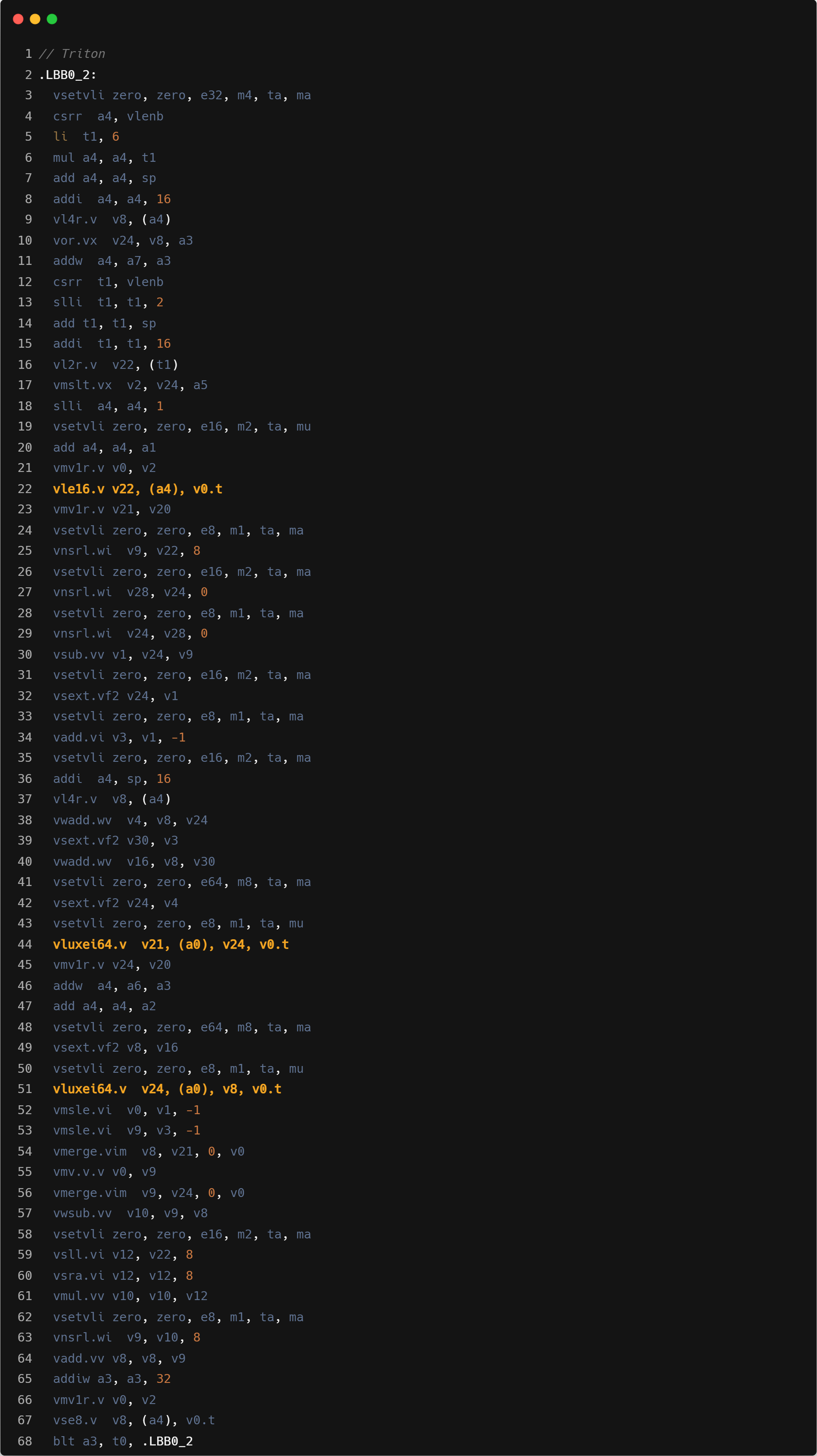
Correlation
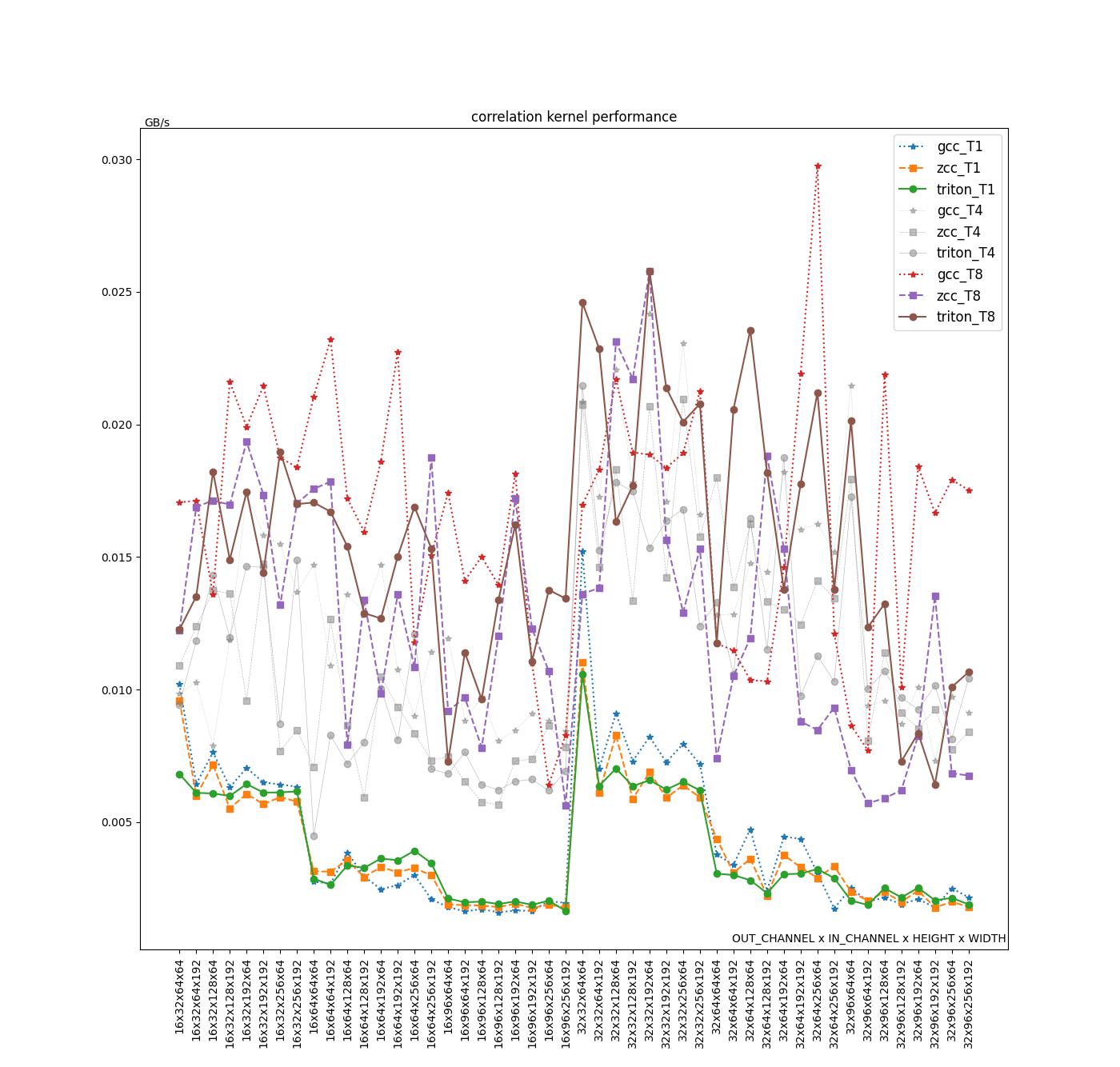
| Average(GB/s) | GCC | ZCC | Triton | Triton/ZCC | Triton/GCC | (Triton/ZCC)/(TN/T1) | (Triton/GCC)/(TN/T1) |
|---|---|---|---|---|---|---|---|
| T1 | 0.0043 | 0.0040 | 0.0039 | 98.34% | 90.76% | ||
| T4 | 0.0133 | 0.0115 | 0.0112 | 97.89% | 84.46% | 101.54% | 101.85% |
| T8 | 0.0165 | 0.0129 | 0.0155 | 120.48% | 93.83% | 101.35% | 101.39% |
| T4/T1 | 389.66% | 335.16% | 323.12% | 96.41% | 82.92% | ||
| T8/T1 | 502.17% | 390.96% | 464.75% | 118.87% | 92.55% |
在单,四线程下,Triton 性能与 ZCC 接近。在八线程下,Triton 相对于 ZCC 拥有 20%的性能优势。GCC 整体性能相对于 Triton 有 10-15%的性能优势。目前我们认为性能差距主要原因包含以下几点:
-
主循环的寄存器分组
-
GCC 使用的 SEW/LMUL 为 e8/mf2。
-
ZCC 使用的 SEW/LMUL 为 e8/m4。
-
Triton 使用的 SEW/LMUL 为 e8/mf4
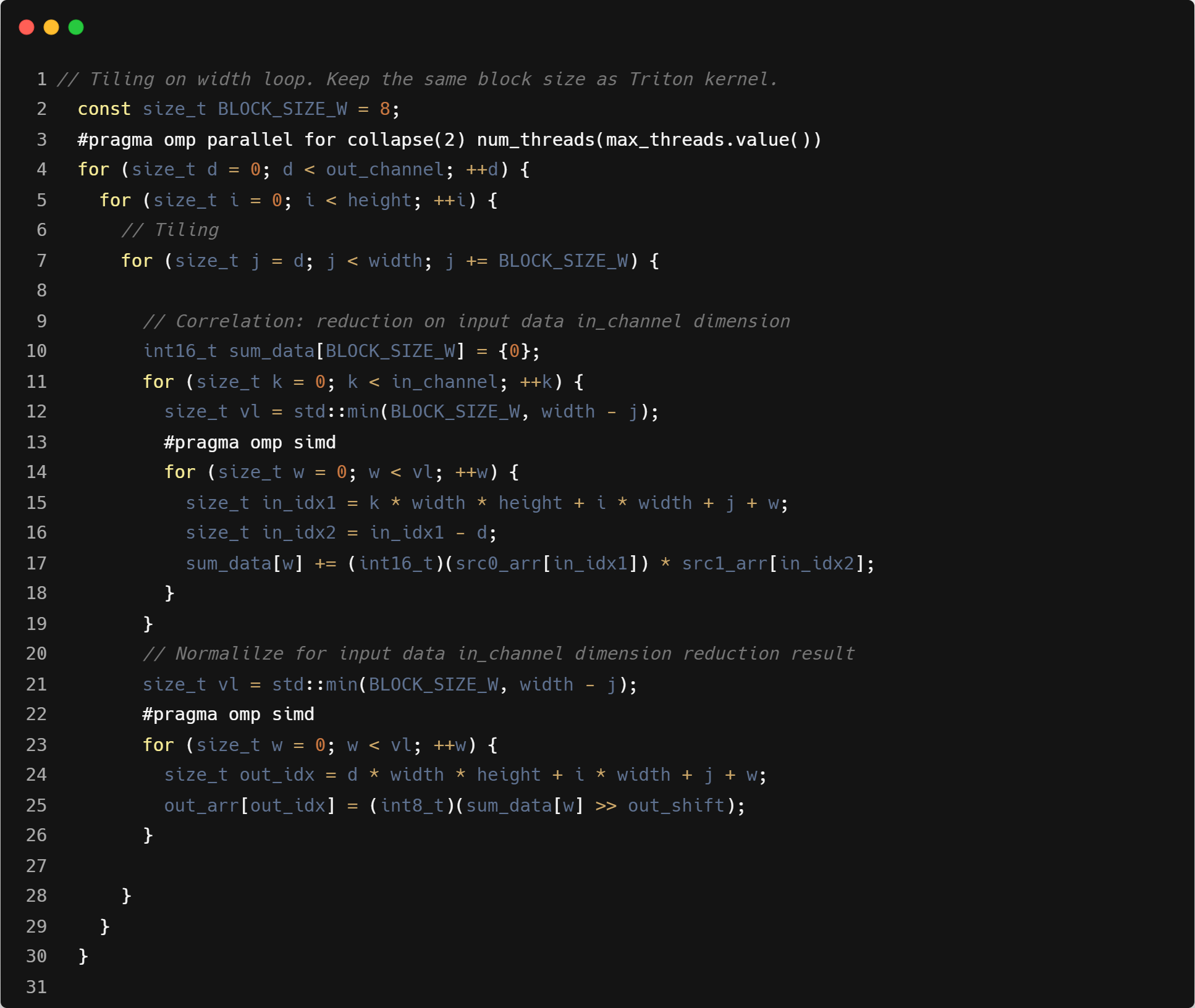
为了对齐 Triton 和 C 算子的实现,需要给 C 算子添加 width 维度的向量化。然而,当前版本的 GCC 不支持此功能,且 ZCC 也 未启用。因此,我们手动引入了针对 width 维度的 tiling 操作 以实现向量化。由于 tiling 大小较小,ZCC 相对于 GCC 无法 充分利用更大的寄存器分组,性能会有一定的差距。
如下是 Correlation 的 C 算子针对输入数据的 width 维度 t iling 后的实现:
-
-
ZCC RVV 寄存器分组调整优化。手动调整寄存器的分组:e8/m4 => e8/mf2;e32/m4 => e32/m1。可以看到单线程时获得 10 %的提升,四线程时获得 9 %的提升,八线程时获得 30 %的提升。
Average(GB/s) ZCC Triton Triton/ZCC T1 0.0044 0.0039 88.44% T4 0.0126 0.0112 88.95% T8 0.0185 0.0155 83.89% -
指令融合:如下文核心循环汇编中,GCC/ZCC 使用 vwmacc 进行乘加操作,Triton 单独进行的 mul+add。

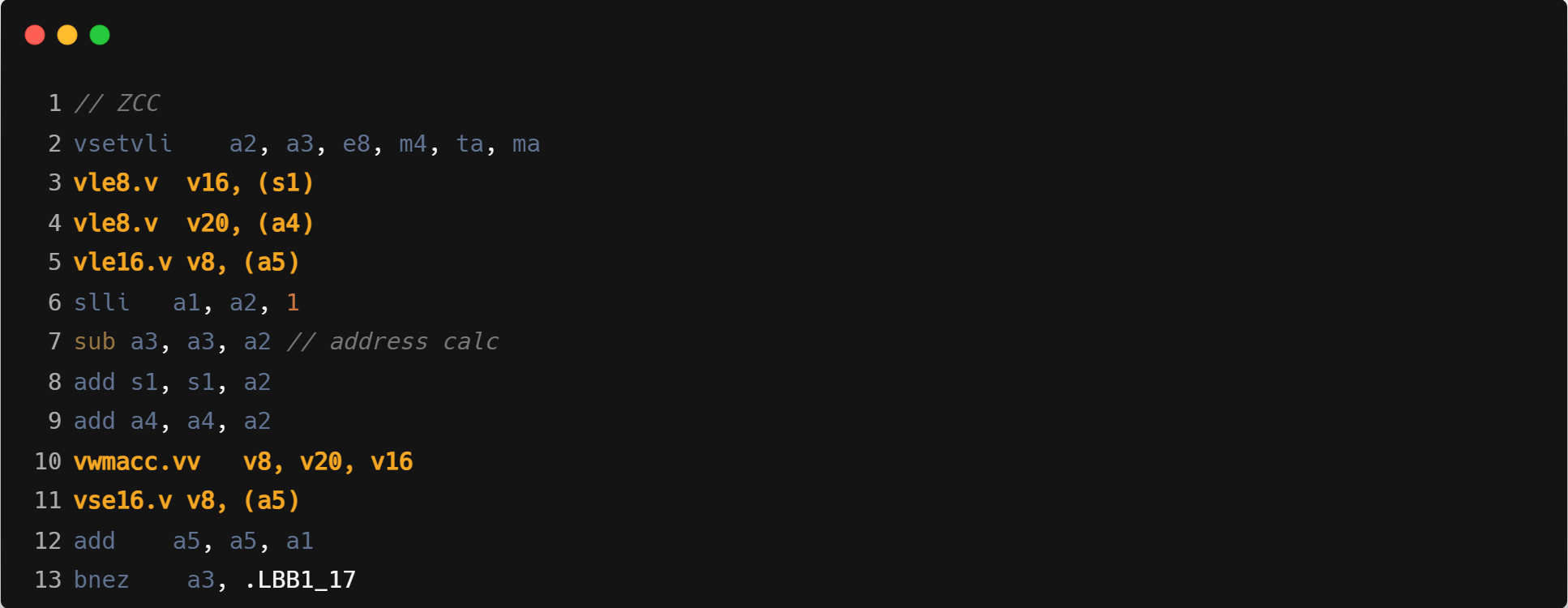
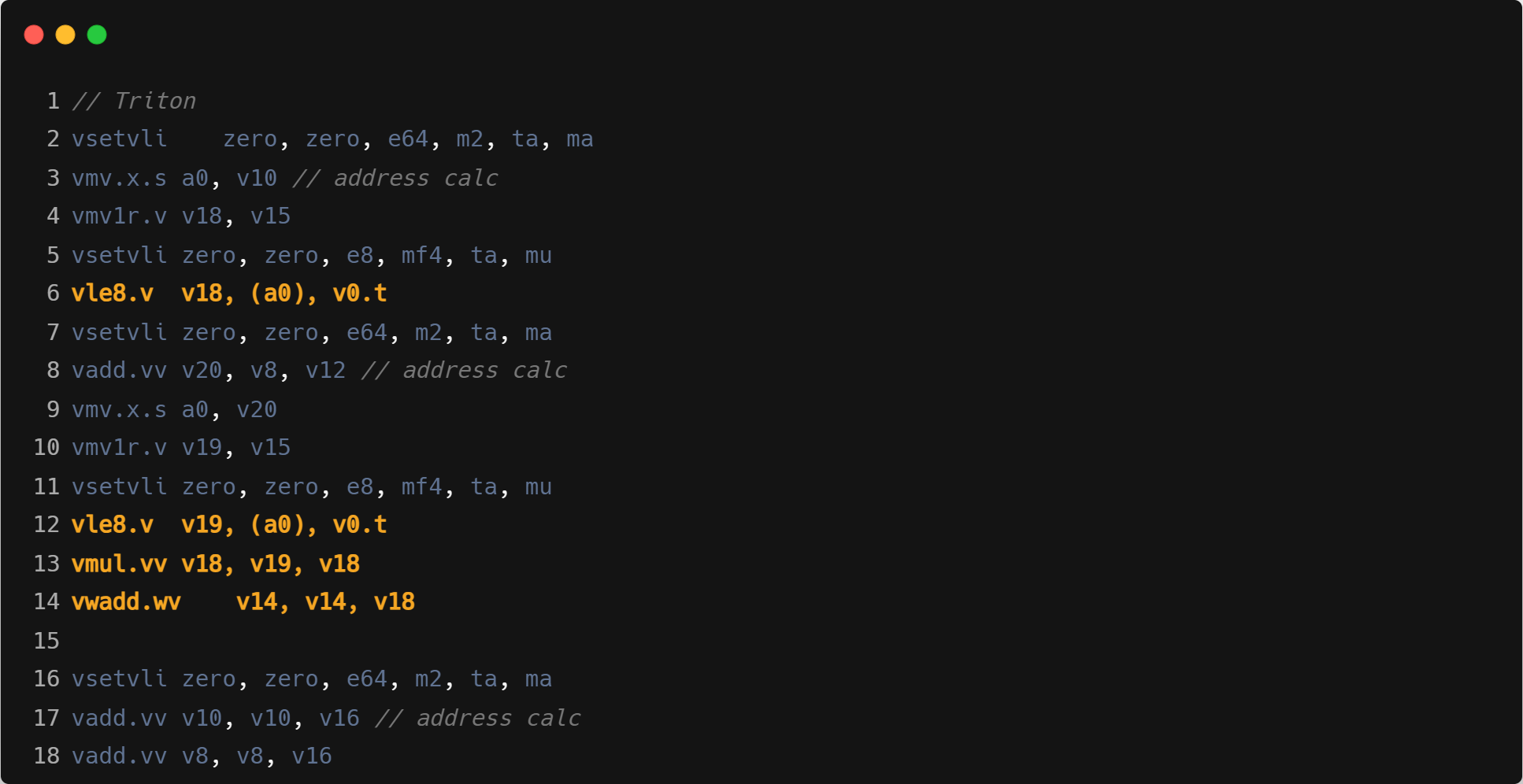
- 访存地址计算:Triton 计算地址时使用向量指令,但只使用向量寄存器的第一个元素,实际行为与标量一样,会生成冗余的 vmv1r.v 操作,而 GCC/ZCC 直接使用标量的运算。
Triton-CPU 性能问题总结
在整个实验过程中,我们对 Triton 算子转换流水线中的中间表示 MLIR、Triton 算子生成的汇编代码以及 C 算子生成的汇编代码进行了深入而详尽的分析。针对分析中发现的若干问题,我们实施了试验性的优化措施,以提升 Triton-CPU 编译效率和生成代码的性能。通过这些优化实验,我们最终发现,目前的 Triton-CPU 编译器相比于成熟的 C 编译器,主要存在以下几个需要改进的方面。
寄存器溢出
Triton 语言采用了 SPMD(Single Program Multiple Data,单程序多数据)编程模型。这种模型允许在不同的数据块上并行执行相同的程序,从而充分利用现代处理器的并行计算能力。
然而,目前 Triton-CPU 编译器在 IR Lowering 的过程中尚未达到最优状态。在算子中,每个线程处理的切块后的元素我们称为张量(多维数组的切块)。张量的逐步运算最终 lower 到底层汇编代码时,会生成大量的向量操作(如果硬件支持相应的向量拓展指令集)。每一步运算都需要计算整个张量的数据,因此需要大量的寄存器来存储输入输出张量和中间结果。
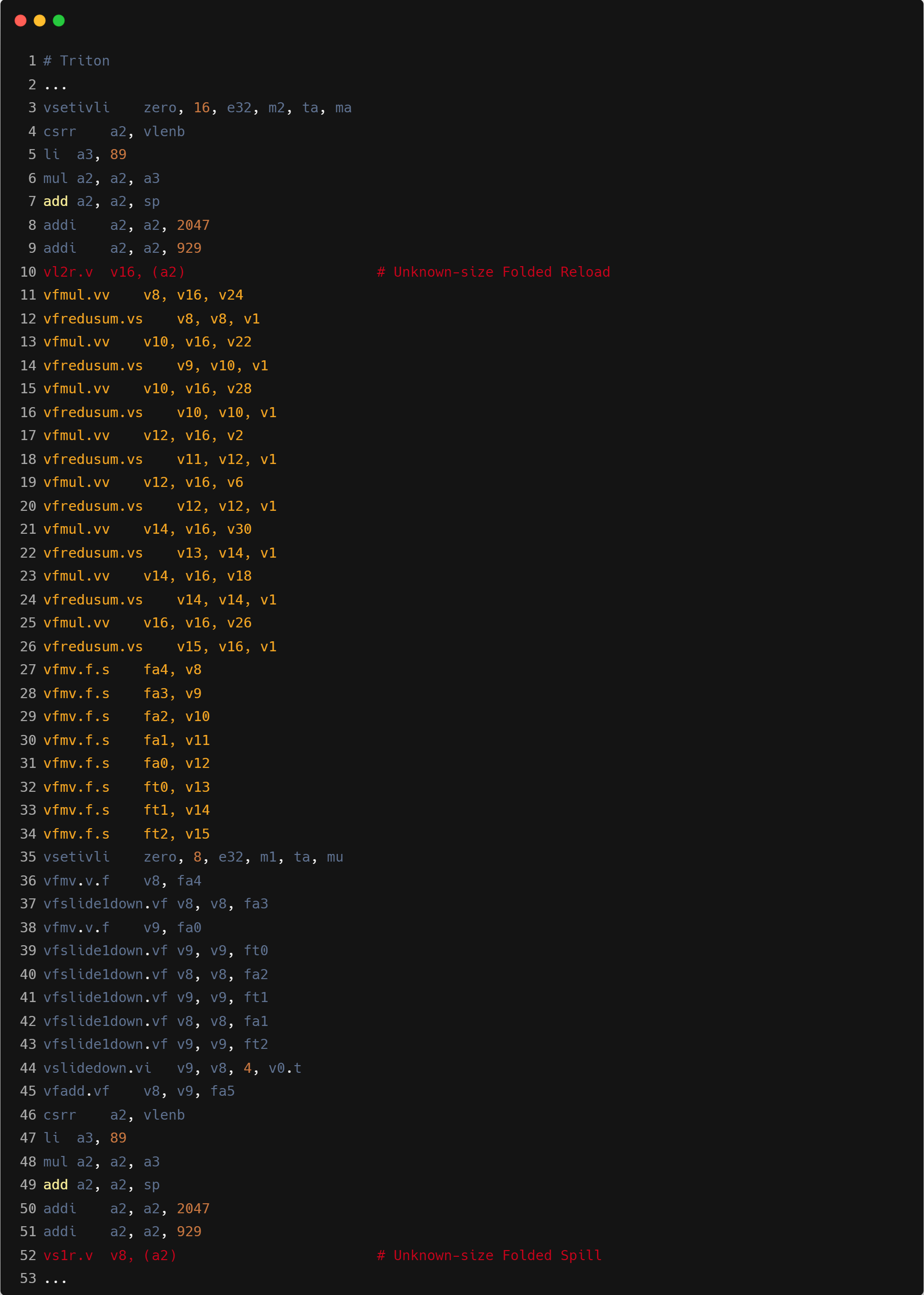
在 GPU 上,由于拥有较多的寄存器资源,编译器能够高效地处理较大块的张量。然而,CPU 核心上的寄存器数量相对有限。当进行大规模数据切分时,如果每个线程需要处理的数据量过大,可能导致张量无法完全存储在寄存器中,从而引发寄存器溢出(spill)的问题。寄存器溢出会迫使编译器将部分寄存器中的数据临时存储到内存中,这不仅增加了内存访问的频次和延迟,还进一步影响了程序的整体性能。因此,在使用 Triton 编写算子时,数据的 tiling(分块)策略对于程序的性能优化至关重要。如下是Correlation算子分块大小128x128时寄存器溢出的汇编展示:
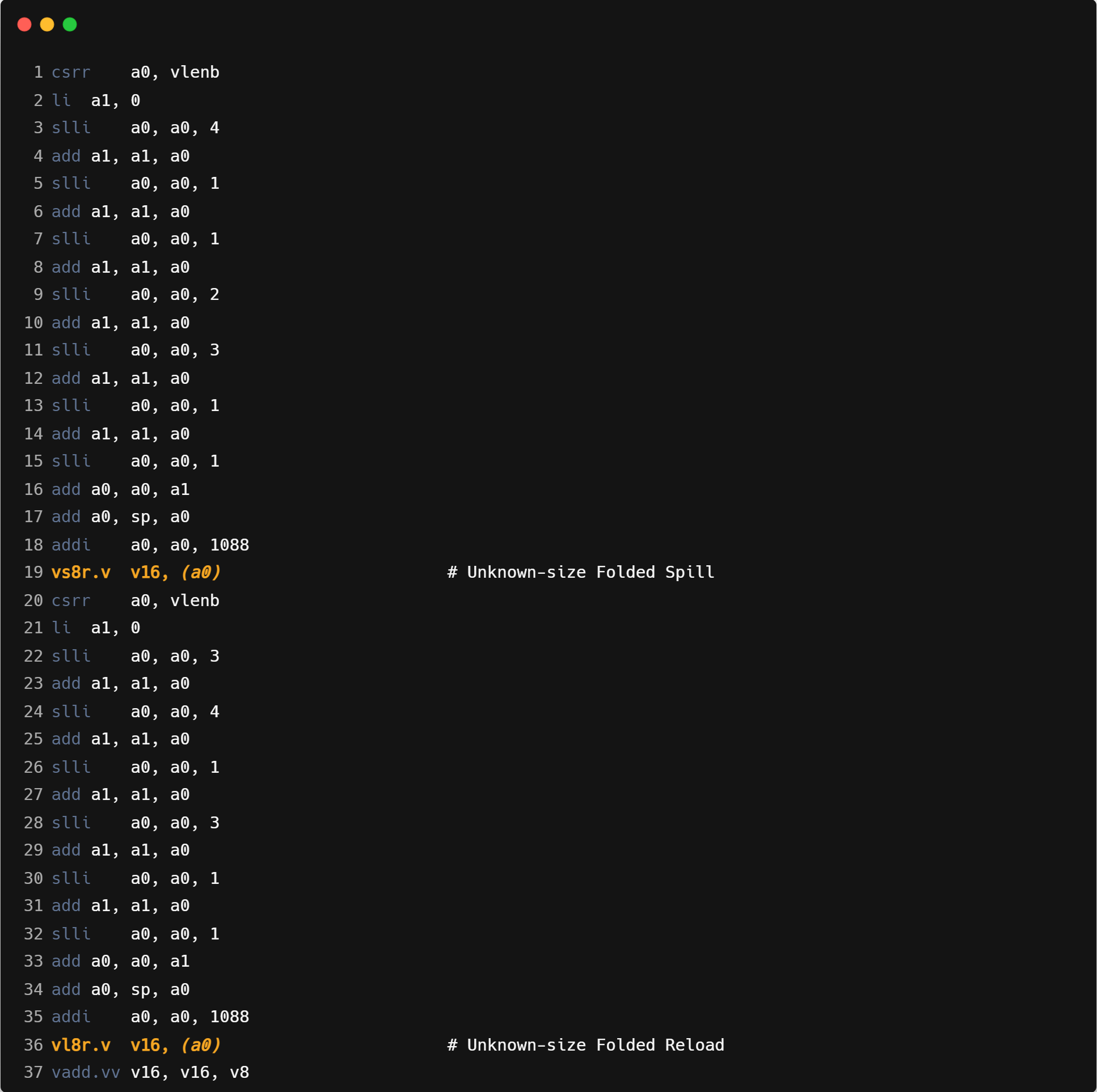
为了优化切块过大导致的寄存器溢出问题,可以考虑以下两种方案:
- 编译器优化处理:
- 进一步的 Tiling 操作:编译器在 IR Lowering 过程中,进一步细化数据的切分块大小,以适应 CPU 寄存器的容量。
- Loop Fusion(循环融合):每一步的大块张量运算作进一步的切块时会生成许多相同维度的循环,将这些循环合并到一个循环中,可以减少每一步运算的中间结果的数据读入和写出操作。
- 程序员手动优化:在编写算子库时,程序员根据底层 CPU 硬件的特性,手动将数据切分成更适合寄存器容量的大小。这种方法虽然需要额外的手工调优,但能够在时间和效率有限的情况下,快速找到较优的分块策略。
鉴于时间和效率的考量,这里选择了第二种方案。通过修改 Triton 中的autotuning工具,手动调优出最优的分块大小。可以看到,通过调优后的最优的 block 的数据量大小,通常是处理数据量和寄存器 spill 的一种 trade-off 的结果。
定长向量
Triton 采用显式切分的数据并行编程模型,使每个线程负责处理特定的数据块。然而,这种设计在输入数据量无法被切分大小整除时,程序员需要显式地使用带掩码(如带 mask 的 load)的操作来处理超出部分的数据。
此外,当前上游的多级中间表示(MLIR,Multi-Level Intermediate Representation)中的向量方言(Vector Dialect)采用的是定长向量表示。在 Triton-CPU 编译器将高层次的张量(tensor)操作降级(lower)到向量级别时,编译器依赖于这一固定长度的向量方言。这种设计虽然在一定程度上简化了编译流程,但在生成最终汇编代码时,与直接使用 RISC-V 向量指令集的 C 算子相比,存在以下几个显著的缺点:
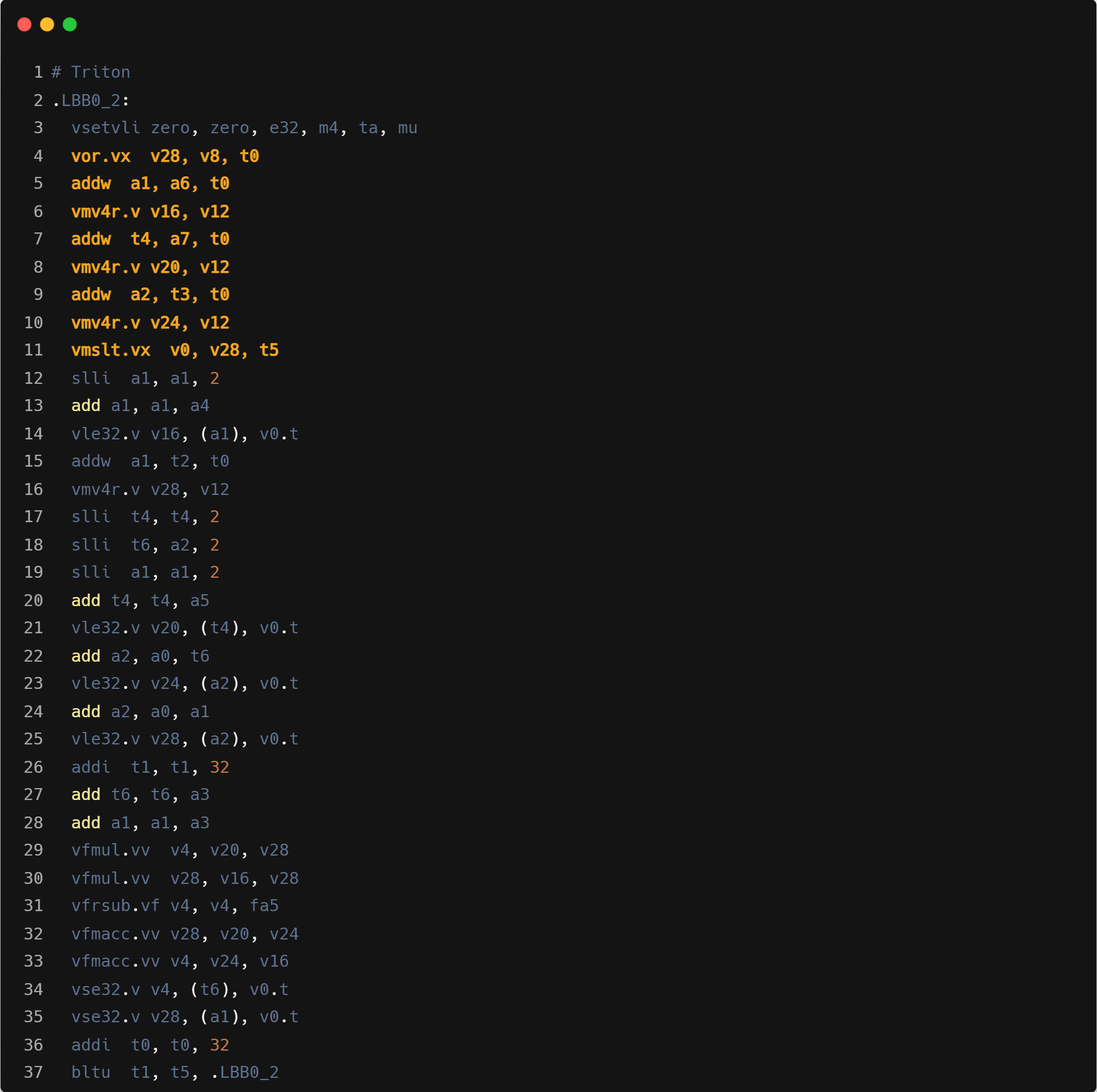
- mask 操作:程序中的显式的 mask 操作,在翻译到汇编时,会生成对应的掩码计算和设置指令。这会增加程序的指令数量从而影响程序的性能。相比之下,使用 RVV 指令集的 C 算子可以利用 RVV 提供的运行时向量长度设置功能。在处理尾循环时,RVV 可以动态调整向量操作的长度,以适应剩余的数据量,无需显式的掩码操作。如下是显式的 mask 操作编译生成的对应的掩码计算和设置指令。
10ff2: 57 70 20 05 vsetvli zero, zero, e32, m4, ta, mu
10ff6: 57 ca 8e 2a vor.vx v20, v8, t4
10ffa: 13 9e 2e 00 slli t3, t4, 0x2
10ffe: 57 b8 c1 9e vmv4r.v v16, v12
11002: 57 bc c1 9e vmv4r.v v24, v12
11006: 57 c0 42 6f vmslt.vx v0, v20, t0
- 寄存器分组大小的限制:在 Triton 中,显式设置的块大小会影响编译器在选择寄存器分组时的决策。编译器倾向于选择尽可能接近用户指定块大小的最大寄存器分组,这样的选择容易导致寄存器溢出(Register Spill)。而 C 算子使用的 RVV 指令,能够更灵活地管理寄存器资源,减少寄存器溢出的可能性,从而保持较高的执行效率。
后续的优化方案需扩展现有的向量方言,以支持 RVV 的特性。
离散访存的向量化
Triton-CPU 在将张量的 load 操作转换为向量 load 操作时,对非连续下标的内存访问支持尚不完善。Triton-CPU 在转换 load 操作的过程中会进行详细的指针分析,收集和解析内存访问的各种信息,包括张量的基地址、偏移量、步长(stride)等。这些信息被封装到一个名为AxisInfo的结构体中,用于后续的决策过程。
在生成AxisInfo之后,Triton-CPU 会根据张量形状(shape)最后一维是否具有连续性来决定采用何种 load 方式:
- 连续访问:如果张量的最后一维是连续的,意味着数据在内存中是按顺序排列的,此时 Triton-CPU 会选择使用 vector 方言的 load 操作。这种向量化的加载方式能够充分利用 CPU 的向量处理能力,提高数据加载的效率和性能。
- 非连续访问:当张量的最后一维在内存中不连续存储,即数据存在跳跃或间隔时,Triton-CPU 无法直接采用向量化的加载方式。此时,Triton-CPU 会执行以下步骤:
- 分配临时存储地址:为非连续的数据分配一个临时的存储位置。
- 标量加载数据:使用标量方式将数据加载到临时地址。会先读入到标量寄存器,再写回到指定的地址。
- 掩码检测(如果使用带 mask 的 load):在加载过程中进行掩码检测,以确保数据的正确性。
- 向量加载到寄存器:将临时地址上的数据通过向量化的方式加载到向量寄存器中。
这种处理方式会生成大量额外的指令,导致性能显著低于直接的向量化访问方式。下图展示了 warp 算子的带 mask 的 load 操作在 MLIR 中的表示。
%alloca = memref.alloca() {alignment = 64 : i64} : memref<1x64xi8> loc(#loc32)
%alloca_4 = memref.alloca() {alignment = 64 : i64} : memref<1x64xi64> loc(#loc31)
vector.transfer_write %43, %alloca_4[%c0, %c0] {in_bounds = [true, true]} : vector<1x64xi64>, memref<1x64xi64> loc(#loc31)
%44 = arith.extui %14 : vector<1x64xi1> to vector<1x64xi8> loc(#loc32)
%alloca_5 = memref.alloca() {alignment = 64 : i64} : memref<1x64xi8> loc(#loc12)
vector.transfer_write %44, %alloca_5[%c0, %c0] {in_bounds = [true, true]} : vector<1x64xi8>, memref<1x64xi8> loc(#loc12)
scf.for %arg6 = %c0 to %c64 step %c1 {
%70 = memref.load %alloca_4[%c0, %arg6] : memref<1x64xi64> loc(#loc31)
%71 = tt.int_to_ptr %70 : i64 -> !tt.ptr<i8> loc(#loc31)
%72 = memref.load %alloca_5[%c0, %arg6] : memref<1x64xi8> loc(#loc12)
%73 = arith.trunci %72 : i8 to i1 loc(#loc12)
scf.if %73 {
%74 = tt.load %71 : !tt.ptr<i8> loc(#loc32)
memref.store %74, %alloca[%c0, %arg6] : memref<1x64xi8> loc(#loc32)
} else {
memref.store %c0_i8, %alloca[%c0, %arg6] : memref<1x64xi8> loc(#loc32)
} loc(#loc32)
} loc(#loc32)
%45 = vector.transfer_read %alloca[%c0, %c0], %c0_i8 {in_bounds = [true, true]} : memref<1x64xi8>, vector<1x64xi8> loc(#loc32)
相比之下,在 C 语言算子的编译过程中,编译器能够利用 RISC-V 向量扩展(RVV)的 index load 指令。这种指令允许在内存访问时指定索引,从而支持更加灵活和高效的非连续内存访问模式。通过使用 RVV 的 index load,C 算子在处理非连续下标访问时,可以省略 Triton 在此类操作中生成的众多额外指令,显著提升性能,远超 Triton-CPU。
这里我们通过将 Triton 的离散内存访问时的 load 操作,lowering 到 vector 的 gather 操作,最后实现了 index load 的翻译,减少了原来标量 load 操作时额外指令的生成,提升了算子的性能。
多线程的上下文问题
Triton-CPU 最终的算子调用过程是通过生成对应的 C 语言函数,然后编译成动态库的方式支持的。为了利用多核 CPU 的并行计算能力,Triton-CPU 采用了两层函数调用结构:
- 外层函数:负责多线程管理。通过在最外层循环中添加多线程的
pragma指令,实现并行任务的调度和执行。 - 内层函数:具体实现算子的计算逻辑。每个线程调用对应的算子函数,执行实际的计算任务。
如下是 Triton-CPU 生成的 Layernorm forward 算子的 C 语言函数调用 wrapper
void _layer_norm_fwd_fused_omp(uint32_t gridX, uint32_t gridY, uint32_t gridZ, _layer_norm_fwd_fused_kernel_ptr_t kernel_ptr , void* arg0, void* arg1, void* arg2, void* arg3, void* arg4, void* arg5, int32_t arg6, int32_t arg7, float arg8) {
// TODO: Consider using omp collapse(3) clause for simplicity?
auto all_grids = get_all_grids(gridX, gridY, gridZ);
size_t N = gridX * gridY * gridZ;
std::optional<int> max_threads = getIntEnv("Triton_CPU_MAX_THREADS");
if (max_threads.has_value())
max_threads = std::max(1, std::min(max_threads.value(), omp_get_max_threads()));
else
max_threads = omp_get_max_threads();
if (getBoolEnv("Triton_CPU_OMP_DEBUG"))
printf("N: %zu, max_threads: %d\n", N, max_threads.value());
// For now, use the default chunk size, total iterations / max_threads.
#pragma omp parallel for schedule(static) num_threads(max_threads.value())
for (size_t i = 0; i < N; ++i) {
const auto [x, y, z] = all_grids[i];
// Kernel call
(*kernel_ptr)(arg0, arg1, arg2, arg3, arg4, arg5, arg6, arg7, arg8, x, y, z, gridX, gridY, gridZ);
}
}
在 Triton-CPU 的单程序多数据(SPMD)编程模型下,每个算子需要识别其所属的切块(block)位置,以便准确计算切块数据的偏移量。这一机制类似于 GPU 中的块坐标。为了实现这一点,每次算子调用时必须传递当前切块的坐标值。因此,算子的实际参数量比传统 C 语言算子更多。
同时在算子调用过程时,prologue(前置代码)和 epilogue(后置代码)负责保存和恢复调用者的上下文状态,包括寄存器的保存、栈帧的建立与销毁等操作。由于 Triton 编译器需要为每一个切块单独调用一次算子,这意味着 prologue 和 epilogue 操作会按照切块数量的倍数执行。相比之下,传统的 C 语言算子通常在单一函数调用中完成算子的执行,prologue 和 epilogue 的执行次数较少。因此,Triton 编译生成的汇编代码中,由于频繁的函数调用,prologue 和 epilogue 的累计执行次数显著多于 C 语言算子的实现方式。
其它
指令融合:Triton-CPU 在处理某些简单的乘法和加法指令时,并未自动将它们融合为单一的复合指令。这种情况可能导致生成的汇编代码包含多个独立的乘法和加法指令,从而增加指令数量,影响执行效率。为了实现指令融合,开发者需要在代码中显式地使用 Triton 提供的 FMA 操作。通过这样做,可以确保编译器生成的汇编代码利用 FMA 指令,从而实现乘加操作的指令融合。
总结与展望
尽管 Triton-CPU 在 RISC-V 平台上面临诸如寄存器溢出、定长向量处理、离散访存向量化以及多线程实现带来的上下文存储开销等性能问题,但通过一系列试验性的优化措施,测试结果表明 Triton-CPU 在 RISC-V 架构上的性能可以接近传统 C 算子编译器的水平。这一结果不仅验证了 Triton 在高性能计算领域的巨大潜力,也彰显了其在开源 RISC-V 架构的广泛应用前景。
展望未来,随着优化工作的持续深入,Triton 有望进一步克服当前的性能瓶颈,提升计算效率和资源利用率,进而成为 RISC-V 平台上首选的算子库解决方案。同时,随着 RISC-V 架构在工业界的持续普及和应用场景的不断拓展,Triton 算子库凭借其高度的易用性和可维护性,以及依托于 MLIR(多级中间表示)编译器技术栈所带来的可兼容性和可扩展性,将显著增强其在市场中的竞争力。
此外,RISC-V、Triton 与 MLIR 等相关生态系统的协同发展,将促进开源技术的共同繁荣,进一步推动高性能计算与开源硬件架构的深度融合。通过这种协同效应,不仅能够加速技术创新,还能形成良性的生态循环,为未来的计算需求提供更为强大的支持。