1. 背景与研究动机
在深度学习计算中,算子是模型执行的基本计算单元,涵盖从矩阵乘法到逐元素操作(Elementwise)和归约(Reduction)等多种类型。深度学习框架的性能很大程度上取决于底层算子的实现效率。
近年来,随着 AI 专用硬件(DSA,Domain Specific Architecture)的快速发展,如何在不同硬件平台上高效实现深度学习算子成为研究热点。传统算子优化通常依赖手写高性能 C/C++ 或汇编代码,但这种方式开发成本高、可维护性差,也难以在不同硬件平台之间迁移。
Triton 作为一种新兴的 AI 算子开发语言,提供了介于高层框架与底层硬件之间的编程抽象。开发者可使用 Python 语法编写高性能算子,编译器自动完成向量化及内存访问优化,从而兼顾开发效率与执行性能。
随着 RISC-V 架构在 AI 加速领域的不断发展,越来越多的 RISC-V 处理器开始支持向量扩展(RVV)以及专用 AI 加速单元,使得在 RISC-V 平台上运行 Triton 算子成为值得探索的方向。
在前文《Triton 编译器在 RISC-V 上的移植与适配实践》中,我们已经介绍了如何在 RISC-V DSA 平台上成功运行 Triton 算子。本篇文章将进一步关注一个更实际的问题:Triton 算子在 RISC-V DSA 平台上的性能表现如何? 为回答这一问题,本文将通过一系列基准测试,对不同实现方式进行性能对比分析。
2. 测试环境、算子来源与评测方法
为了保证测试结果的严谨性,本文在RISC-V DSA 硬件平台上构建实验环境,以架构原生验证为目标,在可控条件下评估算子性能。
2.1. 硬件环境
-
平台:玄铁 C908X FPGA 开发板
-
架构特性: 高性能 RISC-V(RV64GCV)处理器,支持 1024 bit~4096 bit VLEN 的 RVV 向量扩展。
-
运行模式: Bare-metal(裸机)环境,排除操作系统的任务调度与中断干扰。
-
并行度: 单核单线程执行,用于评估算子的单核极限性能与指令效率。
-
2.2. 测试算子与测试平台
测试覆盖 Matmul、Elementwise(Add)与 Reduction(ReduceSum)等典型深度学习算子,包含两类实现路径:一类使用 Triton DSL 实现;另一类为基于 RVV intrinsic 的 C 基线实现,用于性能对照。为确保公平性,两类实现在相同输入形状、数据类型和运行配置下进行测试。C 基线采用玄铁官方工具链,Triton 版本实现采用 ZTC(生成 IR)与 ZCC(后端优化)的组合。两种路径分别按其常规工程方式构建,并在相同测试条件下进行性能对比。
Triton 实现流程说明:
Triton 版本算子遵循以下链路:首先由 ZTC 将 Triton Kernel 编译为中间表示(LLVM IR),随后接入 ZCC 编译器进行针对 RISC-V DSA 平台的后端代码生成与算子级优化,最终产出二进制执行文件。
2.3. 测试方法
本文采用基于硬件层面的精细化测量方法:
-
预热机制:每个算子在正式统计前均执行一次“冷启动”预热,以消除指令缓存(I-Cache)冷启动及内存初始化带来的波动。
-
多次采样:在预热完成后,对每个算子在不同输入规模(Shape)下连续执行 10 次,取其平均值作为最终结果。
3. 玄铁 C908X 硬件性能结果
为了直观比较 Triton 编译生成代码与手写 C 实现之间的执行效率,本文对下列实验结果进行了归一化处理,并统一采用 Normalized C 与 Normalized Triton 两个指标进行展示。
-
Normalized C(基准 归一化 值) 将手写 C 实现的执行周期数 作为基准,统一设定为 100%。该值用于作为所有算子的性能参考基线。
-
Normalized Triton(相对执行效率) 表示 Triton 编译生成代码的执行周期数相对于 C 实现的百分比,用于衡量 Triton 生成代码在目标硬件上的执行效率。
数值含义如下:
-
> 100% :Triton 执行周期高于 C 实现,性能比C算子差
-
= 100% :Triton 与手写 C 性能基本一致
-
< 100% :Triton 执行周期低于 C,性能比C算子好
通过这种归一化方式,可以消除不同算子规模带来的绝对周期差异,从而更加直观地比较 Triton 编译器生成代码与手写 C 算子 实现之间的性能差距。
3.1. Matmul算子
为深入分析 Triton 在高复杂度计算场景下的性能,本研究选取了 AI 算子中的核心算子——矩阵乘(MatMul)进行评测。在现代大语言模型(LLM)中,MatMul 是 Transformer 中自注意力机制和全连接层的核心计算,占据了模型推理和训练的大部分算力。其涉及大规模二维张量的运算和复杂内存访问模式,不仅直接影响模型性能,也对编译器在数据布局、向量化和访存优化方面提出了严苛要求。通过对 MatMul 的性能分析,可以全面评估 Triton 在 LLM 核心算子上的优化能力。
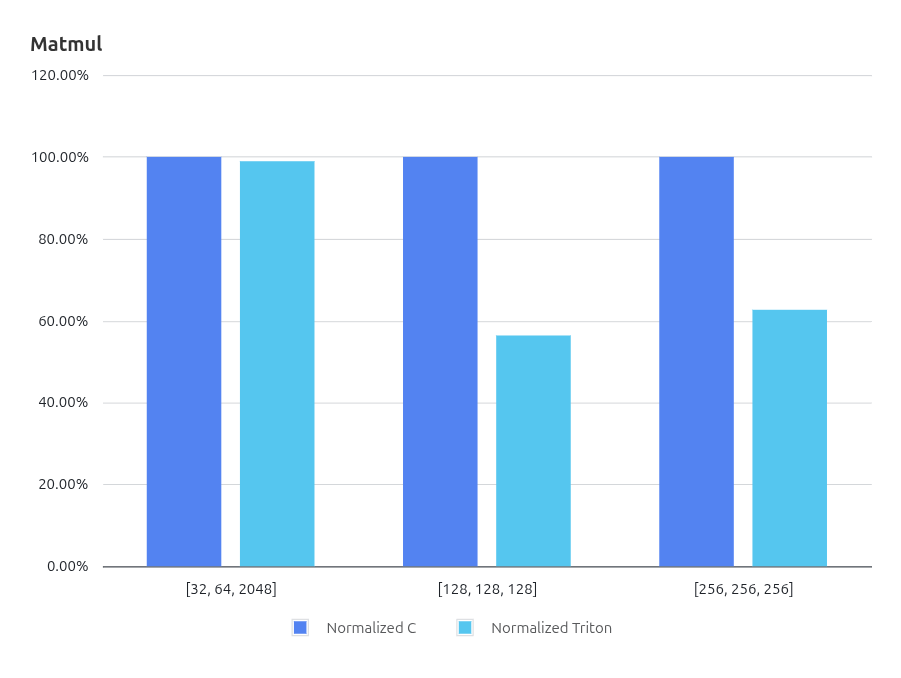
实验数据显示,Triton 在 Matmul 场景下整体性能优于基于 RVV intrinsic 的 C 实现。我们在实现中对核心计算流程做了算法改进,采用“M 内循环展开 + N 外循环向量化”的分块策略:在 M 方向通过展开提升数据复用与计算密度,在 N 方向通过向量化提升并行吞吐并改善访存连续性。该改进有效提升了整体执行效率,是本次性能提升的重要来源。
需要说明的是,本文对比中的 C 版本虽已进行了向量化优化,但并未进行深度手工调优。因此,本结果更体现该算法改进在当前实现路径下的收益,而非与极致手工优化算子库的直接性能上限对比。
3.2. Elementwise 算子
逐元素(Elementwise)算子是深度学习模型中最常见的一类基础算子,例如 Add、Sub、Mul、Div 等。其特点是计算逻辑简单、数据并行度高且易于向量化。由于不同元素之间不存在数据依赖,这类算子能够充分利用 SIMD 或向量扩展进行并行计算,同时具有较为规则的访存模式。因此,Elementwise 算子非常适合用于评估编译器在自动向量化与访存优化方面的能力。
3.2.1. Add算子Triton源码
@triton.jit
def add_kernel(
x_ptr,
y_ptr,
output_ptr,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(axis=0)
offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
x = tl.load(x_ptr + offsets)
y = tl.load(y_ptr + offsets)
tl.store(output_ptr + offsets, x + y)
3.2.2. Add算子性能结果
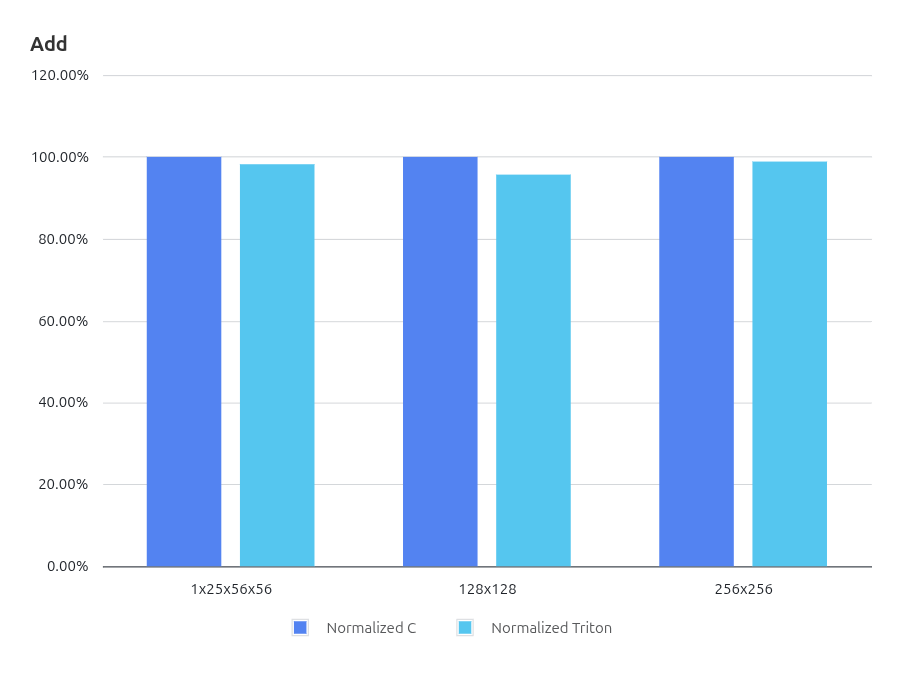
在 Elementwise(FP16 加法)算子测试中,实验结果显示,Triton 的性能均优于使用 RVV intrinsic 实现的 C 版本。对于开发人员来说,使用 Triton 编写算子的开发效率远高于 C,而性能几乎没有损失。
3.2.3. 汇编指令级对比分析
vsetvli a5, a4, e16, m8, ta, ma
sh1add a6, a3, a0
sh1add a7, a3, a1
vle16.v v8, (a6)
vle16.v v16, (a7)
sh1add a6, a3, a2
sub a4, a4, a5
vfadd.vv v8, v8, v16
vse16.v v8, (a6)
add a3, a3, a5
bnez a4, .LBB0_3
通过对生成的 RISC-V 向量汇编代码进行深层分析,可以发现两者在核心逻辑上高度一致,均采用了 vsetvli 配置向量长度、vle16.v 加载数据、vfadd.vv 执行计算以及 vse16.v 写回结果的典型循环模式。
Triton 通过自动向量化显著降低了开发门槛。对于 Elementwise 类算子,Triton 已能生成几乎媲美 C 版本的高效代码,从而充分释放 RISC-V V 扩展的计算潜力。
3.3. Reduction 算子
归约算子用于将一组数据压缩为单个结果,例如 Sum、Mean、Max 等。此类算子通常存在数据依赖,需要跨向量进行累加,对寄存器分配和循环展开较为敏感,因此能够反映编译器在循环优化和寄存器利用方面的能力。本文针对 FP16 输入数据,测试了 ReduceSum 算子在 axis=0 和 axis=1 两种情况下的性能。
3.3.1. ReduceSum (axis=0) Triton源码
@triton.jit
def reduce_kernel_2d(
x_ptr,
output_ptr,
n_rows,
n_cols,
BLOCK_SIZE: tl.constexpr,
):
pid = tl.program_id(axis=0)
col_offsets = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
col_mask = col_offsets < n_cols
acc = tl.zeros([BLOCK_SIZE], dtype=tl.float16)
for r in range(0, n_rows):
row_start = r * n_cols
offsets = row_start + col_offsets
x = tl.load(x_ptr + offsets, mask=col_mask, other=0.0)
acc += x
tl.store(output_ptr + col_offsets, acc, mask=col_mask)
3.3.2. ReduceSum (axis=0) 性能结果
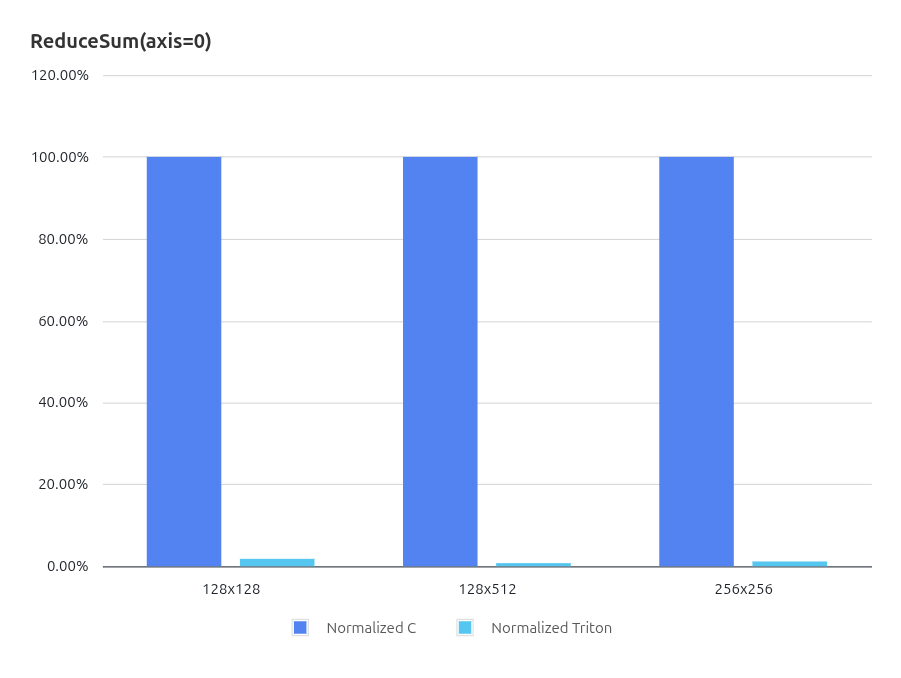
在 FP16 ReduceSum(Axis=0) 测试中,Triton 的性能领先于使用 RVV intrinsic 实现的 C 版本,并且随着矩阵规模扩大,这一性能差距基本保持稳定。需要说明的是,本文中的 C 实现虽然已经基于 RVV intrinsic 进行了向量化优化,但并未针对该特定规约模式进行深度的手工调优。
这一现象表明,在 Axis=0 规约这类计算模式下,并行策略与数据访问方式对 RVV 硬件性能的发挥具有重要影响,而 Triton 能够通过自动化调度与向量化映射获得具有竞争力的性能表现。
3.3.3. ReduceSum (axis=0) 汇编指令级对比分析
.LBB0_9:
vsetvli a1, s1, e16, m8, ta, ma
sh1add a4, a2, t6
sh1add a5, a2, a3
vle16.v v8, (a4)
vle16.v v16, (a5)
sub s1, s1, a1
vfadd.vv v8, v8, v16
vse16.v v8, (a4)
add a2, a2, a1
bnez s1, .LBB0_9
通过对生成的 RVV 汇编进行分析,Triton 采用列切块方案(如每 Program 处理 256 列),在行方向上进行循环。
这种方式的特点是:
-
高并行度:始终保持
VL(向量长度)级别的并行计算,利用vfadd.vv极低的指令延迟。 -
流水线友好:计算结果直接留在向量寄存器中参与下一次迭代,无需跨向量 Lane 移动数据,避免了高延迟的归约指令。
3.3.4. ReduceSum (axis=1) Triton源码
@triton.jit
def reduce_kernel_2d(
x_ptr,
output_ptr,
stride,
n_elements,
BLOCK_SIZE: tl.constexpr,
):
pid0 = tl.program_id(axis=0)
x = tl.load(
tl.make_block_ptr(
base=x_ptr,
shape=[n_elements * tl.num_programs(0)],
strides=[1],
offsets=[stride * pid0],
block_shape=[BLOCK_SIZE],
order=[0],
),
boundary_check=[0],
)
output = triton.language.sum(x, axis=0).to(dtype=x.dtype)
tl.store(output_ptr + pid0, output)
3.3.5. ReduceSum (axis=1)性能结果
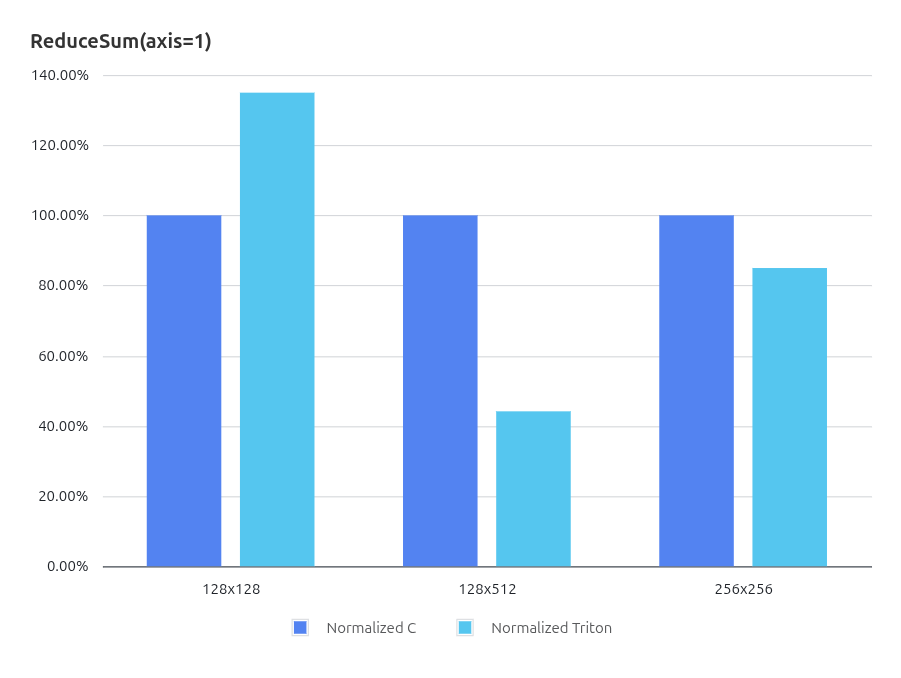
3.3.6. ReduceSum (axis=1)汇编指令级对比分析
.LBB0_5:
vsetvli a5, a4, e8, m4, ta, ma
sh1add s1, a3, a1
vle16.v v16, (s1)
sub a4, a4, a5
vsetvli zero, zero, e16, m8, tu, ma
vfadd.vv v8, v8, v16
add a3, a3, a5
bnez a4, .LBB0_5
# %bb.6:
vsetivli zero, 1, e16, m8, ta, ma
vmv.s.x v16, zero
vsetvli zero, a2, e16, m8, ta, ma
vfredusum.vs v16, v8, v16
vfmv.f.s fa5, v16
vsetivli zero, 1, e16, m1, ta, ma
vse16.v v16, (a0)
在 Axis=1 的实现中,Triton 展现了编译器在循环变换(Loop Transformation)上的巨大优势。
Triton分阶段规约 (Two-Stage Reduction):
-
第一阶段(累加):Triton 并没有在循环体内部直接调用高延迟的归约指令。相反,它通过 ZCC 的自动向量化,将行内的多个元素先通过
vfadd.vv指令累加到一个中间向量寄存器(如v8)中。 -
第二阶段(归约):仅在循环彻底结束后,才调用 一次
vfredusum.vs将中间向量压缩为最终的标量结果。 -
优势:由于
vfadd.vv的周期数(Cycles)远低于vfredusum.vs,这种策略将原本N次的高延迟归约操作优化为了N次低延迟加法 + 1 次高延迟归约。
4. 结论与展望
在 RISC-V DSA 平台上的测试中,Triton 算子展现出了很好的可行性和性能表现。通过兆松针对RISC-V架构深度优化过的ZTC Triton编译器,AI 算子库开发者可将算子逻辑与一些硬件相关的优化细节解耦,显著降低开发成本与周期。后续ZTC编译器会持续针对高维复杂算子(如 LayerNorm、FlashAttention)、多核并行调度与动态形状适配持续优化,以进一步提升RISC-V AI芯片的系统利用率,加速RISC-V AI芯片对模型的快速适配和性能优化。