背景
在AI技术飞速发展的今天,底层基础设施的复杂性也在不断提升。无论是深度学习框架的多样化,还是AI芯片和加速器的百花齐放,都让 “如何高效实现和维护算子库” 成为业界关注的核心问题。算子库不仅是AI模型性能的基础引擎,更是连接上层算法与底层硬件的桥梁。本文将带你了解算子库编程语言的发展现状、技术趋势,以及Triton等新兴语言带来的创新启示。
算子、算子库与算子库编程语言
在深度学习中,模型的每一步计算——如矩阵乘法、卷积、归一化等——都由算子完成。这些算子共同构成了模型执行的核心计算路径。为了让模型能够在 GPU、NPU 等不同硬件上获得高效运行性能,业界通常会维护一套高度优化的算子库,如 cuBLAS、cuDNN、OneDNN 等。算子库为框架提供底层性能支撑,其优化质量往往直接决定模型的整体速度与扩展能力。
算子库 DSL(Domain-Specific Language)是一类用于描述和生成高性能算子的专用语言。它们通常基于已有的通用语言(例如 C++ 或 Python)扩展领域特定的语法能力,使开发者能够更自然地表达算子的计算逻辑、数据访问模式以及调度策略。通过 DSL,算子行为可以被更精确地描述,随后由编译器自动生成面向不同硬件平台的高效实现,从而大幅减少手写优化的成本,加速算子开发流程。
主流算子 DSL 发展全景:性能和生产力的 Trade-Off
早期 AI 算子库几乎都采用 C/C++,主要因为它能直接对接 CUDA、OpenCL、HIP 等底层 API,并可通过内联汇编或 PTX 进行指令级优化;同时,C/C++ 提供精细的内存控制能力,非常适合早期 GPU 内存紧张的环境。结合成熟的编译器和调试工具链,C/C++ 因而成为当时算子实现的自然选择。
随着深度学习快速发展,模型迭代速度与开发效率愈发重要。Python 以其简洁的语法和强表达力,通过 JIT 编译、优化与代码生成机制,在保持高生产力的同时仍能获得合理的性能,因此逐渐成为主流算子 DSL 的前端语言。
在 2025 年 Triton Conference 上,OpenAI 的 Triton 语言创始人 Philippe Tillet 回顾并梳理了 2024—2025 年间多种算子开发语言如何在性能(performance) 与开发效率(productivity) 之间进行权衡与取舍。如图【1】、图【2】:
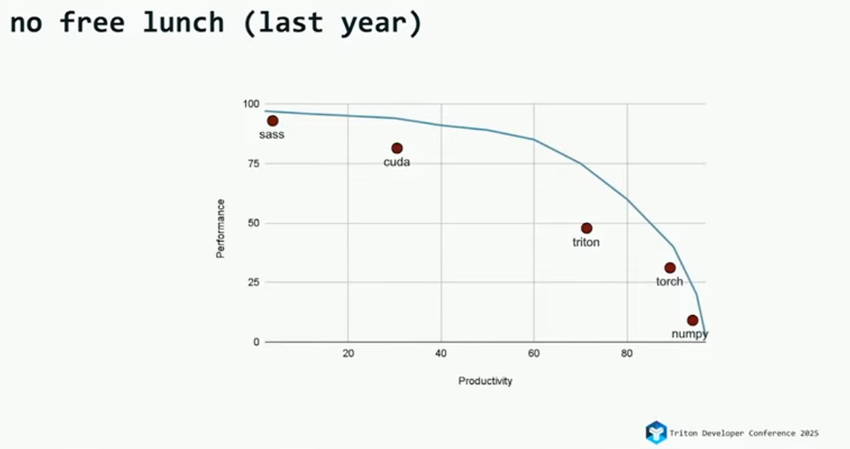
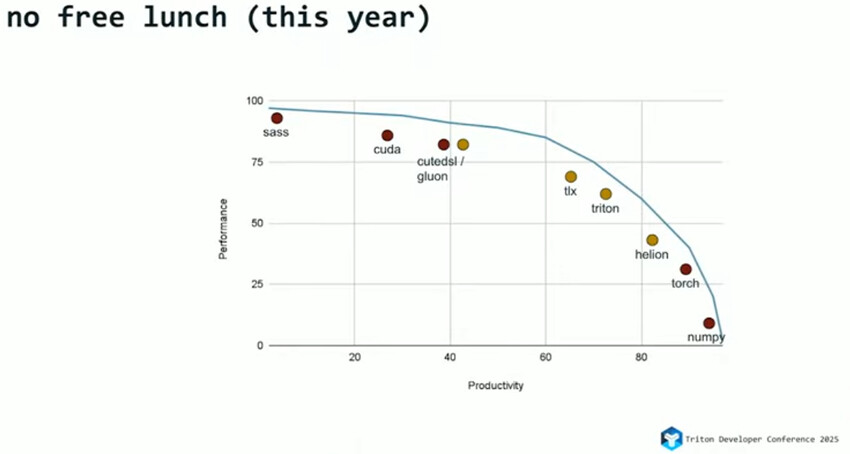
总结起来2024-2025新增的算子DSL的发展呈现两种态势:
-
Triton 的“向下走”趋势:采用Triton类似的编程模型,在软件层通过多种机制来更贴近硬件细节,以更好地满足面向特定硬件的深度优化需求。如gluon, tlx等。
-
CUDA 的“向上走”趋势:推动原本 CUDA c++ 接口Python 化,提升编程体验,降低使用门槛。如cutedsl。
在 GPGPU 编程领域,算子开发语言在性能的设计取舍,往往围绕四类关键优化问题展开:线程绑定(Thread Binding)、内存布局(Memory Layout)、指令张量化(Intrinsic Tensorization)与流水线(Pipelining)。不同 DSL 的可用性与性能差异,本质上都源于对这四类手动优化的抽象方式与自动化能力的不同。
CUDA
CUDA(Compute Unified Device Architecture)是 NVIDIA 为自家 GPU 提供的一整套编程工具和软件框架。它的基础是 CUDA C++ —— 通过在C++ 基础上新增关键字与语法,让开发者可以直接操控 GPU 的硬件特性,例如:GPU线程与内存管理机制。
CUDA C++ 给开发者提供了非常高的灵活性, 这种灵活性使得 CUDA 具备极高的性能上限,经验丰富的 GPU 工程师甚至能用它实现接近 GPU 峰值的性能。 然而这也使得高性能 CUDA 算子的实现具有极高的门槛,开发者必须深入理解 GPU 微架构、内存层级以及并行模型。此外,CUDA 代码虽然能在新 GPU 上运行,但性能不一定能随硬件升级而自动提升,往往需要针对新的硬件进行重新优化。
为了让更多开发者使用 GPU 而不用深入研究底层细节,NVIDIA 构建了一系列高层、封装良好、但通常闭源的库,比如:cuDNN(深度学习运算加速库),cuBLAS (线性代数运算), cuFFT(快速傅里叶变换),CUTLASS (高性能算子构建框架,提供对 GEMM 等核心计算的模板化实现)。
与此同时,为了提升 CUDA 软件栈的易用性,其生态系统也逐步向更友好的 Python 接口演进。
CuTe DSL
CuTe DSL 是 CUTLASS 4 中新增的 Python eDSL,允许开发者用 Python 而非 C++ 模板来编写高性能 GPU 内核。它的设计目标是与原有的 CuTe C++ 编程模型保持语义对等——也就是说,CuTe DSL 以 Python 的语法表达与 C++ CUTLASS 内核相同的高级概念,例如算子结构、数据布局、线程组织、数据分片以及张量抽象等。
CuTe DSL 使用 JIT(即时编译)机制,显著缩短了传统 CUTLASS C++ 模板代码的编译时间,也让算子开发与调试过程更轻量。同时,由于基于 Python 生态,它更容易与 PyTorch、JAX 等深度学习框架集成,并支持 DLPack 等跨框架数据互操作机制。在性能方面,官方 Benchmark 显示 CuTe DSL 在 dense GEMM、grouped GEMM 等关键算子上可达到与 CUTLASS C++ 非常接近的性能。
目前 CuTe DSL 仍在持续演进中,对部分功能、硬件特性和语法的支持尚未完全覆盖,且编译器 Pipeline 属于闭源状态。
Triton
Triton 是由 OpenAI 开发的基于 Python 的开源 DSL 编程语言,旨在简化高性能 GPU 算子库代码的编写。Triton 采用 Tile-Based 编程模型,提供灵活的 Tile 级数据操作,简化了线程块的管理。它专注于底层计算操作,由编译器自动处理共享内存、线程并行等复杂细节,从而降低并行编程的难度,提升开发效率。开发者只需掌握基本的并行原理,即可高效地编写高性能算子。
具体来说:
-
Layout 控制:编译器会根据访存地址计算中蕴含的 axis / contiguity(连续性)/ alignment(对齐) 等信息推断 Tile 数据如何分配到 warp/thread,以及在 shared memory 中的排布方式。
-
Layout inference & conversion:对于诸如
dot/mma这类具有特定布局要求的指令,编译器会自动推断并选择合适的 layout,同时在需要时插入必要的 layout 转换,以满足指令约束。对于共享内存访问的 bank conflict,会使用 SwizzleLayout 改变数据排布。 -
编译提示(compiler hints):可使用
tl.multiple_of显式告知编译器某些值满足倍数或对齐约束,使其能更大胆地进行访存合并等优化。 -
LinearLayout:近些年 Triton 的布局体系在持续演进,引入了更统一的布局表示(LinearLayout),让编译器更容易在不同 layout 之间进行转换。
-
-
内存管理
-
共享内存分配:编译器自动管理共享内存的使用,通过生命周期分析 + 加上图着色之类的内存分配算法最大程度减少共享内存的占用。
-
访存coalesce:在布局允许的前提下,把零碎的访问组织成更规整、更符合硬件偏好的访问序列,提高带宽利用率。
-
-
指令张量化
-
MMA指令:Triton 会根据算子的 dtype/shape/目标架构, 在满足条件时尽量映射到相应的 Tensor Core 路径(走 mma 还是 wgmma 等)。
-
TMA指令:增加了Tensor Descriptor操作,提供更加详细的张量布局信息,方便编译器在 target 允许的情况下映射到TMA指令。
-
-
软件Pipeline:编译器会分析循环依赖关系,在保证正确性的前提下插入必要同步点,并尝试把load/compute/store 组织成流水以隐藏延迟。
-
通过设置
num_stages参数,可以指定软件Pipeline 的 stages。 -
Triton上游也在不断优化编译器的Pipeliner,支持任意调度模式,支持更复杂的调度模式来调度诸如 BlackWell mma 之类的 op。
-
Warp specialize:编译器在支持warp specialize 机制的平台,会将用户撰写的串行的Triton代码转换为多执行流的 warp specialization 的形式,达到warp层级的pipeline。
-
总结:Triton 通过对 GPU 编程模型进行高度抽象,屏蔽了实现高性能内核时所需处理的大量底层细节,例如 Tile 布局、内存层次结构、数据搬移以及异步执行等。得益于这种设计,用户可以用相对少量的代码编写出高效的 GPU kernel。然而,这也带来了一个自然的结果:当关键的性能相关机制全部交由编译器自动处理后,在碰到性能问题时,用户能够通过手动调优进一步提升性能的空间就变得有限。Triton的高度抽象几乎不暴露硬件相关细节,提升了在不同 GPU 架构间的可移植性,同时意味着:只要某个专用 DSA(Domain-Specific Accelerator)实现了对应的 lowering 机制,Triton 程序也能够在该加速器上快速适配并高效运行。
Gluon
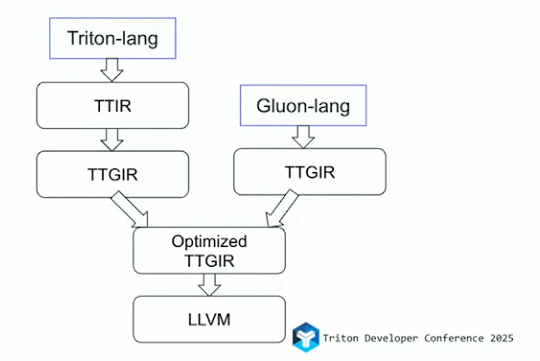
Gluon 是一种基于与 Triton 相同编译器软件栈的 GPGPU 算子库编程语言(图【3】),OpenAI设计出Gluon是为了进一步发掘NVIDIA GPU的性能,通过Gluon编程语言暴露更多的硬件给算子库编写者,让其编写算子库的时候可以控制更多的硬件细节。所以和 Triton 不同的是,Gluon 是一种底层语言,它赋予用户在实现内核时对于硬件细节有更大的控制权,从而Gluon编程语言的通用性就不如 Triton,目前Gluon的设计主要是针对NV最新硬件特性,其主要特点有以下几点。
-
显式的 layout 管理与转换:Gluon重写了 Triton 的
arange等op,增加 layout 参数, 提供了显式的 layout 管理机制。用户可以直接使用针对指定场景的 BlockedLayout (指导Memory Coalescing),SwizzledSharedLayout (避免bank conflict)等 layout,也可以使用通用的 LinearLayout 来表示特殊的 layout 需求。 同时 Gluon 提供了convert_layoutop用于 layout 的显式转换操作。 -
共享内存与异步传输:Gluon 允许用户通过
allocate_shared_memory显式申请共享内存,而通常的gl.load/gl.storeop则视为直接读写数据到寄存器。显式的共享内存分配在以下场景中对于性能有较大的提升:-
异步数据拷贝:使用
async_copy_global_to_shared可以在全局内存与共享内存之间执行异步传输,实现数据加载与计算的重叠。 -
Tensor Core 与 TMA 支持:如 Gluon 提供的 Tensor Core、TMA 等硬件接口通常要求数据位于共享内存中。
-
线程同步:共享内存还能用于存储信号量,支持线程间同步操作。
-
-
显式的异步指令与软件流水线:Gluon 提供了显式的异步指令来执行诸如全局内存读写等高延迟操作。异步指令使得内存访问可以与计算任务并发,形成经典的软件流水线,有效提升吞吐量。不同 GPU 架构对异步指令的支持有所差异,目前gluon针对不同的平台采取的是提供不同的同步操作。例如 NVIDIA Ampere 架构提供了:
async_copy_global_to_shared,commit_group,wait_group。这些指令协同使用可以实现高效的异步数据流管理。 -
指令张量化(Intrinsic Tensorization)为了进一步加速矩阵与张量计算,Gluon 对 GPU 的张量计算指令提供了原生支持,包括:
-
TMA(Tensor Memory Accelerator): TMA 是 Hopper 及更新架构提供的一种硬件加速特性。它使用“张量描述符”统一描述 N 维数组的访问方式,牺牲一些寻址灵活性,换取更高的访问效率,尤其适用于大规模张量数据搬运。
-
Async MMA instructions:Hopper 架构的
warpgroup_mma(WGMMA: Warp-Group MMA)和 Blackwelltcgen05_mmaop 。WGMMA 是 Hopper 架构提供的异步张量核心指令,用于执行矩阵乘加运算。它允许多个 warp 协作并进行流水化执行,是构建高性能矩阵运算内核的关键工具。
-
-
Warp Specialize:Gluon 提供
warp_specialize为同一 kernel 内不同 warp 指定不同的执行函数,这与传统的 “所有线程执行完整的算子实现” 相比 ,可以减少线程分歧,优化内存访问等。而且通过warp_specialize显式声明各 warp 的职责,并使用 barrier 进行同步,能够将数据加载、计算、写回等不同阶段交由不同 warp 负责,从而实现高度重叠与流水化的执行。
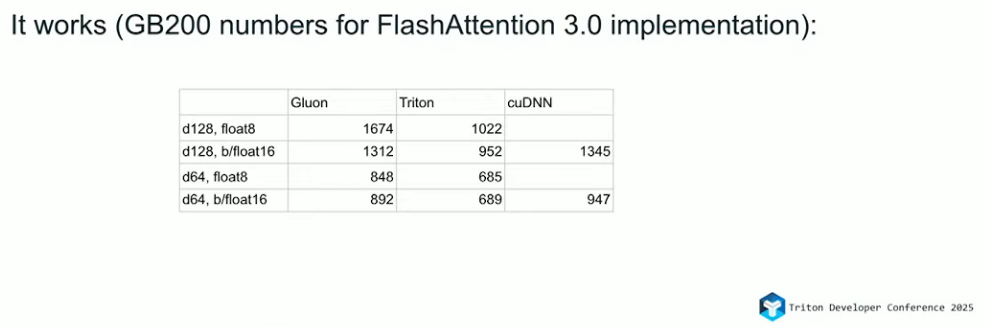
总结:在 Gluon 中,诸如 Tile 布局、内存分配、数据搬移以及异步处理等原本由 Triton 编译器自动管理的机制被显式暴露给开发者。通过让程序员直接控制这些关键性能路径,Gluon 在保持良好可用性的同时,能够进一步逼近硬件极限:如果说 Triton 通常能达到约 80% 的硬件性能,那么 Gluon 则有潜力将性能提升到 90% 甚至更高,如图【4】所示,Gluon实现的在FlashAttention性能逼近CUDA实现的cuDNN算子库性能。
随着这些新接口的引入,算子开发者在编写自定义算子时需要理解更多底层 GPU 的行为特性。虽然它们能显著提升算子性能,但也在一定程度上提高了算子的开发门槛,让开发流程更加复杂。新增的接口依赖于 Hopper、Blackwell 等新一代 GPU 才具备的硬件能力,这意味着使用这些特性的 Gluon 算子在旧 GPU 上无法直接运行,必须依赖编译器在不具备对应硬件能力的设备上进行“降级”处理,将新指令替换为传统实现。而且随着 GPU 架构持续演进,未来可能出现更多新的执行模型、指令集或内存层次结构。为了充分利用这些新能力,框架必须继续扩展现有接口或新增算子定义,使其能够描述更丰富的硬件特性,这会进一步加剧可移植性和扩展性方面的问题。
TileLang
TileLang 基于 TVM 的 GPU 算子库编译框架,专注于为深度学习算子在用户层提供简洁的编程接口和高效的代码生成。和 Triton 一样 TileLang 也是以 TILE 作为基本编程单元的编程语言。
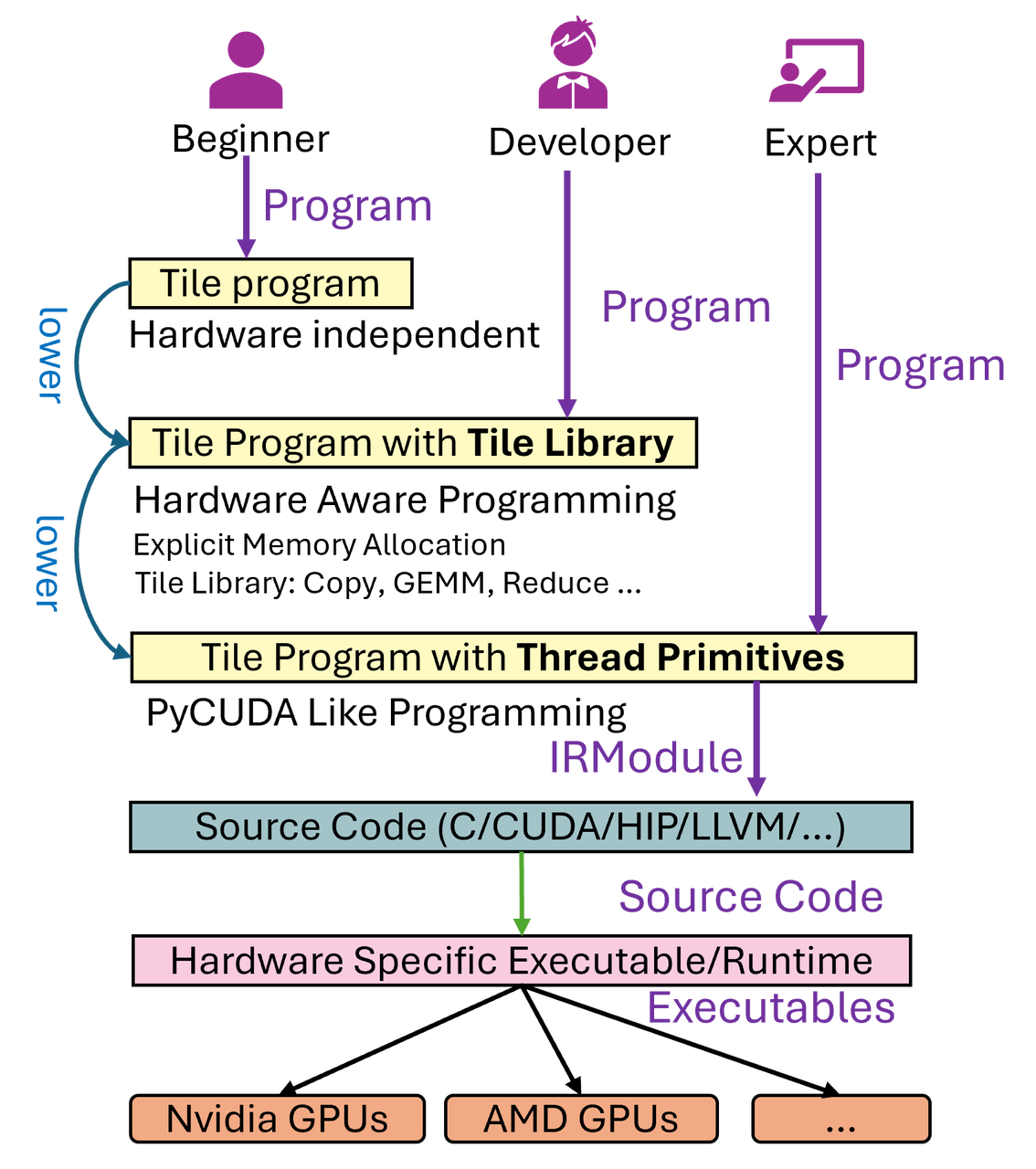
根据 TileLang 官方文档介绍,TileLang 为异构加速器(如 GPU)提供了分层次的编程接口,以适配不同水平与需求的开发者。其总体目标是:在保持高效性能的同时,为用户提供尽可能友好的编程体验。TileLang 目前定义了三种编程层级:
- Level 1:入门级(无需了解硬件细节)。这一层级面向希望专注于算法逻辑,而不需要理解底层硬件结构的用户,由编译器完全负责硬件相关优化。
注意:Level 1 目前尚未完全实现,因此仍处于预览状态。 - Level 2:开发者级(理解基本硬件模型;使用 Tile Library)。Level 2 面向已经具备 GPU 内存层次结构和基本性能优化概念的开发者。TileLang 在这一层级提供了一个 Tile Library,其中包含针对不同硬件架构优化的基础算子与模式,如常见的矩阵乘(T.gemm)或 Tile-Based 的T.copy,T.clear等op 。使用 Level 2 的开发者不必深入理解线程细节,但可以通过选择合适的 Tile 操作来获得较好的性能。
- Level 3:专家级(直接操作线程与硬件特性)。Level 3 为熟悉 GPU 底层机制的专家用户设计。该层级提供线程原语和其他底层结构的直接访问,从而可以对性能关键内核进行细粒度控制。
在目前的 TileLang 工作流中,开发者往往会同时使用 Level 2 与 Level 3,以兼顾高层抽象的可编程性和底层线程/内存控制带来的性能优化空间。TileLang 针对高性能算子生成中主要在以下方面提供支持:
- Layout 管理与自动推导:
- Layout Inference:为减少用户在 layout上的繁琐工作,TileLang 编译器提供了Layout Inference(布局推断)机制。这一过程包括 3 个步骤。第一步是 Strict Layout Inference,比如像矩阵乘这样的算子,对数据 layout 有很强的约束。第二步是 Common Layout Inference(通用布局推理)。比如,对于与上一步已确定 layout 相连的表达式,它们的 layout 也应该是确定的。第三步是 Free Layout Inference,即对于剩下的 Free Layout 进行推导。
- 显式注解:用户希望明确指定某段 buffer 的布局时,可以使用显式注解 (T.annotate_layout op )来覆盖自动推断。这种机制在需要控制 memory coalescing、tensor core 对齐格式等场景十分关键。
- 显式硬件内存分配:TileLang 允许用户显式声明数据放置在哪一层硬件存储中。例如在 GEMM 中:
- T.alloc_fragment 通常用于生成累加器寄存器。TileLang 在编译期间使用布局推断过程来生成对应的 T.Fragment 对象,该对象决定如何为每个线程分配相应的寄存器文件。
- T.alloc_shared 则为输入矩阵 tile 分配共享内存,以提高访存效率。
- Target 相关指令与优化机制
- 异步copy: TileLang 使用统一的 T.Copy 表达 global ↔ shared ↔ register 之间的数据搬运请求。然后编译器会根据 target 决定:是否生成异步拷贝(如 cp.async),是否使用TMA指令。
- 矩阵乘:TileLang 的算子(特别是 T.gemm)会根据硬件自动选择不同的矩阵乘指令:在 A100(Ampere) 上使用 mma(tensor core),在 H100(Hopper)上使用 WMMA 或 WGMMA。
- 软件Pipeline:TileLang 支持以声明式方式(T.Pipeline op )构建软件 pipeline。编译器会分析 loop依赖,插入同步指令。在编译到 Ampere 架构时,它会自动插入 cp.async 系列指令来实现流水线。在 Hopper(H100)上TileLang 的 pipeline 能生成更复杂的 warp specialization 代码: 一部分 warps 被指定为 Producer warp(调用 TMA 从 global → shared),其余 warps 作为 Consumer warp(执行 wgmma 运算)
总结:TileLang 通过布局推断机制和手动布局注释,显式内存管理,线程级元语的支持等支持,让算子能够在不同的GPU平台都能达到与厂商库和 Triton 相当或更优的性能。
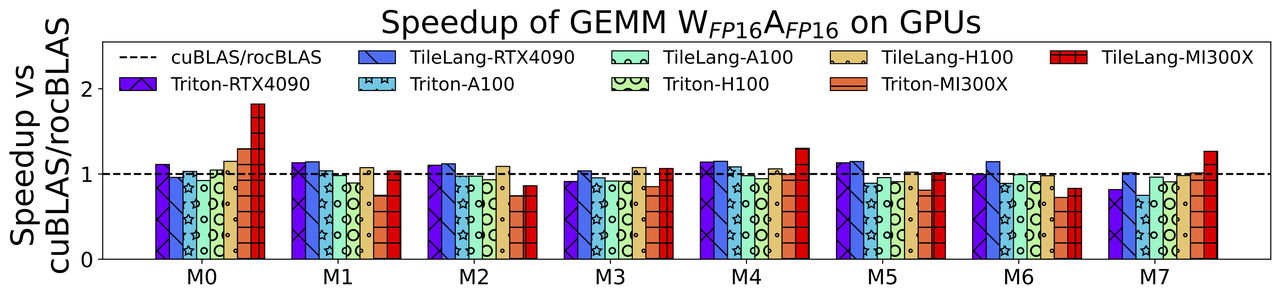
借助 TileLibrary 抽象和线程级元语,TileLang 在确保高性能的同时,简化了 GPU 编程的复杂性。然而,要写出具有竞争力的高性能算子,开发者仍需对 GPU 的硬件特性有深入的理解。TileLibrary 也进一步增强了代码的可移植性,算子层无需关注后端平台,统一的抽象使得编译器可以负责为不同平台生成适当的指令。TileLang 主要依赖于 TVM 框架。虽然 TVM 与 MLIR 框架各有优劣,但总体而言,MLIR 在模块化和可扩展性方面具有更大的优势。因此,当遇到需要扩展的新硬件特性时,新增 op 和优化 pass 的实现可能会面临一定的挑战。
Mojo
Mojo 是 Modular 公司于 2023 年推出的一门新编程语言,旨在为高性能 AI 基础设施与异构硬件(如 CPU、GPU 及各类加速器)提供系统级支持。
作为一门系统级编程语言,Mojo 的定位是与 Python、C++ 和 Rust 等通用语言同级,而不仅仅只是作为Python的eDSL。 它采用了与 Python 类似的语法(如缩进风格、控制流和整体代码结构),降低了 Python 开发者的学习成本。与此同时,Mojo 引入了静态类型、值语义、所有权/借用等机制,旨在解决 Python 在性能上的瓶颈。此外,Mojo 还支持与 Python 的互操作性,开发者可以直接导入并调用大量 Python 库,确保 Mojo 能与现有的 Python AI 和机器学习生态无缝集成。Mojo 的底层构建依赖于MLIR(多层中间表示),这一编译基础设施是现代 AI 基础设施的核心之一。MLIR 擅长处理多层抽象和异构硬件的编译与优化,因此非常适合用于 AI 负载的处理。目前,Mojo 仍在快速发展中,编译器部分仍为闭源,标准库是开源的,未来计划逐步实现更加完整的开源与 Python 超集形态。
Mojo 的一个核心目标是实现 “一套语言覆盖不同硬件”。在针对高性能 GPU 算子编程上:
- 编程模型:Mojo 采用类似 CUDA/HIP 的 SIMT(单指令多线程)范式,基本抽象为“线程/线程块(block)/网格(grid)”。这一模型允许开发者显式控制单个线程的行为、索引计算和并行策略。
- Layout 与数据排布:Mojo 提供了标准库中的 Layout API(如 row_major、column_major 等),并支持用户自定义布局,方便开发者根据内存访问模式进行优化。
- 并行原语
- 块级同步与计算:
- barrier 是一种同步原语,用于线程之间的协调及内存可见性保证。
- sum / max / min / broadcast / prefix_sum 等是块级或 warp 级集体操作,内部自动处理所需的同步。
- warp(线程束)级同步与数据交换:
- warp 内的细粒度同步(即 warp 级协调)。
- warp 内寄存器与寄存器之间的数据交换与 shuffle 操作(如 shuffle_up / shuffle_down / shuffle_xor / shuffle_idx / broadcast 等),用于高效的线程束间通信。
- warp 级归约/扫描操作(如 sum / max / min / prefix_sum),实现高效的局部并行计算。
- 块级同步与计算:
总结:Mojo 为开发者提供了极高的底层控制能力(如类型、内存管理、并行操作、数据排布、warp 级操作等),因此理论上能够实现非常高的性能。在某些 GPU/HPC(高性能计算)负载上,Mojo 有潜力与 CUDA/HIP 竞争。
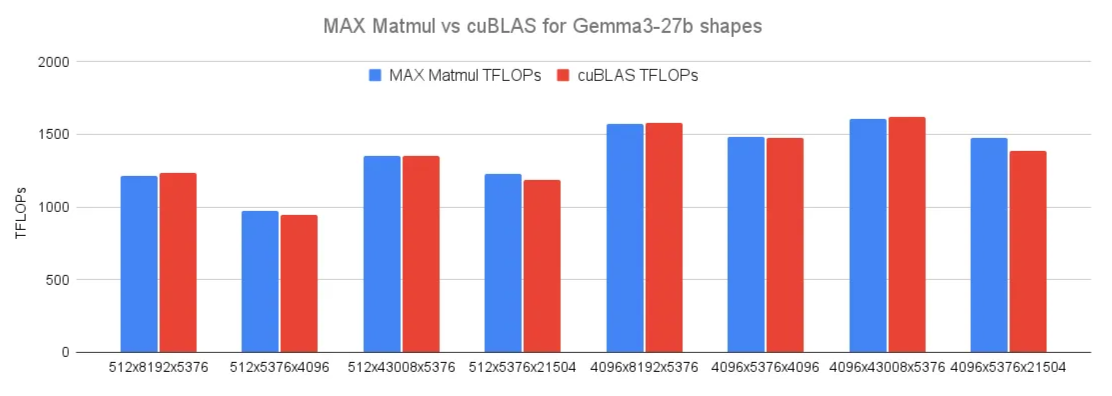
Mojo 的语法对 Python 用户非常友好,提供了丰富的标准库与底层 API。然而,其编译层级几乎对标 CUDA C++,要编写高性能的 GPU 内核,开发者需要比较深入的理解 GPU 微架构、内存层级、SIMT 并行模型,并熟悉相关的底层 API。在可移植性上,Mojo 提供了通用的线程、块、网格抽象及相关 API,这些 API 底层通过 MLIR 接口转为平台相关的接口,从而使得 Mojo 代码能够在不同的 GPU 平台上运行。Mojo 支持与 MLIR 的互操作性。随着新硬件的出现,只要为 MLIR 添加新的方言或操作,Mojo 就能自动获得对这些硬件平台的优化支持。不同方言之间还能无缝转换,使得整个生态系统不断得到扩展与增强。
算子语言 & 算子编译器的发展趋势
当前,算子开发语言(DSL)呈现出百花齐放的局面,涌现了众多创新的语言。然而,未来的算子语言是否会继续保持碎片化,还是最终收敛为一到两种主流语言,目前尚不明朗。但有一点是明确的:算子开发语言必须具备一些关键能力,以适应不断变化的硬件环境和开发需求。
- Python 式的语法,降低开发门槛。Python 已成为 AI 社区的通用语言,因其简洁易懂、库支持丰富,广泛被研究人员和开发者使用。采用 Python 风格的语法设计能够使得开发者快速上手,减少学习新语言的成本。
- 无缝对接上层框架。现代算子语言的一个重要发展趋势是能够直接与上层框架(如 PyTorch)无缝对接。开发者编写的 kernel 可以直接在框架中调用,无需额外的接口封装或转换。这种设计使得模型开发者可以迅速验证算法的实现,同时与框架中的 native 计算进行对比,验证算子输出的正确性,大大提升开发效率。
- 提供多层次抽象,满足不同开发需求。不同类型的开发者有着不同的需求:有的开发者追求快速原型,有的则需要更高性能的算子实现。为了满足这些需求,新的算子语言应该拥有不同的分层抽象体系:
- 高层抽象:屏蔽底层硬件和调度细节,适合快速开发和研究人员使用。
- 中层抽象:允许开发者控制关键性能维度,如并行度和 Tile 配置,适合工程团队进行性能调优。
- 低层抽象:暴露硬件细节,如寄存器、warp 和专用指令,为专家级开发者提供极致的优化空间。
- 面向快速演进的硬件,具备敏捷适配能力 。随着硬件技术的快速发展,新型矩阵指令、异构计算单元等硬件特性不断涌现。新的算子语言需要具备快速吸收硬件新特性的能力,以便在硬件更新后迅速实现优化。例如,Mojo 语言可以通过与 MLIR 的交互性,利用已有的 dialect,在不改变编译器核心的情况下,快速适配和体验新硬件特性。这种灵活性使得开发者能够在不必修改编译器的基础上,充分利用硬件带来的新优势。
Gluon、TileLang、Mojo 等新一代算子 DSL(Domain-Specific Language)迅速涌现,算子开发者如今拥有了前所未有的表达能力。然而,随之而来的一个现实问题也日益突出:算子 DSL 碎片化。不同语言的风格差异、抽象层级不一致,以及对底层硬件的不同感知方式,使得算子代码的复用性显著下降,也增加了长期维护的复杂度。尽管如此,我们既无法、也不应限制开发者选择哪种 DSL——真正可持续的解决方向,是让编译器承担起 “统一抽象、汇聚多语言” 的核心角色。未来的算子编译器需要:
- 兼容多种 DSL 的前端能力:
- 多 DSL 的 AST 级解析:支持 Triton、Mojo、TileLang 等不同风格的算子语言。
- 统一映射到共享 IR(Intermediate Representation):将各类 DSL 的算子表达收敛到统一中间表示层。
- 通用 + 特定平台优化 Pipeline:确保无论采用何种 DSL 编写算子,都能经过一致的优化流程,在不同硬件上发挥稳定性能。
- 面向各类异构同构硬件的自动映射能力。 在统一 IR 基础上,算子编译器能够将同一算子的抽象表达自动编译到多种硬件后端,包括:NVIDIA / AMD GPU,国产 GPGPU,各种 NPU / ASIC, RISC-V DSA 加速器等。这种能力使得算子开发能够逐步实现一次开发,面向不同硬件体系架构自动生成高性能实现。
- 基于MLIR的编译器框架:在今年的 Triton Developer Conference、PyTorch Conference 等技术会议上,除了极少数分享采用 TVM 方案外,绝大多数编译器相关主题均围绕 MLIR(Multi-Level Intermediate Representation) 展开。这一趋势表明,MLIR 已经成为工业界构建 AI 编译器时的主流基础设施。MLIR 的优势主要体现在:
- 多层级 IR 结构天然适配 AI 工作负载:算子优化、图优化、调度优化往往处于不同抽象尺度,而 MLIR 可以用多层级 IR 清晰表示这些结构化信息
- 可扩展 Dialect 体系降低硬件创新门槛:MLIR 支持为不同硬件添加不同的 Dialect,以及转换路线。这使得硬件厂商能更快速地加入生态、构建自己的转换,优化Pipeline。
- 统一 IR 生态推动工具链快速发展:社区围绕 MLIR 构建了丰富的 Pass、优化组件以及下游后端,无需从零设计整套编译基础设施。这种统一生态不仅降低了创新成本,也让算子编译器的能力得以快速迭代和传播。
结语:
从早期的 CUDA,到如今不断涌现的 Triton、TileLang、Mojo等 DSL,算子编程语言正经历一场深层次的结构性重构,这些变化反映了整个 AI 生态对算子库提出的更高要求。模型规模持续扩张、框架抽象层不断提升,硬件体系也呈现出前所未有的多样化,在这样的背景下,作为连接模型与硬件的中间层,算子库的性能已经成为推动 AI 模型加速的关键因素。
算子 DSL 作为描述与实现算子的语言,决定了算子应如何表达、如何在不同硬件上实现高效执行,以及开发者能以何种速度将新的算法想法转化为可验证的高性能实现。因此,它不仅是一种开发工具,更逐渐成为构建未来 AI 计算体系的核心基础设施。可以预见,算子 DSL 将日益成为连接模型、编译器与硬件的公共语言,为生态统一与跨硬件适配提供坚实基础,并推动整个 AI 行业迈向更加开放、高效与协作的新时代。