引言
本文将从编译器的视角探讨SystemVerilog的多个重要方面,旨在揭示该语言特性的复杂性以及在编译器中的实现方式。首先,我们将分析SystemVerilog中端口声明的多种风格,探讨该语言中类型存在的问题,以及在设计中常见的复位信号与使能信号的区分难题。此外,还将讨论多值态问题对设计的影响。接着,文章将回顾SystemVerilog在CIRCT项目中的发展历程,为读者提供历史背景和相关知识。随后,我们将探讨SystemVerilog在CIRCT项目中的转换过程及其特性支持的最新进展。最后,文章将通过具体实例详细介绍在转换过程中所涉及的优化Pass、策略及工具的应用。并以Johnson计数器为例,展示如何使用Arcilator工具进行仿真,帮助读者更好地理解SystemVerilog在CIRCT项目中的实际应用。
编译器视角下的SystemVerilog
SystemVerilog作为一种现代硬件描述语言,提供了丰富的语法特性和灵活的编程风格,其中包含大量的语法糖以及奇特的书写方式。例如:
- 模块端口声明可以通过多种方式实现,如ANSI风格、Non-ANSI风格以及MultiPorts风格。ANSI风格和Non-ANSI风格的端口设计在编译器处理时相对清晰,易于理解和维护。然而,MultiPorts风格中的书写方式,如 .b({v0, v1, v2}),虽然为设计者提供了便利,但却可能给代码的可读性和编译器的处理带来一定挑战。Moore方言中的module、ports以及instance的设计十分复杂。我们以ANSI风格为例,首先是Slang在将其转换为AST时,如下所示:对于input a端口,在生成AST时变被分为用于模块之间进行通信连接的Port(对应 “kind”: “Port” 字段),以及用于module内部使用的 Net(对应 “kind”: “Net” 字段)。其次为了能够处理不同风格的端口列表,以及方便Moore向下层lower,故在生成Moore IR时,会同时表示 Port和 Net。更为详细的设计细节请查看相应的PR: [Moore] Add module and instance port support #7112。
SV 源码 :
// ANSI风格, 端口方向和端口名都声明在端口列表中
module PortsAnsi(
input a,
output b,
inout c
);
endmodule
// Non-ANSI风格, 端口名声明在端口列表中,端口方向在module中
module PortsNonAnsi(a, b, c);
input a;
output b;
inout c;
endmodule
// MultiPorts风格,input端口和output端口混杂,可读性差,编译器进行分析时也相对困难
module MultiPorts(
.a0(u[0]),
.a1(u[1]),
.b({v0, v1, v2}),
{c0, c1}
);
input [1:0] u;
input v0;
output v1;
inout v2;
input c0;
output c1;
endmodule
AST:
{
"name": "$root",
"kind": "Root",
"addr": 2199024449984,
"members": [
{
"name": "",
"kind": "CompilationUnit",
"addr": 2199025895968
},
{
"name": "PortsAnsi",
"kind": "Instance",
"addr": 2199025897768,
"body": {
"name": "PortsAnsi",
"kind": "InstanceBody",
"addr": 2199025897488,
"members": [
{
"name": "a",
"kind": "Port",
"addr": 2199025897904,
"type": "logic",
"direction": "In",
"internalSymbol": "2199025898080 a"
},
{
"name": "a",
"kind": "Net",
"addr": 2199025898080,
"type": "logic",
"netType": {
"name": "wire",
"kind": "NetType",
"addr": 2199024447296,
"type": "logic"
}
},
{
"name": "b",
"kind": "Port",
"addr": 2199025898480,
"type": "logic",
"direction": "Out",
"internalSymbol": "2199025898656 b"
},
{
"name": "b",
"kind": "Net",
"addr": 2199025898656,
"type": "logic",
"netType": {
"name": "wire",
"kind": "NetType",
"addr": 2199024447296,
"type": "logic"
}
},
{
"name": "c",
"kind": "Port",
"addr": 2199025899056,
"type": "logic",
"direction": "InOut",
"internalSymbol": "2199025899232 c"
},
{
"name": "c",
"kind": "Net",
"addr": 2199025899232,
"type": "logic",
"netType": {
"name": "wire",
"kind": "NetType",
"addr": 2199024447296,
"type": "logic"
}
}
],
"definition": "PortsAnsi"
},
"connections": [
]
}
]
}
Moore IR:
module {
// 对应 ANSI风格
moore.module @PortsAnsi(in %a : !moore.l1, out b : !moore.l1, in %c : !moore.ref<l1>) {
%a_0 = moore.net name "a" wire : <l1>
%b = moore.net wire : <l1>
%c_1 = moore.net name "c" wire : <l1>
moore.assign %a_0, %a : l1
%0 = moore.read %b : <l1>
%1 = moore.read %c : <l1>
moore.assign %c_1, %1 : l1
moore.output %0 : !moore.l1
}
// 对应 Non-ANSI风格
moore.module @PortsNonAnsi(in %a : !moore.l1, out b : !moore.l1, in %c : !moore.ref<l1>) {
%a_0 = moore.net name "a" wire : <l1>
%b = moore.net wire : <l1>
%c_1 = moore.net name "c" wire : <l1>
moore.assign %a_0, %a : l1
%0 = moore.read %b : <l1>
%1 = moore.read %c : <l1>
moore.assign %c_1, %1 : l1
moore.output %0 : !moore.l1
}
// 对应 MultiPorts风格
moore.module @MultiPorts(in %a0 : !moore.l1, in %a1 : !moore.l1, in %v0 : !moore.l1, out v1 : !moore.l1, in %v2 : !moore.ref<l1>, in %c0 : !moore.l1, out c1 : !moore.l1) {
%u = moore.net wire : <l2>
%v0_0 = moore.net name "v0" wire : <l1>
%v1 = moore.net wire : <l1>
%v2_1 = moore.net name "v2" wire : <l1>
%c0_2 = moore.net name "c0" wire : <l1>
%c1 = moore.net wire : <l1>
%0 = moore.extract_ref %u from 0 : <l2> -> <l1>
moore.assign %0, %a0 : l1
%1 = moore.extract_ref %u from 1 : <l2> -> <l1>
moore.assign %1, %a1 : l1
moore.assign %v0_0, %v0 : l1
%2 = moore.read %v1 : <l1>
%3 = moore.read %v2 : <l1>
moore.assign %v2_1, %3 : l1
moore.assign %c0_2, %c0 : l1
%4 = moore.read %c1 : <l1>
moore.output %2, %4 : !moore.l1, !moore.l1
}
}
- 在变量声明中,类型的多样性表现得尤为明显,包括int、bit、logic、reg以及long int等。然而,在实际应用中,bit和logic可以混用,reg和logic类型也是等效的,reg并不专门用于表示寄存器。这不仅会导致初学者对其用途产生误解,也导致如在Moore方言中进行类型系统设计时的复杂性(Moore方言早期的类型系统设计明确区分了int、bit、logic、reg等类型,后因其复杂性而重构了Moore方言的类型系统);
module Foo(input clk);
logic q = 1'b0;
always@(posedge clk) begin
q <= q + 1'b1; // 尽管 q的类型是logic,但 q依然表示寄存器
end
endmodule
- 专属类型的缺失。尽管设计者明确知道时序逻辑中的复位信号和使能信号。但由于该语言的类型可以混用,而这些信号又没有专属类型进行标明,故而编译器在处理过程中无法很好的区分它们。如下列时序逻辑 a和b,复位信号(rst)和使能信号(en)在IR中无法进行区别;也正因此,目前时序逻辑的转换路线从原本的Moore —> Seq变成了 Moore —> LLHD。二者区别如下:
SV 源码 :
module Foo(input clk, rst, en,
output reg q);
// 时序逻辑 a
always @(posedge clk) begin
if(rst)
q <= 1'b0;
end
// 时序逻辑 b
always @(posedge clk) begin
if(en)
q <= 1'b0;
end
endmodule
Seq IR:
module {
hw.module @Foo(in %clk : i1, in %rst : i1, in %en : i1, out q : i1) {
// 此处省略 ……
// 对应时序逻辑 a
// %next 表示下一次的值,即仅当始终信号触发时,将要存入寄存器的值,这里暂时用伪代码表示
// %clk 表示时钟信号
// async 表示这是异步时序逻辑
// %rst 表示复位信号
// %rstValue 表示复位值
%q = seq.firreg %next clock %clk reset async %rst, %rstValue: i1
// 对应时序逻辑 b
// %next 表示下一次的值,即仅当始终信号触发时,将要存入寄存器的值,这里暂时用伪代码表示
// %clk 表示时钟信号
// async 表示这是异步时序逻辑
// %en 表示复位信号
// %enValue 表示复位值
%q = seq.firreg %next clock %clk reset async %en, %enValue: i1
}
}
LLHD IR:
module {
hw.module @Foo(in %clk : i1, in %rst : i1, in %en : i1, out q : i1) {
// 此处省略 ……
// 对应时序逻辑 a
llhd.process {
cf.br ^bb1
^bb1: // 4 preds: ^bb0, ^bb2, ^bb3, ^bb4
%4 = llhd.prb %clk_0 : !hw.inout<i1>
llhd.wait (%2 : i1), ^bb2
^bb2: // pred: ^bb1
%5 = llhd.prb %clk_0 : !hw.inout<i1>
%6 = comb.xor bin %4, %true : i1
%7 = comb.and bin %6, %5 : i1
cf.cond_br %7, ^bb3, ^bb1
^bb3: // pred: ^bb2
%8 = llhd.prb %rst_1 : !hw.inout<i1>
cf.cond_br %8, ^bb4, ^bb1
^bb4: // pred: ^bb3
llhd.drv %q, %false after %1 : !hw.inout<i1>
cf.br ^bb1
}
// 对应时序逻辑 b
llhd.process {
cf.br ^bb1
^bb1: // 4 preds: ^bb0, ^bb2, ^bb3, ^bb4
%4 = llhd.prb %clk_0 : !hw.inout<i1>
llhd.wait (%2 : i1), ^bb2
^bb2: // pred: ^bb1
%5 = llhd.prb %clk_0 : !hw.inout<i1>
%6 = comb.xor bin %4, %true : i1
%7 = comb.and bin %6, %5 : i1
cf.cond_br %7, ^bb3, ^bb1
^bb3: // pred: ^bb2
%8 = llhd.prb %en_2 : !hw.inout<i1>
cf.cond_br %8, ^bb4, ^bb1
^bb4: // pred: ^bb3
llhd.drv %q, %false after %1 : !hw.inout<i1>
cf.br ^bb1
}
// 此处省略 ……
}
}
- 多值态问题。该语言支持2值态、4值态甚至9值态,并且IEEE标准明确规定bit为2值态,而logic则为4值态。然而,在仿真过程中,4值态中的x值态往往会被仿真器的设计者或用户手动更改为0或1。在真实电路中,更是不存在x值态的情况。但这种语法特性却需要编译器支持,为此在MLIR基础设施中增加了对4值态的表示。
SV 源码 :
module Foo;
bit b;
logic [3:0] l;
endmodule
Moor IR:
module {
moore.module @Foo() {
%b = moore.variable : <i1> // 用 i表示2值态,1表示位宽
%l = moore.variable : <l4> // 用 l表示4值态, 4表示位宽
moore.output
}
}
虽然这些灵活的设计风格使设计者便于进行硬件建模或提升代码的可读性,但也增加了编译器在前端处理时的复杂性。在编译器的词法分析和语法分析阶段,这些复杂的特性和语法糖会被解析并保留。然而,随着编译过程的深入,特别是在中间代码生成阶段,许多语法糖会被消除,只保留最基本的结构。这意味着,尽管设计者在编写代码时享受了更高层次的抽象和便利,但最终生成的中间代码却是相对简单且高效的。这种现象引发了对SystemVerilog特性的深入探讨,尤其是如何在保持设计灵活性的同时优化编译过程。
SV在CIRCT项目中的发展历程
在CIRCT - 基于MLIR的电路编译器和工具链一文中,我们介绍了CIRCT的发展历程。其中提到在2021年1月CIRCT项目发展初期,当时的项目结构如图1所示。在这一阶段,CIRCT的SystemVerilog前端编译器是Moore,该编译器与LLHD项目一同诞生,并非独立开发。此时,基于周期的仿真器circilator(现称为Arcilator)尚未实现,而是使用基于事件驱动的仿真器llhd-sim进行仿真。
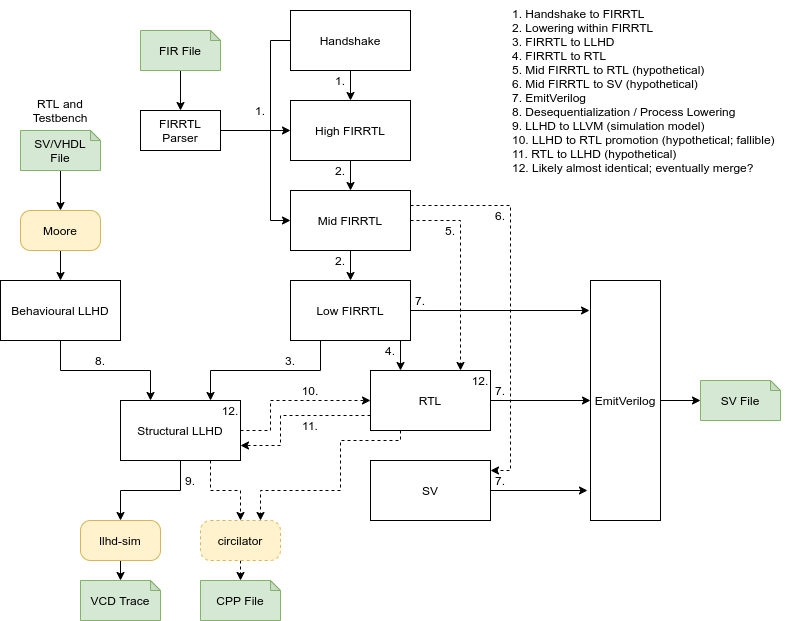
在2022年10月5日的CIRCT例会上,Mike Popolski分享了将 Slang 作为CIRCT项目中的SystemVerilog前端编译器的计划,并开始尝试将 Slang v1.0 接入到CIRCT。
在2023年3月,Slang发布了v3.0版本,但该版本的接入工作一直持续到同年7月仍未成功。直到兆松科技开始投入人力加入CIRCT社区,最终在同年10月成功将Slang v3.0版本接入CIRCT。
在2024年3月6日的CIRCT例会上,兆松科技的开发人员分享了主题为“Bridging SystemVerilog to CIRCT Eco”的演讲,主要介绍了SystemVerilog特性支持的进度。至此,随着开发工作的推进,SystemVerilog技术路线的开发从Fabian的个人仓库转移至LLVM/CIRCT主线,并且Slang正式替代了Moore编译器的位置。 为了更好地适应发展需要,考虑到SystemVerilog类型系统的复杂性,会议上还决定重新设计Moore语言的类型系统。
在2024年9月18日的CIRCT例会上,Fabian分享了circt-verilog工具。该工具由兆松科技人员与CIRCT上游开发者协同完成。在测试蜂鸟E203和Snitch这两款RISC-V CPU时,由于遇到了一些因语言本身带来的挑战,于是决定将时序逻辑的转换从Seq调整到LLHD。然而,这并不意味着放弃Seq方言,后续兆松科技仍将继续投入人力,将部分易于分析的时序逻辑转换调整回Seq。
纵观SystemVerilog在CIRCT项目中的发展历程,其重要性不言而喻。随着对 SystemVerilog 特性的支持不断完善,这使得CIRCT 项目能为未来的硬件设计提供强有力的支持。
SV路线图
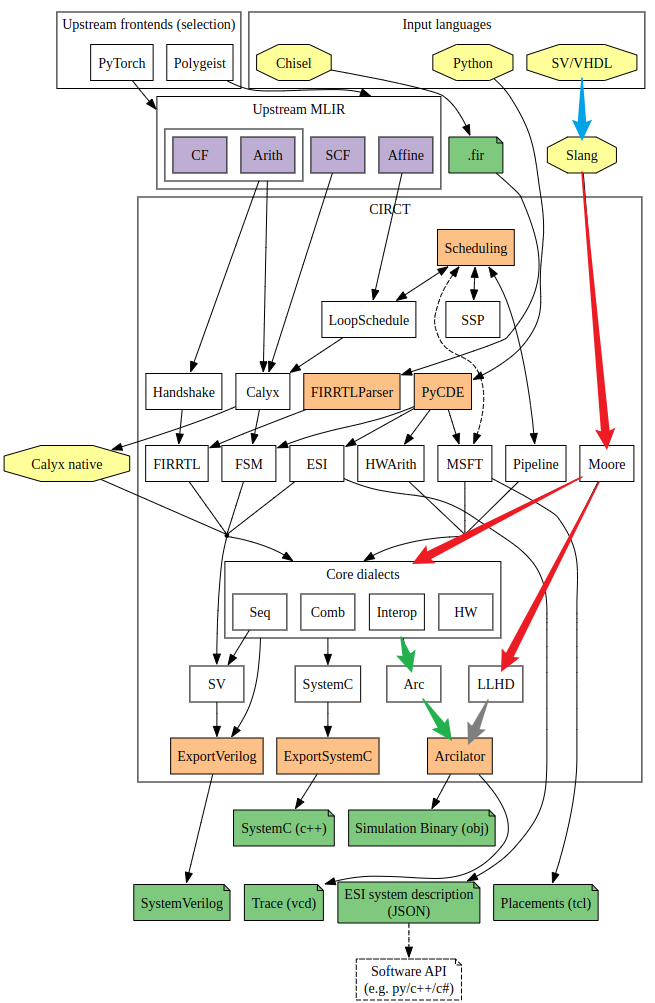
SystemVerilog在CIRCT项目中的技术路线如下图所示。
注:蓝色箭头表示此路线由Slang作者等人开发实现;
红色箭头表示由兆松科技和CIRCT上游部分开发人员共同完成;
绿色箭头表示此路线已由SiFive公司开发人员实现;
灰色箭头表示此路线目前暂未完善,还无法正常工作。
Slang:Slang并非CIRCT项目中的方言,而是一个软件库,提供了对SystemVerilog源码进行词法分析、语法分析及类型检查等功能。其设计灵感来源于C++前端编译器–Clang。由于Slang是一个软件库,因此在CIRCT项目中以动态库的形式被引入,且能将SystemVerilog源码转换成Json格式的AST。该工具以覆盖SystemVerilog IEEE 1800-2017中的所有特性为目标,目前该工具已推出v7.0版本。Slang对SystemVerilog特性的支持进展可查看其官方网站:特性支持进度;
Moore方言:该方言是Slang生成的AST的目标方言,即Slang AST --(ImportVerilog Pass)–> Moore IR。目前该方言致力于映射SystemVerilog IEEE Std 1800-2017中的所有特性。众所周知,SystemVerilog包含多种类型以及值态特性,为了消除此语法糖和区分二值态与四值态,Moore方言采用 !moore.i1和 !moore.l4分别表示二值态和四值态的基础类型,其中1和4表示位宽。
Core方言:这里的Core方言指的是Seq、Comb和HW方言;
-
Seq:用于表示带复位信号和使能信号的寄存器逻辑。例如
seq.comreg.ce用于描述具有使能信号和复位信号的同步时序逻辑,而seq.firreg则表示带有复位信号的同步或异步时序逻辑。 -
HW:专用于表示硬件设计中的公共特性。该方言定义的Operations不涉及组合逻辑、时序逻辑和线网之间的连接逻辑,因此具有高度的通用性,并能够与其他方言灵活结合使用。这使得HW方言不依赖于特定的硬件语言。例如,它可以有效地表示硬件中的module、instance和port;
-
Comb:与HW方言类似,提供一种不依赖于特定硬件语言的通用表示方式。专注于表示硬件电路中的组合电路,其设计理念强调简洁性,力求用更少的Operations表达更多的功能。例如,通过将x与全1进行异或运算,可以有效地表示一元位运算符(~x)。
LLHD方言:目前仅用于SV技术路线,专门表示那些无法从Moore方言lower到Core方言的与时序逻辑相关的Operations。例如,时延控制、无法区分复位信号和使能信号的时序逻辑。但由于语言本身的问题,如不能像Chisel那样区分使能信号与复位信号,因此目前该方言承担所有的时序逻辑转换。
SV特性支持进度
随着Terapines和上游部分开发者的共同努力,从2023年7月至今,SV特性在CIRCT项目中的支持如下图所示:
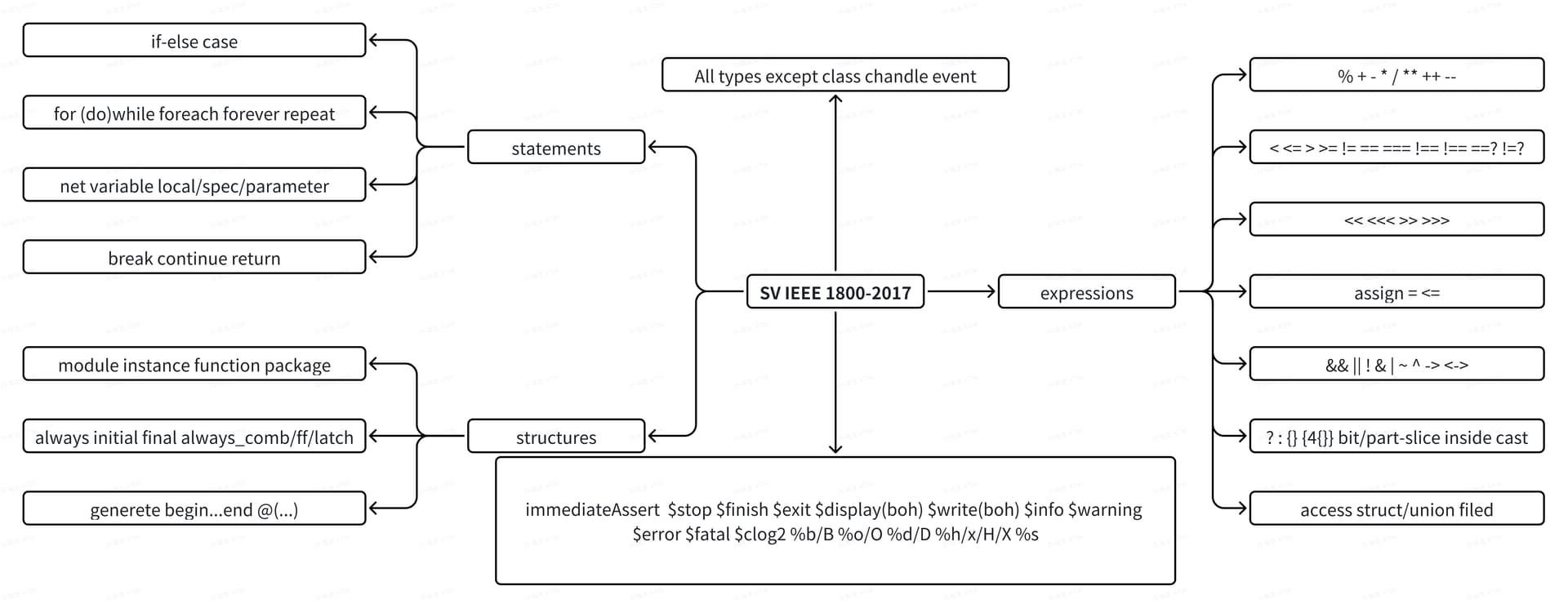
SV细节举例
用于SV转换路线的工具
贯穿SystemVerilog向下转换的三个重要的工具:circt-verilog、circt-translate和circt-opt。它们各自承担着不同的功能,为CIRCT项目的优化和转换提供了强有力的支持。
-
circt-verilog:将上述优化Pass/Strategy整合到多个选项中,例如,使用
--ir-moore选项时,可以直接输出Moore IR,并且生成的IR会执行如Mem2Reg等Pass;而通过--ir-hw选项,用户能够直接获得Core IR + LLHD IR的输出。这种灵活性使得设计者能够根据具体需求选择合适的输出格式; -
circt-translate:专注于简化Verilog导入过程,提供了一个核心选项
--import-verilog。这个选项使得用户能够方便地将Verilog代码导入到CIRCT环境中,为后续的处理和优化奠定基础; -
circt-opt:该工具包含了所有MLIR中通用的Pass以及一些自定义的优化Pass,例如
--canonicalize、--moore-lower-concatref、--moore-simplify-procedures、--mem2reg和--sroa等。这些功能强大的优化工具能够帮助用户提高设计效率,确保生成的电路在性能和资源利用率方面达到最佳状态。
Moore方言中的优化Pass/Strategy
在Moore方言中,为了减少生成的代码量和对内存的操作以及保证向下lower的正确性与可行性等。减少生成的代码量是指消除因实例化而产生的重复的模块;减少对内存的操作是指通过完善Canonicalize方法将对内存进行操作(拥有Side-effect特征)的Operations合并为单个Operation,例如将moore.variable 和moore.assign转变为moore.assigned_variable(此Operation消除了Side-effect这个特征);保证向下lower的正确性与可行性是指部分Moore IR可能无法直接映射到更底层(Core方言层),故而在Moore层利用Pass技术进行优化,然后再lower到下层。具体优化Pass/Strategy如下:
-
SimplifyProcedure:用于保证SV中阻塞赋值的正确性。其设计原理是因SV拥有always_comb begin … end这一特性,在begin … end区域中允许对同一个变量进行多次赋值,参考下述例子。我们将此称之为阻塞赋值,其行为如软件中的赋值,但是在实际硬件电路中不存在阻塞行为,并且在lower到Core方言层时,需要将always_comb中的逻辑提取出来,这让阻塞赋值看起来就像连续赋值(在SV中用assign关键字表示的赋值行为)。而为了保证变量a和x(参考下述例子)的正确性,因此设计此Pass。 -
Mem2Reg:此Pass是LLVM及MLIR中的基础Pass,但需要实现相应接口才能使用。在Moore方言中用于消除局部变量。参考下述例子,假设我们将int a;插入到always_comb内部进行声明。上面提到我们在将Moore方言lower到Core方言时,需要提取出always_comb中的逻辑,但由于此时的变量a是局部变量,为了避免将局部变量提取出而变成module层面的全局变量,因此使用此Pass。
以下是一个简单的SystemVerilog示例,详细展示了在执行SimplifyProcedure和Mem2Reg Pass之后的Moore IR。 尽管在执行SimplifyProcedure Pass之后生成的Moore IR变得更长,增加了一些对内存进行操作的Operations,但该 Pass 能够有效地保证变量a和x的值在硬件综合中的正确性。与此同时,Mem2Reg Pass 则可以消除SimplifyProcedure Pass产生的局部变量。这两者的配合不仅确保了阻塞赋值在硬件逻辑上的正确性,还减少了对内存的操作。 SV 源码 :
module Foo;
int a, x;
always_comb begin
a = 1;
x = a;
a = a + 1;
end
endmodule
Moore IR(Import-Verilog Pass):
// RUN: circt-translate --import-verilog %s
module {
moore.module @Foo() {
// a, x的变量声明
%a = moore.variable : <i32>
%x = moore.variable : <i32>
moore.procedure always_comb {
// a = 1
%0 = moore.constant 1 : i32
moore.blocking_assign %a, %0 : i32
// x = a
%1 = moore.read %a : <i32> // 读取a的值
moore.blocking_assign %x, %1 : i32 // SV中的阻塞赋值
// a = a + 1
%2 = moore.read %a : <i32>
%3 = moore.constant 1 : i32
%4 = moore.add %2, %3 : i32
moore.blocking_assign %a, %4 : i32
moore.return
}
moore.output
}
}
Moore IR(Simplify-Procedure Pass):
// RUN: circt-opt --moore-simplify-procedures %s
module {
moore.module @Foo() {
%a = moore.variable : <i32>
%x = moore.variable : <i32>
moore.procedure always_comb {
%0 = moore.read %a : <i32>
%1 = moore.variable : <i32> // 声明local_a
moore.blocking_assign %1, %0 : i32 // local_a = a
%2 = moore.constant 1 : i32
moore.blocking_assign %1, %2 : i32 // local_a = 1
%3 = moore.read %1 : <i32> // 读取local_a(1)
moore.blocking_assign %a, %3 : i32 // a = local_a(1)
%4 = moore.read %1 : <i32> // 读取local_a(1)
moore.blocking_assign %x, %4 : i32 // x = local_a(1)
%5 = moore.read %1 : <i32> // 读取local_a(1)
%6 = moore.constant 1 : i32
%7 = moore.add %5, %6 : i32
moore.blocking_assign %1, %7 : i32 // local_a(2) = local_a(1) + 1
%8 = moore.read %1 : <i32> // 读取local_a(2)
moore.blocking_assign %a, %8 : i32 // a = local_a(2)
moore.return
}
moore.output
}
}
Moore IR(mem2reg pass):
// RUN circt-opt --mem2reg %s
module {
moore.module @Foo() {
// a, x变量声明
%a = moore.variable : <i32>
%x = moore.variable : <i32>
moore.procedure always_comb {
%0 = moore.read %a : <i32>
%1 = moore.constant 1 : i32
moore.blocking_assign %a, %1 : i32 // a = 1
moore.blocking_assign %x, %1 : i32 // x = 1
%2 = moore.constant 1 : i32
%3 = moore.add %1, %2 : i32
moore.blocking_assign %a, %3 : i32 // a = 2
moore.return
}
moore.output
}
}
在 SystemVerilog 中,由于支持结构体和数组等聚合类型,故在Moore层应用SROA Pass以提高程序的执行效率以及减少对内存的访问。示例如下:
SROA(Scalar Replacement of Aggregates):SROA 会分析聚合数据的使用方式,尝试将其拆分为单独的标量值
SV 源码 :
module SROA;
// x, y变量声明
int x;
logic y;
always_comb begin
// 结构体声明
struct packed {
int i;
logic l;
} ST;
// 给结构体成员变量赋值
ST.i = x;
ST.l = y;
end
endmodule
Moore IR(Import-Verilog Pass):
// RUN: circt-translate --import-verilog %s
module {
moore.module @SROA() {
// x, y变量声明
%x = moore.variable : <i32>
%y = moore.variable : <l1>
moore.procedure always_comb {
// 结构体声明
%ST = moore.variable : <struct<{i: i32, l: l1}>>
// 使用 moore.struct_extract_ref操作,获取结构体 ST中的字段 i
%0 = moore.struct_extract_ref %ST, "i" : <struct<{i: i32, l: l1}>> -> <i32>
%1 = moore.read %x : <i32>
moore.blocking_assign %0, %1 : i32
// 获取结构体 ST中的字段 l
%2 = moore.struct_extract_ref %ST, "l" : <struct<{i: i32, l: l1}>> -> <l1>
%3 = moore.read %y : <l1>
moore.blocking_assign %2, %3 : l1
moore.return
}
moore.output
}
}
Moore IR(SROA Pass):
// RUN: circt-opt --sroa %s
module {
moore.module @SROA() {
%x = moore.variable : <i32>
%y = moore.variable : <l1>
moore.procedure always_comb {
// 将结构体声明转变为对单个变量进行声明,并消除掉moore.struct_extract_ref
%ST.l = moore.variable : <l1>
%ST.i = moore.variable : <i32>
%0 = moore.read %x : <i32>
moore.blocking_assign %ST.i, %0 : i32
%1 = moore.read %y : <l1>
moore.blocking_assign %ST.l, %1 : l1
moore.return
}
moore.output
}
}
前文提到部分Moore IR无法直接lower到下层,moore.concat_ref就是一个很典型的例子,参考下述SV源码。由于变量u和v并非是结构体成员,故无法使用SROA Pass进行优化。为了减少此语句的复杂性以及保证其正确性,因此定义LowerConcatRef Pass将其拆分成一般的赋值语句。具体如下:
LowerConcatRef:拆分连接运算符,例如 from{u, v} = w;tou = w[9001:42]; v = w[41:0];
SV 源码 :
module LowerConcatRef;
logic [9001:42]u;
logic [41:0]v;
logic [9001:0]w;
assign {v, u} = w;
endmodule
Moore IR(ImportVerilog Pass):
// RUN: circt-translate --import-verilog %s
module {
moore.module @LowerConcatRef() {
%u = moore.variable : <l8960>
%v = moore.variable : <l42>
%w = moore.variable : <l9002>
// 连接运算符
%0 = moore.concat_ref %v, %u : (!moore.ref<l42>, !moore.ref<l8960>) -> <l9002>
%1 = moore.read %w : <l9002>
moore.assign %0, %1 : l9002
moore.output
}
}
Moore IR(LowerConcatRef Pass):
// RUN: circt-opt --moore-lower-concatref %s
module {
moore.module @LowerConcatRef() {
%u = moore.variable : <l8960>
%v = moore.variable : <l42>
%w = moore.variable : <l9002>
// 执行此Pass之后并未删除moore.concat_ref,但是可以在执行MooreToCore Pass时删除
%0 = moore.concat_ref %v, %u : (!moore.ref<l42>, !moore.ref<l8960>) -> <l9002>
%1 = moore.read %w : <l9002>
// 截取 w[9001:8960]
%2 = moore.extract %1 from 8960 : l9002 -> l42
moore.assign %v, %2 : l42
// 截取 w[8095:0]
%3 = moore.extract %1 from 0 : l9002 -> l8960
moore.assign %u, %3 : l8960
moore.output
}
}
在MLIR框架中,除了以定义Pass的方式实现方言层的优化外,还可以为单个Operation开启 let hasCanonicalizeMethod = true;字段,此时需要在MooreOps.cpp文件中实现 XXXOp::Canonicalize() 方法。实现后的优化效果如下,但在此不展开讨论函数实现细节:
-
Canonicalization:MLIR中的一种机制,用于对单个Operation进行优化操作。例如,- 当声明的变量或者线网仅被赋值一次时,将变量声明和赋值操作合并为moore.assigned_variable。此方法可以快速告知仿真器一个变量或者线网所拥有的值,而无需逐行执行语句以确定值。
%a = moore.variable : i32(int a;) --
%0 = moore.constant 1 : i32 | -- %a = moore.assigned_variable %0 : i32
moore.assign %a, %0 : i32(a = 0;) --
下述例子并非采用Pass技术实现,而是translation阶段(translation在此指的是从Slang生成的AST到转换为Moore IR这一阶段)的固有方法。此方法的优势在于,最初生成的Moore IR就已经消除了重复的实例化模块,可大幅度减少Code size。细节如下:
类似Deduplicate Pass:但此功能在Moore方言中并非单独的Pass,而是在生成Moore IR时,就已经消了除重复的实例化模块。例如在CIRCT 关键概念:方言(Dialect)一文中展示的全加器
SV 源码 :
module half_add(
input A, B, // 输入端口
output Sum, Cout // 和输出端口以及进位输出端口
);
// 计算和和进位
assign Sum = A ^ B; // 和
assign Cout = A & B; // 进位
endmodule
module full_add(
input A,B,Cin,
output Sum,Cout
);
wire w1,w2,w3;
// 实例化两个半加器
half_add add1(A, B, w1, w2);
half_add add2(.A(Cin), .B(w1), .Sum(Sum), .Cout(w3));
assign Cout = w2 | w3; // 计算最终进位
endmodule
Moore IR(删除了重复的实例化模块 haf_add):
// RUN: circt-verilog --ir-moore %s
module {
moore.module private @half_add(in %A : !moore.l1, in %B : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%0 = moore.xor %A, %B : l1
%1 = moore.and %A, %B : l1
moore.output %0, %1 : !moore.l1, !moore.l1 // %0 对应out Sum, %1 对应out Cout
}
moore.module @full_add(in %A : !moore.l1, in %B : !moore.l1, in %Cin : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%w1 = moore.assigned_variable %add1.Sum : l1 // 表示 w1 这根线与 %add1.Sum 相连
%w2 = moore.assigned_variable %add1.Cout : l1 // 表示 w2 这根线与 %add1.Cout 相连
%w3 = moore.assigned_variable %add2.Cout : l1 // 表示 w3 这根线与 %add2.Cout 相连
%add1.Sum, %add1.Cout = moore.instance "add1" @half_add(A: %A: !moore.l1, B: %B: !moore.l1) -> (Sum: !moore.l1, Cout: !moore.l1) // 表示将half_add中的Sum端口的值传给 %add1.Sum,Cout端口的值传给 %add1.Count
%add2.Sum, %add2.Cout = moore.instance "add2" @half_add(A: %Cin: !moore.l1, B: %w1: !moore.l1) -> (Sum: !moore.l1, Cout: !moore.l1) // 同上
%0 = moore.or %w2, %w3 : l1
moore.output %add2.Sum, %0 : !moore.l1, !moore.l1 // %add2.Sum 对应out Sum, %0 对应out Cout
}
}
Moore IR(屏蔽/注释此功能之后,生成了两份相同的half_add模块):
// RUN: circt-verilog --ir-moore %s
module {
moore.module private @half_add(in %A : !moore.l1, in %B : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%0 = moore.xor %A, %B : l1
%1 = moore.and %A, %B : l1
moore.output %0, %1 : !moore.l1, !moore.l1
}
moore.module private @half_add_0(in %A : !moore.l1, in %B : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%0 = moore.xor %A, %B : l1
%1 = moore.and %A, %B : l1
moore.output %0, %1 : !moore.l1, !moore.l1
}
moore.module @full_add(in %A : !moore.l1, in %B : !moore.l1, in %Cin : !moore.l1, out Sum : !moore.l1, out Cout : !moore.l1) {
%w1 = moore.assigned_variable %add1.Sum : l1
%w2 = moore.assigned_variable %add1.Cout : l1
%w3 = moore.assigned_variable %add2.Cout : l1
%add1.Sum, %add1.Cout = moore.instance "add1" @half_add(A: %A: !moore.l1, B: %B: !moore.l1) -> (Sum: !moore.l1, Cout: !moore.l1)
%add2.Sum, %add2.Cout = moore.instance "add2" @half_add_0(A: %Cin: !moore.l1, B: %w1: !moore.l1) -> (Sum: !moore.l1, Cout: !moore.l1)
%0 = moore.or %w2, %w3 : l1
moore.output %add2.Sum, %0 : !moore.l1, !moore.l1
}
}
除了上述需要额外新增Pass或者实现相应接口或函数对IR进行优化之外,还可以利用MLIR中更为通用的Pass。具体如下:
-
CSE(Common Subexpression Eliminate):将多条相同的IR合并为一条IR; -
DCE(Dead Code Eliminate):删除代码中不会被用到的IR; -
Constant Fold:在编译时,将常量表达式直接替换为其结果。
Johnson计数器仿真举例
SV 源码 :
module JS_Counter(
input clk, rst_n, // 时钟信号和复位信号
output reg [3:0] q // 输出计数值
);
always @(posedge clk or negedge rst_n) begin // 异步时序逻辑,下降沿时触发复位信号
if (!rst_n) begin
q <= 4'b0000; // 触发复位信号置为0
end else begin
q <= {~q[0],q[3:1]}; // 将最后一位取反并移位
end
end
endmodule
Core IR:
hw.module @JSCounter(in %clk : i1, in %rst_n : i1, out q : i4) {
%c0_i4 = hw.constant 0 : i4 // 4-bits的0值,用于表示复位值
%true = hw.constant true // 用于计算 !rst_n
%0 = seq.to_clock %clk // 将 clk的类型 i1转换为 !seq.clock
// 由于LLHD IR目前并不能被Arcilator处理,故而在此使用Seq方言表示时序逻辑
// %5 表示下一次的值,即 q <= {~q[0],q[3:1]};
// %0 表示时钟信号
// async 表示这是异步时序逻辑
// %1 表示复位信号,即 !rst_n
// %c0_i4 表示复位值
%q = seq.firreg %5 clock %0 reset async %1, %c0_i4: i4
%1 = comb.xor %rst_n, %true : i1 // 对复位信号取反
%2 = comb.extract %q from 0 : (i4) -> i1 // 获取 q的第0位
%3 = comb.xor %2, %true : i1 // 将 q的第0位进行取反
%4 = comb.extract %q from 1 : (i4) -> i3 // 获取 q的第1~3位
%5 = comb.concat %3, %4 : i1, i3 // 表示此逻辑:{~q[0],q[3:1]}
hw.output %q : i4
}
Arcilator仿真:
// RUN: arcilator %s --run --jit-entry=main
// 上述的 Core IR
hw.module @JSCounter(in %clk : i1, in %rst_n : i1, out q : i4) {
%c0_i4 = hw.constant 0 : i4
%true = hw.constant true
%0 = seq.to_clock %clk
%q = seq.firreg %5 clock %0 reset async %1, %c0_i4: i4
%1 = comb.xor %rst_n, %true : i1
%2 = comb.extract %q from 0 : (i4) -> i1
%3 = comb.xor %2, %true : i1
%4 = comb.extract %q from 1 : (i4) -> i3
%5 = comb.concat %3, %4 : i1, i3
hw.output %q : i4
}
// main函数(与--jit-entry=main中的main保持一致),内部实现类似testbench,只不过以.mlir格式存在
func.func @main() {
// 1 bit的 0,1 后续用于模拟时钟信号与复位信号
%zero = arith.constant 0 : i1
%one = arith.constant 1 : i1
// %lb 表示for循环中的起始值
// %ub 表示for循环中的终值
// %step 表示for循环中的步长
%lb = arith.constant 0 : index
%ub = arith.constant 10 : index
%step = arith.constant 1 : index
%rst_num = arith.constant 4 :index // 用于表示循环条件 i = 4时,触发复位信号
%locked_num = arith.constant 9 : index // 后续用于表示 i != 9时,时钟信号才发生变化
arc.sim.instantiate @JSCounter as %model {
// 获取输出端口 q,并输出其初始值
%init_val = arc.sim.get_port %model, "q" : i4, !arc.sim.instance<@JSCounter>
arc.sim.emit "counter_initial_value", %init_val : i4
// 循环10次
scf.for %i = %lb to %ub step %step {
// 将复位信号设置为高电平状态
arc.sim.set_input %model, "rst_n" = %one : i1, !arc.sim.instance<@JSCounter>
// 可以理解成保存设置,即更新(rst_n) 将复位信号设置为高电平状态 这个操作
arc.sim.step %model : !arc.sim.instance<@JSCounter>
// 判断 i = 4 是否成立
%cond = arith.cmpi eq, %i, %rst_num : index
scf.if %cond {
// 条件成立,将复位信号置为低电平,此时复位信号从高电平--->低电平跳转,计数器触发复位
arc.sim.set_input %model, "rst_n" = %zero : i1, !arc.sim.instance<@JSCounter>
arc.sim.step %model : !arc.sim.instance<@JSCounter>
}
// 判断 i != 9 是否成立
%cond1 = arith.cmpi ne, %i, %locked_num : index
scf.if %cond1 {
// 条件成立,时钟信号在每个cycle都执行从低电平--->高电平的跳变,计数器进行计数
arc.sim.set_input %model, "clk" = %zero : i1, !arc.sim.instance<@JSCounter>
arc.sim.step %model : !arc.sim.instance<@JSCounter>
arc.sim.set_input %model, "clk" = %one : i1, !arc.sim.instance<@JSCounter>
arc.sim.step %model : !arc.sim.instance<@JSCounter>
}
// 读取输出端口 q,并输出计数值
%counter_val = arc.sim.get_port %model, "q" : i4, !arc.sim.instance<@JSCounter>
arc.sim.emit "counter_value", %counter_val : i4
}
}
return
}
仿真结果:
counter_initial_value = 0
counter_value = 8
counter_value = c
counter_value = e
counter_value = f
counter_value = 0 // 触发复位后的值
counter_value = 8
counter_value = c
counter_value = e
counter_value = f
counter_value = f // 时钟信号没有发生跳变时的值
总结
综上所述,本文系统地分析了SystemVerilog在编译器视角下的多维度特性及其在CIRCT项目中的发展历程。从端口声明风格到信号类型的混用,再到复杂的多值态问题,这些因素共同影响着编译器设计的效率和准确性。通过对SystemVerilog路线图和特性支持进度的总结,重点阐述了SystemVerilog源码在CIRCT项目中实现的转换逻辑,并清晰地呈现了各项功能的进展和实现状态。最后,文章通过具体示例深入探讨了SystemVerilog的细节,包括用于SV转换路线的工具、Moore方言中的优化Pass,以及Johnson计数器的仿真实例。总体而言,这些探讨不仅为理解SystemVerilog在CIRCT项目中的应用提供了深入的视角,也为初学者提供了宝贵的实践经验和技术指导。
参考资料
[1] CIRCT官方文档
[2] LLHD The Low Level Hardware Description Language
[3]Slang覆盖特性表