引言
在现代芯片设计中,随着设计的复杂性不断增加,为确保设计在投入生产前达到预期的功能和性能标准,降低后期修复成本和风险,硬件仿真扮演着至关重要的角色。
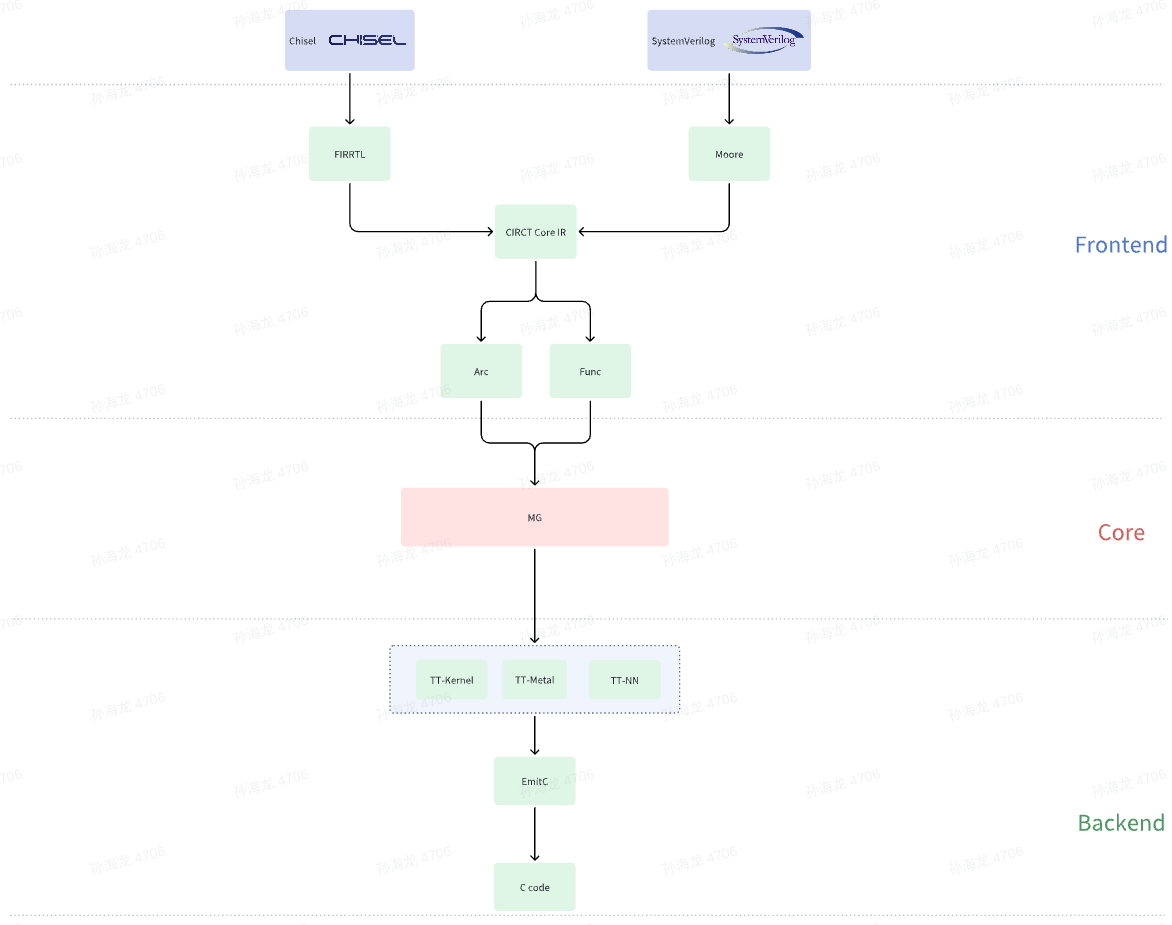
为了打破传统处理器内存墙的问题和进一步缩短设计周期和降低成本,本文提出了一种新的硬件仿真思路:使用Dataflow芯片加速RTL(Register Transfer Level)仿真。为了验证这种新的仿真思路,正文中会先普及一些必要的知识背景,如CIRCT项目概述、相较于传统的硬件仿真CIRCT有何优势、为解决传统硬件仿真的不足而提出的新的解决方案–Dataflow计算模型。在了解这些必要的知识背景之后,本文会给出对应于这种新的仿真思路的理论依据。在实践上,我们采用的是由Tenstorrent公司设计出来的Dataflow AI芯片,以及由MLIR/CIRCT开源项目生成的目标IR。实践大致流程如下:
暂时无法在飞书文档外展示此内容
但本文仅从理论的角度出发探讨这种新思路的可行性,并不会展示相应的性能数据。后续我们会推出另一系列文章去深度讲解CIRCT项目以及具体的流程,如SystemVerilog/Chisel源码是如何通过一个接一个的Pass被转换成特定的目标IR,并将目标IR输入到由Tenstorrent公司设计的Dataflow芯片上运行的。此系列文章中还会详细介绍当前常见的两种硬件仿真模式(Cycle-Based和Event-Driven),届时从实际出发,通过对比各种性能数据,以此来验证Dataflow芯片加速RTL仿真的可行性以及性能。
背景:CIRCT 起源
CIRCT(Circuit IR Compilers and Tools)项目是在Chris Lattner于2021年ASPLOS学术会议上分享题为“软硬件协同设计时代的编译器设计黄金时代”的演讲中首次提出的。当时,Chris Lattner正在SiFive公司担任工程平台总裁,领导着RISC-V产品和工程组织。RISC-V作为一种开放的指令集架构,与Chris Lattner曾在Google任职时研发的MLIR(Multi-Level Intermediate Representation)编译基础架构在理念上十分契合。MLIR是为了解决软件碎片化,为了能解决碎片化开源EDA工具现状、适应计算机体系结构的发展趋势以及加速硬件设计,CIRCT项目应运而生。
在解决碎片化开源EDA工具现状方面,CIRCT计划将开源的EDA工具的功能整合到同一框架中,如:
-
用于形式化验证的SMT(Satisfiability Modulo Theories)方言;
-
用于调试的Debug方言;
-
用于RTL仿真的Arcilator等。
而由于计算机体系结构的发展趋势,带来了两个核心问题:
-
如何设计混合通用和专属组件的复杂的异构片上系统?
-
设计出来后,如何进行编程?
CIRCT认为定义合适的方言以及实现方言之间的转换是解决这两个核心问题的关键。因此CIRCT基于MLIR的开发方法去定义方言,以及在这些方言基础之上构建一些可重用的功能模块去解决这种棘手的设计和相关问题。
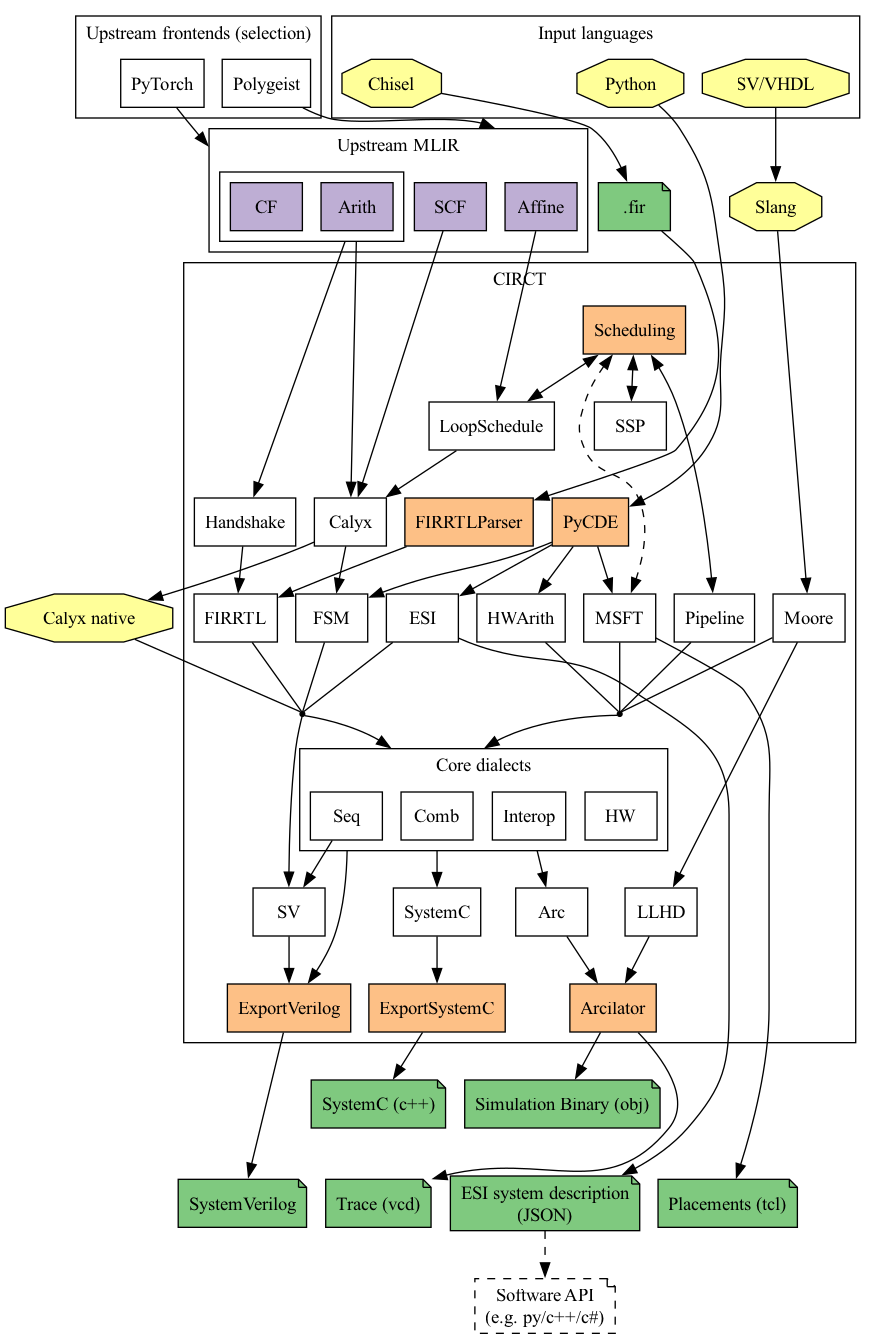
-
MLIR开发方法:MLIR项目用一种新颖的方式去构建可重用的、可扩展的编译基础设施,旨在解决软件的碎片化(CIRCT想解决EDA工具碎片化)的问题,加速异构硬件的编译和减少特定领域编译器的构建成本,以及将已存在的编译器接入到MLIR框架中。
-
方言:在层级比较高时,方言是一种映射某个语言中的特性的集合如FIRRL(映射Chisel中的特性)、Moore(映射SystemVerilog中的特性),FSM(表示有限状态机);在层级低一些时,方言就和语言无关了,如核心方言层中的Seq(表示时序逻辑)、Comb(表示组合逻辑)。
-
方言转换:高层级方言向低层级方言转换,如上图所示,将Moore/FIRRTL方言转换为核心方言层。
CIRCT 优势
由于CIRCT是基于MLIR编译器框架的硬件编译器项目,即重用MLIR中的技术定义了CIRCT项目中的各种不同层级的方言及优化Pass。因此,在CIRCT项目中,允许在不同层级的方言中实现一些必要的优化,如减少内存的使用、公共子表达式消除等等。同时,因多层级方言的存在,如在处理Moore方言时,由于Moore方言保留了一些源码层级的特性(保留了数组、结构体等信息),相较于更底层的LLVM IR更便于分析和优化的实现。
除此之外,在CIRCT项目中,也可对RTL级设计进行改进和仿真、实现高层级综合(High Level Synthesis)、从顺序代码的细粒度CDFG(Control and Data Flow Graph)表示中提取数据流模型等等。
传统硬件仿真的不足
传统硬件仿真的不足主要是架构上的不足,如冯诺依曼架构是将数据和指令都存放在存储器中,由于频繁的访问存储器,导致能效比低,进而导致内存墙等问题。为了能改善内存墙等问题加速硬件仿真,一个办法是利用CIRCT的优势,如减少内存的使用、公共子表达式消除等;另一个办法是从根源上解决内存墙的问题,如使用Dataflow芯片进行硬件仿真。具体有关Dataflow架构和冯诺依曼架构的对比请查看1. 探索Dataflow架构:从理论到芯片实现。
再比如SPMD(Single Program Multiple Data)数据并行计算模型,每个处理器从外部内存读取数据到本地内存中进行处理,处理完成后再将结果写回到外部内存。这种方式使得处理器之间的通信主要通过外部内存进行,从而导致较高的功耗和通信瓶颈。虽然可以通过片上内存进行处理器之间的通信,但这需要显示管理片上内存,并和全局内存进行区分,增加了编程的复杂性。
类似开源RTL仿真器Verilator,是一个支持Verilog/SystemVerilog的cycle-based开源仿真器。它的核心功能是将SV代码转换为C++或SystemC,从而实现快速的仿真。并且支持多线程仿真,其多线程功能是通过V3Order实现的。即使在多线程模式下,Verilator的前端,即到V3Oder阶段,仍然是串行执行的,因为V3Oder会建立一个细粒度语句级的依赖图。在串行模式下,依赖图将所有语句转化为一个完整的串行序列。在并行模式下,V3Partition会将细粒度的图转换为粗粒度的图,并且利用多核CPU的并行计算能力执行这些粗粒度的图,使Verilator能同时处理多个独立的任务或同一时间模拟多个时钟周期,以此来增大同一时间的吞吐量或减少总的仿真时间,从而提升硬件仿真性能。
但由于Verilator多线程仿真功能的实现依旧是基于传统架构的,因此也面临着一些挑战,如:
-
在任务执行过程中,线程需要进行通信和同步,这可能会导致性能下降,尤其是在任务粒度较细的情况下。
-
需要高效的内存分配和管理策略来确保每个线程拥有充足的内存资源。如果某些线程的任务过于繁重而其他线程处于空闲状态,将导致资源的浪费,降低整体仿真效率。
-
多线程仿真可能使得调试和维护变得更加复杂。由于多个线程同时运行,错误的定位和修复可能需要更多的时间。
-
多线程仿真可能会导致资源竞争,尤其是在访问共享资源时。如果多个线程同时尝试访问同一资源,可能会导致性能下降或错误。
-
处理大规模数据时,运行时的同步消耗会带来较大的开销,同时由于通行量的大幅增加,也会造成通信带宽不足,增加延迟。
-
处理大规模数据需要大量内存空间,如果内存容量有限,会出现频繁的数据换页现象,导致内存访问延迟增加,而这种内存瓶颈会拖慢整体计算速度,降低资源利用率。
综上所述,即使是将一个程序划分为多个独立的子图,再利用多核CPU的并行计算能力,仍需要面对同步通信限制和内存墙等问题。但划分子图这种数据流编程的方式是可取的,因为数据流编程天生具有并行性,并且不需要将计算的中间结果写回内存,仅关注数据在图上是如何流动的。因此我们认为Dataflow计算模型在加速硬件仿真方向上是一个新的解决方案。
新的解决方案:Dataflow计算模型
Dataflow计算模型背景请查看1. 探索Dataflow架构:从理论到芯片实现。
-
纯天然的并行计算,且不用考虑内存墙问题。
-
不同于Verilator多线程仿真,Dataflow计算模型还支持更灵活的并行方式,如:
-
任务(task)并行:将一个大的任务划分成多个独立的小任务,这些小任务可以在不同的处理器上同时执行。
-
图(graph)并行:将计算表示为一个图,结点表示处理单元,边表示数据之间的依赖。整个计算图会被划分成多个独立的子图,最后将各个子图的结果根据依赖关系合并在一起,生成最终结果。
-
流(streaming)并行:流是随着时间推移生成的连续数据流。流并行会将涉及到的流划分成多个独立的块(chunk),最后将各个块的结果按照时间顺序合并在一起,生成最终结果。
-
流水线(Pipeline)并行:请查看7. 探索数据流芯片的应用领域
-
-
不同于Verilator多线程仿真的同步和通信机制,Dataflow计算模型通过更高效的任务调度和数据流动机制,强调数据流动的特性及数据之间的依赖,一定程度上减少了同步与通信带来的开销,提高了计算效率。
-
避免了传统架构中的指令调度和控制开销,每个节点只在需要时执行,减少了不必要的计算和数据传输,能效比更高。
加速RTL仿真新思路:Dataflow计算模型
硬件设计语言如Verilog/VHDL,不同于软件编程语言,硬件的执行逻辑是并行的,因为电路中的各个部分可以同时工作。而这种并行性是通过电路中的组合逻辑和时序逻辑来实现的。
同样地,Dataflow计算模型也是一种天然的并行计算模型。前文提到Dataflow计算模型强调的是数据流动以及数据之间的依赖关系,因此可以形成有向无环图。在这种天然的优势下,与硬件的并行执行逻辑十分契合,并且Dataflow中的每个算子只要获得所有输入数据就可以立即执行,无需等待特定时刻再进行同步。
利用Dataflow计算模型纯天然的并行性加速硬件仿真,优势如下:
-
Dataflow计算模型中的算子只有在获得所有输入数据后才会执行。这与硬件中的组合逻辑电路的工作方式非常相似,即只有当所有输入信号都准备就绪时,电路才会产生输出。
-
Dataflow计算模型中的算子都是独立的计算单元,可以并行执行。而硬件电路中的组合逻辑电路同样是并行工作的,各个部分可以同时根据输入信号产生对应的输出。
-
通过动态调度输入数据,Dataflow计算模型可以根据当前的计算资源情况,灵活地决定算子的执行顺序。这样可以最大限度地利用可用的计算资源,使输入的数据尽可能的并行执行,避免资源的浪费和等待时间。
-
在传统的由时钟驱动的硬件仿真中,需要在每个时钟周期进行全局同步。而Dataflow计算模型中的算子只要在满足数据依赖的条件下即可进行同步。这大幅减少了类似SPMD模型的同步机制带来的开销。
-
Dataflow计算模型中的算子是独立的模块,这种模块化的设计使得各个计算单元之间的耦合度降低。与硬件中的模块化设计十分相似。
-
Dataflow计算模型具有内部缓存机制,以此来存储中间计算结果,大大减少了对内存的访问次数。内部缓存机制使得Dataflow计算模型能降低数据访问延迟,提高计算速度。
总结
随着现代芯片设计越来越复杂,为了降低后期修复风险和设计成本,本文提出了一种加速RTL仿真的新思路:使用Dataflow芯片加速RTL仿真。本文主要是从理论出发,验证这种新思路的可行性。在给出相应的理论依据之前,本文首先普及了一些背景知识,如CIRCT项目概述、相较于传统的硬件仿真CIRCT有何优势、为解决传统硬件仿真的不足而提出的新的解决方案–Dataflow计算模型。在此基础上说明此计算模型的优势以及为什么可以用来加速RTL仿真。主要是因为Dataflow计算模型在设计上就纯天然地支持并行计算,这与硬件电路的并行执行逻辑非常契合,并且不用考虑传统架构中内存墙问题,使得Dataflow加速RTL仿真成为可能。
参考资料: